vLLM $_[$$_{1}$$_,$$_{2}$$_]$ is a fast and easy-to-use library for LLM inference and serving. Originally developed in the Sky Computing Lab at UC Berkeley, vLLM has evolved into a community-driven project with contributions from both academia and industry. $_[$$_{3}$$_]$
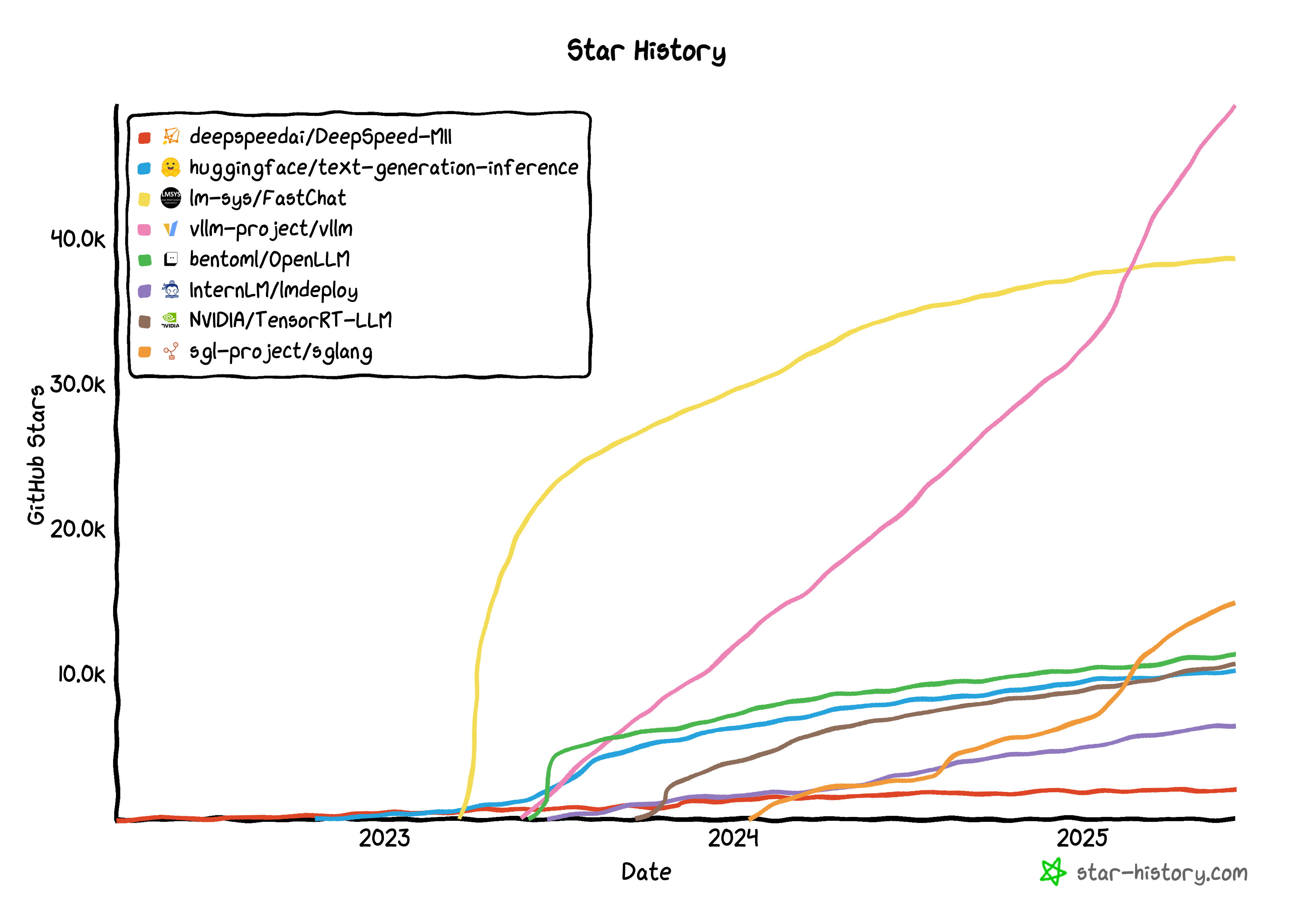
The rapid advancement of Large Language Models (LLMs) has brought efficient model serving and inference optimization to the forefront of MLOps concerns. In response to these challenges, vLLM has emerged as a leading solution, garnering significant attention with 49.2k stars on GitHub as of June 9, 2025. As demonstrated in the star history graph below, vLLM has established itself as the most prominent LLM serving framework among various competing solutions.
A particularly noteworthy aspect is the standardized API interface provided by OpenAI’s GPT series. With countless developers already building applications based on this API specification, ensuring compatibility has become crucial for any LLM serving solution. This article provides a comprehensive analysis of vLLM’s core technological foundations and examines the internal implementation processes that enable OpenAI-compatible server deployment when executing the vllm serve command.
This article is based on vLLM version v0.9.0.1. Implementation details and API specifications may vary in newer versions.
Theoretical Background
PagedAttention
vLLM Blog: vLLM: Easy, Fast, and Cheap LLM Serving with PagedAttention $_[$$_{4}$$_]$
vLLM utilizes PagedAttention, our new attention algorithm that effectively manages attention keys and values. vLLM equipped with PagedAttention redefines the new state of the art in LLM serving: it delivers up to 24x higher throughput than HuggingFace Transformers, without requiring any model architecture changes.
SOSP 2023 (ACM Symposium on Operating Systems Principles): Efficient Memory Management for Large Language Model Serving with PagedAttention $_[$$_{5}$$_]$
PagedAttention divides the request’s KV cache into blocks, each of which can contain the attention keys and values of a fixed number of tokens. In PagedAttention, the blocks for the KV cache are not necessarily stored in contiguous space. Therefore, we can manage the KV cache in a more flexible way as in OS’s virtual memory: one can think of blocks as pages, tokens as bytes, and requests as processes.
Core Concepts and Motivation
PagedAttention represents one of the fundamental technological breakthroughs that distinguishes vLLM from other LLM serving frameworks. This innovative approach addresses the critical memory management challenges inherent in large-scale language model deployment.
Traditional attention mechanisms in transformer models face significant memory inefficiencies when handling variable-length sequences. The primary challenges include:
Memory Fragmentation: Pre-allocated contiguous memory blocks for maximum sequence length
Inefficient Utilization: Wasted memory when actual sequences are shorter than pre-allocated space
Static Batching: Limited flexibility in request batching and scheduling
Poor Scalability: Memory requirements grow quadratically with sequence length
Virtual Memory Paradigm
PagedAttention revolutionizes memory management by implementing a virtual memory system inspired by operating system design principles. The key innovation lies in treating attention computation similarly to how operating systems manage virtual memory:
Bytes → Tokens: Individual tokens within each block
Processes → Requests: Individual inference requests with their own virtual address spaces
Technical Implementation
The conventional approach allocates contiguous memory blocks for each sequence, leading to substantial memory fragmentation and inefficient GPU utilization. PagedAttention breaks this paradigm by:
Block-based Memory Management: Dividing attention computation into fixed-size blocks
Dynamic Memory Allocation: Enabling efficient memory reuse across different requests
Reduced Memory Fragmentation: Minimizing wasted memory through intelligent block allocation
Copy-on-Write Semantics: Sharing identical prefixes across multiple requests
Non-contiguous Storage: Blocks can be stored anywhere in memory, linked through logical addressing
Performance Benefits
PagedAttention delivers remarkable memory efficiency gains, typically achieving 2-4x improvement in memory utilization compared to traditional approaches, directly translating to higher throughput and reduced infrastructure costs. $_[$$_{5}$$_]$
The performance improvements stem from several key optimizations:
Memory Efficiency: Reduced memory footprint through dynamic allocation
Latency Reduction: Faster memory access patterns and reduced copying overhead
Scalability: Linear scaling with hardware resources rather than memory-bound limitations
Comparative Analysis
Aspect
Traditional Attention
PagedAttention
Memory Allocation
Contiguous blocks per sequence
Fixed-size blocks (non-contiguous)
Memory Utilization
Pre-allocated for max sequence length
Dynamic allocation as needed
Memory Fragmentation
High fragmentation when sequences end
Minimal fragmentation through block reuse
Prefix Sharing
Not supported
Efficient sharing of common prefixes
Batch Management
Static batching
Continuous batching with dynamic scheduling
Memory Efficiency
Baseline
2-4x improvement
Throughput
Limited by memory constraints
Up to 24x higher than HuggingFace Transformers
GPU Utilization
Suboptimal due to fragmentation
Optimized through intelligent block allocation
Scalability
Limited by contiguous memory requirements
High scalability with virtual memory approach
Note: A comprehensive mathematical analysis of PagedAttention‘s algorithmic foundations will be covered in an upcoming paper review post, where I’ll dive deeper into the theoretical underpinnings and formal proofs of its efficiency guarantees.
OpenAI-Compatible Server
The OpenAI API has become the de facto standard for LLM interactions, establishing a unified interface that countless applications and services depend upon. $_[$$_{6}$$_]$ vLLM’s OpenAI-compatible server implementation represents a critical bridge between high-performance serving capabilities and industry-standard API compatibility.
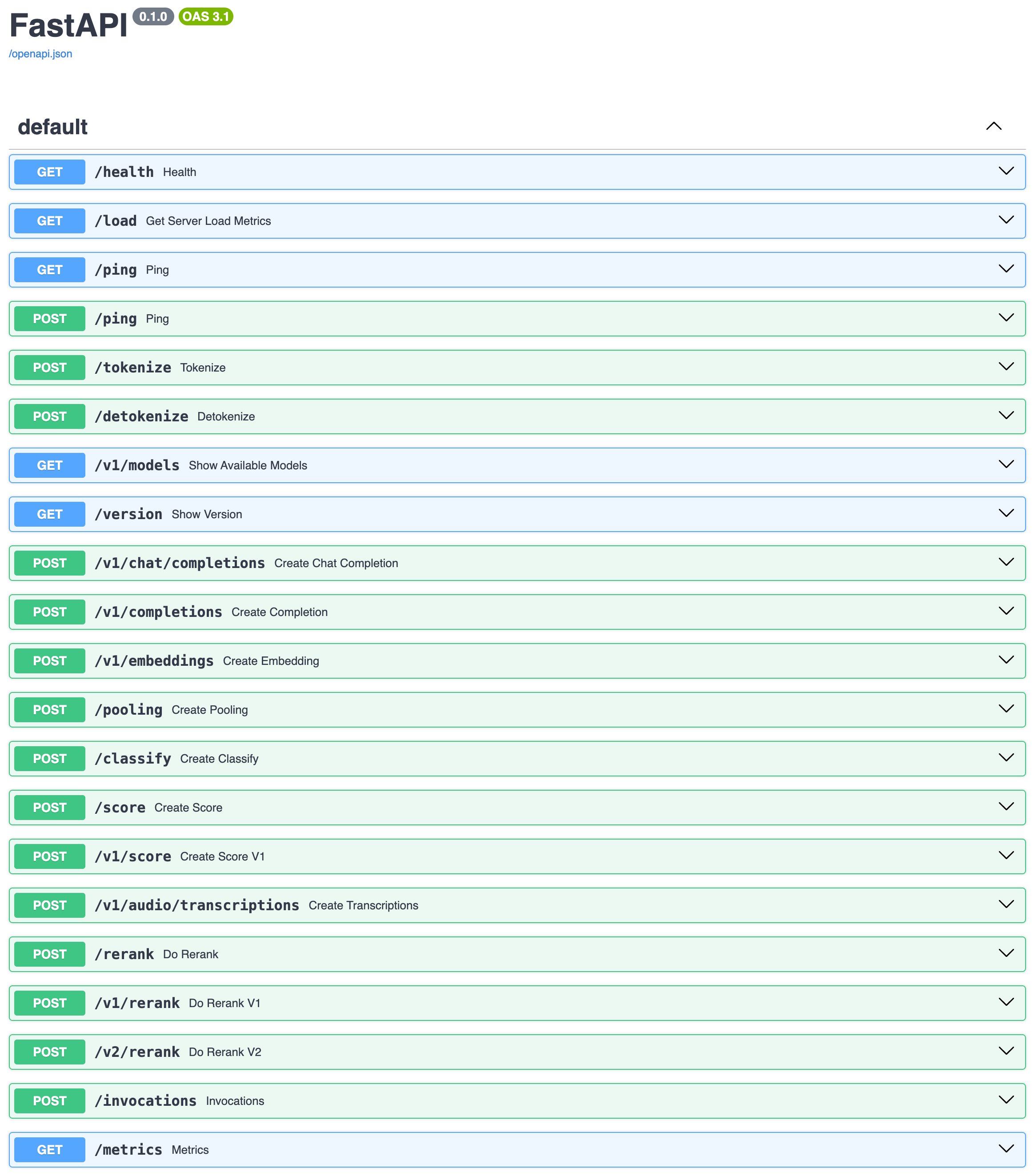
vLLM implements the essential OpenAI API endpoints with full compatibility:
Endpoint
HTTP Method
OpenAI Compatible
Description
/v1/models
GET
✅
List available models
/v1/completions
POST
✅
Text completions for single prompts
/v1/chat/completions
POST
✅
Chat completions with message history
/v1/embeddings
POST
✅
Generate text embeddings
/health
GET
❌
vLLM-specific health check
/tokenize
POST
❌
vLLM-specific tokenization
/detokenize
POST
❌
vLLM-specific detokenization
/metrics
GET
❌
Prometheus-compatible metrics
Hands-On
This section demonstrates how to deploy and interact with vLLM’s OpenAI-compatible server in practice. I’ll walk through the installation process, server startup, and explore the automatically generated API documentation.
Installation
vLLM can be installed with different backend configurations depending on your hardware setup $_[$$_{7}$$_]$:
$ vllm serve Qwen/Qwen3-0.6B --max-model-len 8192 ... INFO 06-09 23:16:17 [api_server.py:1336] Starting vLLM API server on http://0.0.0.0:8000 INFO 06-09 23:16:17 [launcher.py:28] Available routes are: INFO 06-09 23:16:17 [launcher.py:36] Route: /openapi.json, Methods: GET, v0.9.0.1 INFO 06-09 23:16:17 [launcher.py:36] Route: /docs, Methods: GET, v0.9.0.1 INFO 06-09 23:16:17 [launcher.py:36] Route: /docs/oauth2-redirect, Methods: GET, v0.9.0.1 INFO 06-09 23:16:17 [launcher.py:36] Route: /redoc, Methods: GET, v0.9.0.1 INFO 06-09 23:16:17 [launcher.py:36] Route: /health, Methods: GET INFO 06-09 23:16:17 [launcher.py:36] Route: /load, Methods: GET INFO 06-09 23:16:17 [launcher.py:36] Route: /ping, Methods: POST INFO 06-09 23:16:17 [launcher.py:36] Route: /ping, Methods: GET INFO 06-09 23:16:17 [launcher.py:36] Route: /tokenize, Methods: POST INFO 06-09 23:16:17 [launcher.py:36] Route: /detokenize, Methods: POST INFO 06-09 23:16:17 [launcher.py:36] Route: /v1/models, Methods: GET INFO 06-09 23:16:17 [launcher.py:36] Route: /version, Methods: GET INFO 06-09 23:16:17 [launcher.py:36] Route: /v1/chat/completions, Methods: POST INFO 06-09 23:16:17 [launcher.py:36] Route: /v1/completions, Methods: POST INFO 06-09 23:16:17 [launcher.py:36] Route: /v1/embeddings, Methods: POST INFO 06-09 23:16:17 [launcher.py:36] Route: /pooling, Methods: POST INFO 06-09 23:16:17 [launcher.py:36] Route: /classify, Methods: POST INFO 06-09 23:16:17 [launcher.py:36] Route: /score, Methods: POST INFO 06-09 23:16:17 [launcher.py:36] Route: /v1/score, Methods: POST INFO 06-09 23:16:17 [launcher.py:36] Route: /v1/audio/transcriptions, Methods: POST INFO 06-09 23:16:17 [launcher.py:36] Route: /rerank, Methods: POST INFO 06-09 23:16:17 [launcher.py:36] Route: /v1/rerank, Methods: POST INFO 06-09 23:16:17 [launcher.py:36] Route: /v2/rerank, Methods: POST INFO 06-09 23:16:17 [launcher.py:36] Route: /invocations, Methods: POST INFO 06-09 23:16:17 [launcher.py:36] Route: /metrics, Methods: GET INFO: Started server process [16355] INFO: Waiting for application startup. INFO: Application startup complete.
Interactive API Documentation
vLLM automatically generates interactive API documentation accessible via Swagger UI:
The Swagger interface provides:
Interactive Testing: Direct API endpoint testing from the browser
Parameter Validation: Real-time parameter validation and examples
Authentication Setup: Easy API key configuration for testing
Practical API Usage Examples
Once the server is running, you can interact with it using standard OpenAI-compatible clients:
1 2 3 4 5 6
>>> import openai >>> client = openai.OpenAI(base_url="http://localhost:8000/v1") >>> client.models.list() SyncPage[Model](data=[Model(id='Qwen/Qwen3-0.6B', created=1749651810, object='model', owned_by='vllm', root='Qwen/Qwen3-0.6B', parent=None, max_model_len=8192, permission=[{'id': 'modelperm-8bc1b4000ad84fac81f2de0addc81ef6', 'object': 'model_permission', 'created': 1749651810, 'allow_create_engine': False, 'allow_sampling': True, 'allow_logprobs': True, 'allow_search_indices': False, 'allow_view': True, 'allow_fine_tuning': False, 'organization': '*', 'group': None, 'is_blocking': False}])], object='list') >>> client.chat.completions.create(model="Qwen/Qwen3-0.6B", messages=[{"role": "user", "content": "Hello, vLLM!"}]) ChatCompletion(id='chatcmpl-d4ecd72df87c4b13a8b9d47ddcb75ccc', choices=[Choice(finish_reason='stop', index=0, logprobs=None, message=ChatCompletionMessage(content='<think>\nOkay, the user just said "Hello, vLLM!" so I need to respond in a friendly and helpful way. Let me start by acknowledging their greeting. Maybe say something like "Hello! How can I assist you today?" to show I\'m here to help. I should keep the tone positive and open-ended so they can ask more questions. Let me check if there\'s anything else they might need, like setup instructions or support. I\'ll make sure to offer assistance in both technical and general ways. Alright, that should cover it.\n</think>\n\nHello! How can I assist you today? 😊', refusal=None, role='assistant', annotations=None, audio=None, function_call=None, tool_calls=[], reasoning_content=None), stop_reason=None)], created=1749651812, model='Qwen/Qwen3-0.6B', object='chat.completion', service_tier=None, system_fingerprint=None, usage=CompletionUsage(completion_tokens=126, prompt_tokens=14, total_tokens=140, completion_tokens_details=None, prompt_tokens_details=None), prompt_logprobs=None, kv_transfer_params=None)
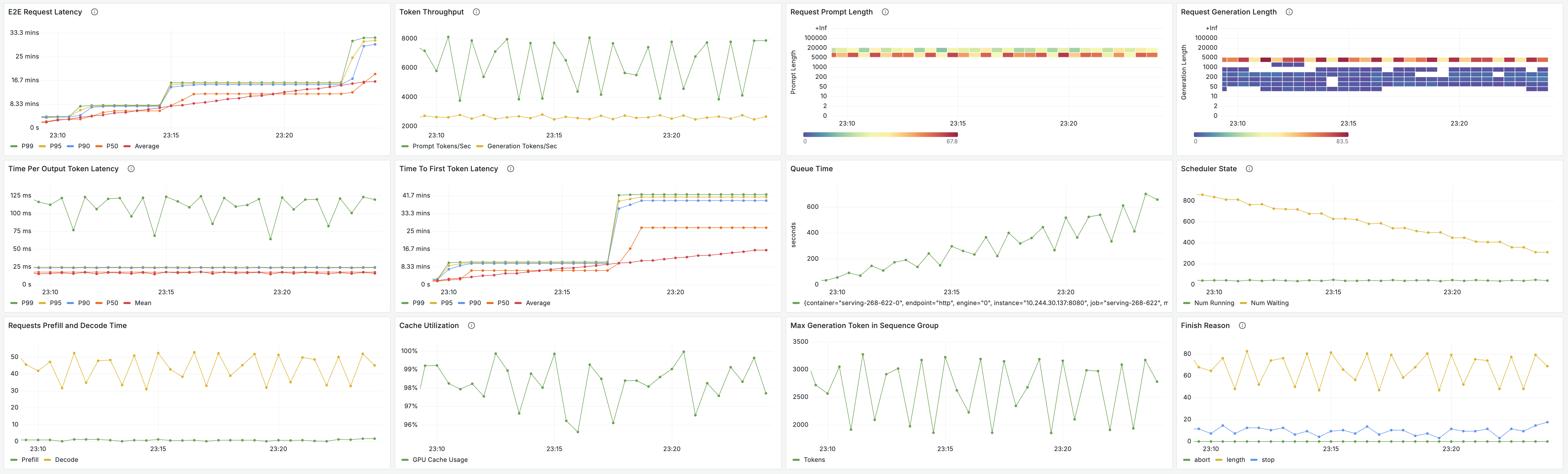
Monitoring and Metrics
vLLM supports Prometheus-based metrics collection through the /metrics endpoint. $_[$$_{9}$$_,$$_{10}$$_]$ This enables real-time monitoring through Grafana dashboards. $_[$$_{11}$$_,$$_{12}$$_]$
1 2 3 4 5 6 7 8
$ curl http://localhost:8000/metrics # HELP vllm:num_preemptions_total Cumulative number of preemption from the engine. # TYPE vllm:num_preemptions_total counter vllm:num_preemptions_total{model_name="Qwen/Qwen3-0.6B"} 0.0 # HELP vllm:prompt_tokens_total Number of prefill tokens processed. # TYPE vllm:prompt_tokens_total counter vllm:prompt_tokens_total{model_name="Qwen/Qwen3-0.6B"} 28.0 ...
Server Initialization
This section reviews the entire process from when a user starts an OpenAI-compatible server through vllm serve until the server reaches its ready state.
CLI
When the vllm serve command is executed in the terminal, it runs the main() function from vllm/entrypoints/cli/main.py through the vllm command defined in the project.scripts section of pyproject.toml.
Subsequently, the main() function recognizes the serve command through the subparser and executes the dispatch_function, which is the ServeSubcommand.cmd() function.
The user-specified args are then passed to the run_server() function, and the OpenAI-compatible server begins operation through the uvloop.run() function.
vllm/entrypoints/cli/serve.pylink
1 2 3 4 5 6 7 8 9 10 11 12 13 14
... classServeSubcommand(CLISubcommand): ... @staticmethod defcmd(args: argparse.Namespace) -> None: # If model is specified in CLI (as positional arg), it takes precedence ifhasattr(args, 'model_tag') and args.model_tag isnotNone: args.model = args.model_tag
if args.headless: run_headless(args) else: uvloop.run(run_server(args)) ...
Engine
Client
For resource lifecycle management, the engine_client is created with async with.
# Context manager to handle engine_client lifecycle # Ensures everything is shutdown and cleaned up on error/exit engine_args = AsyncEngineArgs.from_cli_args(args)
asyncwith build_async_engine_client_from_engine_args( engine_args, args.disable_frontend_multiprocessing) as engine: yield engine ...
... @asynccontextmanager asyncdefbuild_async_engine_client_from_engine_args( engine_args: AsyncEngineArgs, disable_frontend_multiprocessing: bool = False, ) -> AsyncIterator[EngineClient]: """ Create EngineClient, either: - in-process using the AsyncLLMEngine Directly - multiprocess using AsyncLLMEngine RPC Returns the Client or None if the creation failed. """
# Create the EngineConfig (determines if we can use V1). usage_context = UsageContext.OPENAI_API_SERVER vllm_config = engine_args.create_engine_config(usage_context=usage_context)
# V1 AsyncLLM. if envs.VLLM_USE_V1: if disable_frontend_multiprocessing: logger.warning( "V1 is enabled, but got --disable-frontend-multiprocessing. " "To disable frontend multiprocessing, set VLLM_USE_V1=0.")
... classMPClient(EngineCoreClient): ... def__init__( self, asyncio_mode: bool, vllm_config: VllmConfig, executor_class: type[Executor], log_stats: bool, ): ... # Start local engines. if local_engine_count: # In server mode, start_index and local_start_index will # both be 0. self.resources.local_engine_manager = CoreEngineProcManager( EngineCoreProc.run_engine_core, vllm_config=vllm_config, executor_class=executor_class, log_stats=log_stats, input_address=input_address, on_head_node=True, local_engine_count=local_engine_count, start_index=start_index, local_start_index=local_start_index) ...
The AsyncMPClient manages the core engine process through CoreEngineProcManager and communicates using ZMQ IPC socket. The actual core engine runs as a separate background process for improved isolation and performance.
Core
The core engine is created as a background process as shown below. I will examine its detailed operation in the next article.
... classExecutor(ExecutorBase): """ Abstract class for v1 executors, mainly define some methods for v1. For methods shared by v0 and v1, define them in ExecutorBase"""
@staticmethod defget_class(vllm_config: VllmConfig) -> type["Executor"]: executor_class: type[Executor] parallel_config = vllm_config.parallel_config distributed_executor_backend = ( parallel_config.distributed_executor_backend) # distributed_executor_backend must be set in VllmConfig.__post_init__ ifisinstance(distributed_executor_backend, type): ifnotissubclass(distributed_executor_backend, ExecutorBase): raise TypeError( "distributed_executor_backend must be a subclass of " f"ExecutorBase. Got {distributed_executor_backend}.") executor_class = distributed_executor_backend elif distributed_executor_backend == "ray": from vllm.v1.executor.ray_distributed_executor import ( # noqa RayDistributedExecutor) executor_class = RayDistributedExecutor elif distributed_executor_backend == "mp": from vllm.v1.executor.multiproc_executor import MultiprocExecutor executor_class = MultiprocExecutor elif distributed_executor_backend == "uni": executor_class = UniProcExecutor elif distributed_executor_backend == "external_launcher": # TODO: make v1 scheduling deterministic # to support external launcher executor_class = ExecutorWithExternalLauncher else: raise ValueError("Unknown distributed executor backend: " f"{distributed_executor_backend}") return executor_class ...
The executor configuration is accomplished through the following process.
The system automatically selects the appropriate distributed backend based on the hardware configuration and execution environment. Key decision factors include:
Single Node vs Multi-Node: Determines whether to use multiprocessing (mp) or Ray (ray) backend
GPU Availability: Checks CUDA device count against world size requirements
Ray Environment: Detects existing Ray initialization and placement groups
Platform-Specific: Special handling for Neuron devices using unified process (uni) backend
The configuration logic ensures optimal resource utilization while maintaining compatibility across different deployment scenarios.
... @config @dataclass classParallelConfig: ... def__post_init__(self) -> None: ... ifself.distributed_executor_backend isNoneandself.world_size > 1: # We use multiprocessing by default if world_size fits on the # current node and we aren't in a ray placement group.
from vllm.executor import ray_utils backend: DistributedExecutorBackend = "mp" ray_found = ray_utils.ray_is_available() if current_platform.is_neuron(): # neuron uses single process to control multiple devices backend = "uni" elif (current_platform.is_cuda() and cuda_device_count_stateless() < self.world_size): ifnot ray_found: raise ValueError("Unable to load Ray which is " "required for multi-node inference, " "please install Ray with `pip install " "ray`.") from ray_utils.ray_import_err backend = "ray" elif ray_found: ifself.placement_group: backend = "ray" else: from ray import is_initialized as ray_is_initialized if ray_is_initialized(): from ray.util import get_current_placement_group if get_current_placement_group(): backend = "ray" self.distributed_executor_backend = backend logger.info("Defaulting to use %s for distributed inference", backend)
In this article, I will not consider tensor parallel plus pipeline parallel inference $_[$$_{13}$$_,$$_{14}$$_]$. Therefore, I’ll analyze the UniProcExecutor.
The UniProcExecutor is designed for single-process execution scenarios where all model computation happens within a single process. This is the default choice for single-GPU deployments or when distributed execution is not required.
Key characteristics of UniProcExecutor:
Single Process: All computation occurs within one process
Direct Communication: No inter-process communication overhead
Simplified Architecture: Straightforward execution path without distributed coordination
Resource Efficiency: Minimal overhead for single-device scenarios
The _init_executor() method initializes the worker and sets up the execution environment. The rpc_rank parameter represents the rank of the worker in the executor context, which is typically 0 for single-process execution.
The UniProcExecutor.driver_worker is defined as the WorkerWrapperBase class as shown below, and the WorkerWrapperBase operates through the collective_rpc method of UniProcExecutor.
... classWorkerWrapperBase: """ This class represents one process in an executor/engine. It is responsible for lazily initializing the worker and handling the worker's lifecycle. We first instantiate the WorkerWrapper, which remembers the worker module and class name. Then, when we call `update_environment_variables`, and the real initialization happens in `init_worker`. """
def__init__( self, vllm_config: VllmConfig, rpc_rank: int = 0, ) -> None: """ Initialize the worker wrapper with the given vllm_config and rpc_rank. Note: rpc_rank is the rank of the worker in the executor. In most cases, it is also the rank of the worker in the distributed group. However, when multiple executors work together, they can be different. e.g. in the case of SPMD-style offline inference with TP=2, users can launch 2 engines/executors, each with only 1 worker. All workers have rpc_rank=0, but they have different ranks in the TP group. """ self.rpc_rank = rpc_rank self.worker: Optional[WorkerBase] = None # do not store this `vllm_config`, `init_worker` will set the final # one. TODO: investigate if we can remove this field in # `WorkerWrapperBase`, `init_cached_hf_modules` should be # unnecessary now. if vllm_config.model_config isnotNone: # it can be None in tests trust_remote_code = vllm_config.model_config.trust_remote_code if trust_remote_code: # note: lazy import to avoid importing torch before initializing from vllm.utils import init_cached_hf_modules init_cached_hf_modules() ...
The WorkerWrapperBase.worker is initialized by the UniProcExecutor.collective_rpc("init_worker", args=([kwargs], )) call executed in the UniProcExecutor._init_executor() method.
... classWorkerWrapperBase: ... definit_worker(self, all_kwargs: List[Dict[str, Any]]) -> None: """ Here we inject some common logic before initializing the worker. Arguments are passed to the worker class constructor. """ kwargs = all_kwargs[self.rpc_rank] self.vllm_config = kwargs.get("vllm_config", None) ... ifisinstance(self.vllm_config.parallel_config.worker_cls, str): worker_class = resolve_obj_by_qualname( self.vllm_config.parallel_config.worker_cls) ... with set_current_vllm_config(self.vllm_config): # To make vLLM config available during worker initialization self.worker = worker_class(**kwargs) assertself.worker isnotNone ...
The worker to be used varies depending on the execution environment and configuration. In CUDA environments, it is configured as follows. For the V1 engine, vllm.v1.worker.gpu_worker.Worker is used.
After worker creation, the device is initialized as shown below through UniProcExecutor.collective_rpc("init_device"). (The following is based on CUDA environment worker)
... classWorker(WorkerBase): ... definit_device(self): ifself.device_config.device.type == "cuda": # torch.distributed.all_reduce does not free the input tensor until # the synchronization point. This causes the memory usage to grow # as the number of all_reduce calls increases. This env var disables # this behavior. # Related issue: # https://discuss.pytorch.org/t/cuda-allocation-lifetime-for-inputs-to-distributed-all-reduce/191573 os.environ["TORCH_NCCL_AVOID_RECORD_STREAMS"] = "1"
# This env var set by Ray causes exceptions with graph building. os.environ.pop("NCCL_ASYNC_ERROR_HANDLING", None) self.device = torch.device(f"cuda:{self.local_rank}") torch.cuda.set_device(self.device)
_check_if_gpu_supports_dtype(self.model_config.dtype) gc.collect() torch.cuda.empty_cache() self.init_gpu_memory = torch.cuda.mem_get_info()[0] else: raise RuntimeError( f"Not support device type: {self.device_config.device}") # Initialize the distributed environment. init_worker_distributed_environment(self.vllm_config, self.rank, self.distributed_init_method, self.local_rank) # Set random seed. set_random_seed(self.model_config.seed)
# Construct the model runner self.model_runner: GPUModelRunner = GPUModelRunner( self.vllm_config, self.device)
ifself.rank == 0: # If usage stat is enabled, collect relevant info. report_usage_stats(self.vllm_config) ...
During the above process, Worker.model_runner is created.
Model Runner
Once the device is ready, the model is loaded through UniProcExecutor.collective_rpc("load_model"), and the model is loaded through the model runner.
vllm/v1/worker/gpu_worker.pylink
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
... classWorker(WorkerBase): ... defload_model(self) -> None: ifself.vllm_config.model_config.enable_sleep_mode: allocator = CuMemAllocator.get_instance() assert allocator.get_current_usage() == 0, ( "Sleep mode can only be " "used for one instance per process.") context = allocator.use_memory_pool(tag="weights") else: from contextlib import nullcontext context = nullcontext() with context: self.model_runner.load_model() ...
The GPUModelRunner downloads and loads the model through the get_model() function.
vllm/v1/worker/gpu_model_runner.pylink
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
... classGPUModelRunner(LoRAModelRunnerMixin): ... defload_model(self) -> None: logger.info("Starting to load model %s...", self.model_config.model) with DeviceMemoryProfiler() as m: # noqa: SIM117 time_before_load = time.perf_counter() self.model = get_model(vllm_config=self.vllm_config) ifself.lora_config: self.model = self.load_lora_model(self.model, self.model_config, self.scheduler_config, self.lora_config, self.device) ...
The get_model() function determines the loader based on the user-provided config and returns it in the form of torch.nn.Module.
... defget_model_loader(load_config: LoadConfig) -> BaseModelLoader: """Get a model loader based on the load format.""" ifisinstance(load_config.load_format, type): return load_config.load_format(load_config)
if load_config.load_format == LoadFormat.DUMMY: return DummyModelLoader(load_config)
if load_config.load_format == LoadFormat.TENSORIZER: return TensorizerLoader(load_config)
if load_config.load_format == LoadFormat.SHARDED_STATE: return ShardedStateLoader(load_config)
if load_config.load_format == LoadFormat.BITSANDBYTES: return BitsAndBytesModelLoader(load_config)
if load_config.load_format == LoadFormat.GGUF: return GGUFModelLoader(load_config)
if load_config.load_format == LoadFormat.RUNAI_STREAMER: return RunaiModelStreamerLoader(load_config)
if load_config.load_format == LoadFormat.RUNAI_STREAMER_SHARDED: return ShardedStateLoader(load_config, runai_model_streamer=True)
def_listen_addr(a: str) -> str: if is_valid_ipv6_address(a): return'[' + a + ']' return a or"0.0.0.0"
is_ssl = args.ssl_keyfile and args.ssl_certfile logger.info("Starting vLLM API server on http%s://%s:%d", "s"if is_ssl else"", _listen_addr(sock_addr[0]), sock_addr[1])
shutdown_task = await serve_http( app, sock=sock, enable_ssl_refresh=args.enable_ssl_refresh, host=args.host, port=args.port, log_level=args.uvicorn_log_level, # NOTE: When the 'disable_uvicorn_access_log' value is True, # no access log will be output. access_log=not args.disable_uvicorn_access_log, timeout_keep_alive=TIMEOUT_KEEP_ALIVE, ssl_keyfile=args.ssl_keyfile, ssl_certfile=args.ssl_certfile, ssl_ca_certs=args.ssl_ca_certs, ssl_cert_reqs=args.ssl_cert_reqs, **uvicorn_kwargs, ) ...
@router.get("/server_info") asyncdefshow_server_info(raw_request: Request): ... @router.post("/reset_prefix_cache") asyncdefreset_prefix_cache(raw_request: Request): ... @router.post("/sleep") asyncdefsleep(raw_request: Request): ... @router.post("/wake_up") asyncdefwake_up(raw_request: Request): ... @router.get("/is_sleeping") asyncdefis_sleeping(raw_request: Request): ... @router.post("/invocations", dependencies=[Depends(validate_json_request)], responses={ HTTPStatus.BAD_REQUEST.value: { "model": ErrorResponse }, HTTPStatus.UNSUPPORTED_MEDIA_TYPE.value: { "model": ErrorResponse }, HTTPStatus.INTERNAL_SERVER_ERROR.value: { "model": ErrorResponse }, }) asyncdefinvocations(raw_request: Request): ... if envs.VLLM_TORCH_PROFILER_DIR: logger.warning( "Torch Profiler is enabled in the API server. This should ONLY be " "used for local development!")
@router.post("/start_profile") asyncdefstart_profile(raw_request: Request): ... @router.post("/start_profile") asyncdefstart_profile(raw_request: Request): ... @router.post("/stop_profile") asyncdefstop_profile(raw_request: Request): ... if envs.VLLM_ALLOW_RUNTIME_LORA_UPDATING: logger.warning( "LoRA dynamic loading & unloading is enabled in the API server. " "This should ONLY be used for local development!")
flowchart TD
User
subgraph Command Line Interface
vs["vllm serve ${MODEL_NAME}"]
end
subgraph vLLM Package
pyproject["vllm = "vllm.entrypoints.cli.main:main""]
cli_main["vllm.entrypoints.cli.main.main()"]
subgraph Parser
arg["vllm.engine.arg_utils.EngineArgs"]
aarg["vllm.engine.arg_utils.AsyncEngineArgs"]
end
subgraph Config
cfg["vllm.config.VllmConfig"]
end
subgraph Engine Client
ssc["vllm.entrypoints.cli.serve.ServeSubCommand.cmd()"]
alc["vllm.v1.engine.async_llm.AsyncLLM"]
amc["vllm.v1.engine.core_client.AsyncMPClient"]
cepm["vllm.v1.utils.CoreEngineProcManager"]
end
subgraph Engine Core
ecp["vllm.v1.engine.core.EngineCoreProc"]
end
subgraph Executor
exe["vllm.v1.executor.abstract.Executor.get_class()"]
uni["vllm.executor.uniproc_executor.UniProcExecutor"]
end
subgraph Worker
ww["vllm.worker.worker_base.WorkerWrapperBase"]
wo["vllm.v1.worker.gpu_worker.Worker"]
end
subgraph Model Runner
mr["vllm.v1.worker.gpu_model_runner.GPUModelRunner"]
end
end
User-->vs-->pyproject-->cli_main-->ssc-->alc-->amc-->cepm-.->ecp-->uni
cfg-->arg
cfg-->aarg-->ww
cli_main-->arg-->aarg-->ssc
alc-->exe-->uni-->ww-->wo-->mr
classDef userClass fill:#e1f5fe
classDef engineClass fill:#f3e5f5
classDef workerClass fill:#e8f5e8
class User userClass
class alc,amc,cepm,ecp engineClass
class uni,ww,wo,mr workerClass
Etc
Parser
The ServeSubcommand, which inherits from CLISubcommand, parses the configuration values required for the OpenAI-compatible server.
entrypoints/cli/main.pylink
1 2 3 4 5 6 7 8 9 10
... defmain(): ... for cmd_module in CMD_MODULES: new_cmds = cmd_module.cmd_init() for cmd in new_cmds: cmd.subparser_init(subparsers).set_defaults( dispatch_function=cmd.cmd) cmds[cmd.name] = cmd ...
vllm/entrypoints/cli/serve.pylink
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17
... classServeSubcommand(CLISubcommand): """The `serve` subcommand for the vLLM CLI. """ ... defsubparser_init( self, subparsers: argparse._SubParsersAction) -> FlexibleArgumentParser: serve_parser = subparsers.add_parser( "serve", help="Start the vLLM OpenAI Compatible API server.", description="Start the vLLM OpenAI Compatible API server.", usage="vllm serve [model_tag] [options]") ... serve_parser = make_arg_parser(serve_parser) show_filtered_argument_or_group_from_help(serve_parser) serve_parser.epilog = VLLM_SERVE_PARSER_EPILOG return serve_parser
Configuration values related to the engine, which plays a crucial role in inference, are added through the add_cli_args() method of AsyncEngineArgs.
@staticmethod defadd_cli_args(parser: FlexibleArgumentParser, async_args_only: bool = False) -> FlexibleArgumentParser: # Initialize plugin to update the parser, for example, The plugin may # adding a new kind of quantization method to --quantization argument or # a new device to --device argument. load_general_plugins() ifnot async_args_only: parser = EngineArgs.add_cli_args(parser) ... from vllm.platforms import current_platform current_platform.pre_register_and_update(parser) return parser ...
Configuration values required for the engine are defined in the code lines below, with default values defined in vllm/configs.py.
... @config @dataclass classModelConfig: """Configuration for the model.""" ... @config @dataclass classCacheConfig: """Configuration for the KV cache.""" ... @config @dataclass classTokenizerPoolConfig: """This config is deprecated and will be removed in a future release. Passing these parameters will have no effect. Please remove them from your configurations. """ ... @config @dataclass classLoadConfig: """Configuration for loading the model weights.""" ... @config @dataclass classParallelConfig: """Configuration for the distributed execution.""" ... @config @dataclass classSchedulerConfig: """Scheduler configuration.""" ... @config @dataclass classDeviceConfig: """Configuration for the device to use for vLLM execution.""" ... @config @dataclass classSpeculativeConfig: """Configuration for speculative decoding.""" ... @config @dataclass classLoRAConfig: """Configuration for LoRA.""" ... @config @dataclass classPromptAdapterConfig: """Configuration for PromptAdapters.""" ... @config @dataclass classMultiModalConfig: """Controls the behavior of multimodal models.""" ... @config @dataclass classPoolerConfig: """Controls the behavior of output pooling in pooling models.""" ... @config @dataclass classDecodingConfig: """Dataclass which contains the decoding strategy of the engine.""" ... @config @dataclass classObservabilityConfig: """Configuration for observability - metrics and tracing.""" ... @config @dataclass classKVTransferConfig: """Configuration for distributed KV cache transfer.""" ... @config @dataclass classKVEventsConfig: """Configuration for KV event publishing.""" ... @config @dataclass classPassConfig: """Configuration for custom Inductor passes. This is separate from general `CompilationConfig` so that inductor passes don't all have access to full configuration - that would create a cycle as the `PassManager` is set as a property of config.""" ... @config @dataclass classCompilationConfig: """Configuration for compilation. It has three parts: - Top-level Compilation control: - [`level`][vllm.config.CompilationConfig.level] - [`debug_dump_path`][vllm.config.CompilationConfig.debug_dump_path] - [`cache_dir`][vllm.config.CompilationConfig.cache_dir] - [`backend`][vllm.config.CompilationConfig.backend] - [`custom_ops`][vllm.config.CompilationConfig.custom_ops] - [`splitting_ops`][vllm.config.CompilationConfig.splitting_ops] - CudaGraph capture: - [`use_cudagraph`][vllm.config.CompilationConfig.use_cudagraph] - [`cudagraph_capture_sizes`] [vllm.config.CompilationConfig.cudagraph_capture_sizes] - [`cudagraph_num_of_warmups`] [vllm.config.CompilationConfig.cudagraph_num_of_warmups] - [`cudagraph_copy_inputs`] [vllm.config.CompilationConfig.cudagraph_copy_inputs] - [`full_cuda_graph`][vllm.config.CompilationConfig.full_cuda_graph] - Inductor compilation: - [`use_inductor`][vllm.config.CompilationConfig.use_inductor] - [`compile_sizes`][vllm.config.CompilationConfig.compile_sizes] - [`inductor_compile_config`] [vllm.config.CompilationConfig.inductor_compile_config] - [`inductor_passes`][vllm.config.CompilationConfig.inductor_passes] - custom inductor passes Why we have different sizes for cudagraph and inductor: - cudagraph: a cudagraph captured for a specific size can only be used for the same size. We need to capture all the sizes we want to use. - inductor: a graph compiled by inductor for a general shape can be used for different sizes. Inductor can also compile for specific sizes, where it can have more information to optimize the graph with fully static shapes. However, we find the general shape compilation is sufficient for most cases. It might be beneficial to compile for certain small batchsizes, where inductor is good at optimizing. """ ... @config @dataclass classVllmConfig: """Dataclass which contains all vllm-related configuration. This simplifies passing around the distinct configurations in the codebase. """ ...
Conclusion
In this article, I explored what happens behind the scenes when executing the vllm serve command. Starting from PagedAttention’s innovative memory management approach, I examined the server initialization process and the roles of each component.
Key components and their roles:
Engine Client: Manages the engine lifecycle and coordinates communication with core engine processes for request handling.
Core Engine: Receives incoming requests, manages scheduling queues, handles tokenization, orchestrates model execution (including distributed scenarios), and processes outputs.
Executor: Determines the optimal execution strategy (single-process vs. distributed with tensor/pipeline parallelism) and creates multiple worker processes as needed.
Worker: Individual process assigned to a specific device (e.g., GPU) that handles device initialization and executes model inference tasks.
Model Runner: Loads the model weights, prepares input tensors for computation, and executes the core model inference logic.
Model: The actual torch.nn.Module instance containing the loaded language model weights and architecture.
FastAPI Server: Exposes OpenAI-compatible REST API endpoints for client interactions, built on the FastAPI framework.
vLLM’s core strengths lie in memory efficiency through PagedAttention, scalability through modular architecture, and perfect compatibility with OpenAI APIs.
In the next article, I will focus on the actual inference process, exploring how user requests are processed, queued, batched, and executed through the /v1/chat/completions endpoint.