
Harnessing The ML Backends for Efficient Labeling in Label Studio
Introduction
Open source data labeling platform Label Studio에 Label Studio ML Backend의 도입으로 machine learning model을 통합하고 labeling 작업을 위한 자동화된 예측을 제공할 수 있다.
이를 통해 labeling process를 가속화하고 일관성과 정확성을 향상시킬 수 있으며 실시간으로 모델의 성능을 평가하고 빠르게 반복함으로써 model을 지속적으로 개선할 수 있다.
Label Studio와 Label Studio ML Backend의 작동 방식은 아래와 같이 구성된다.
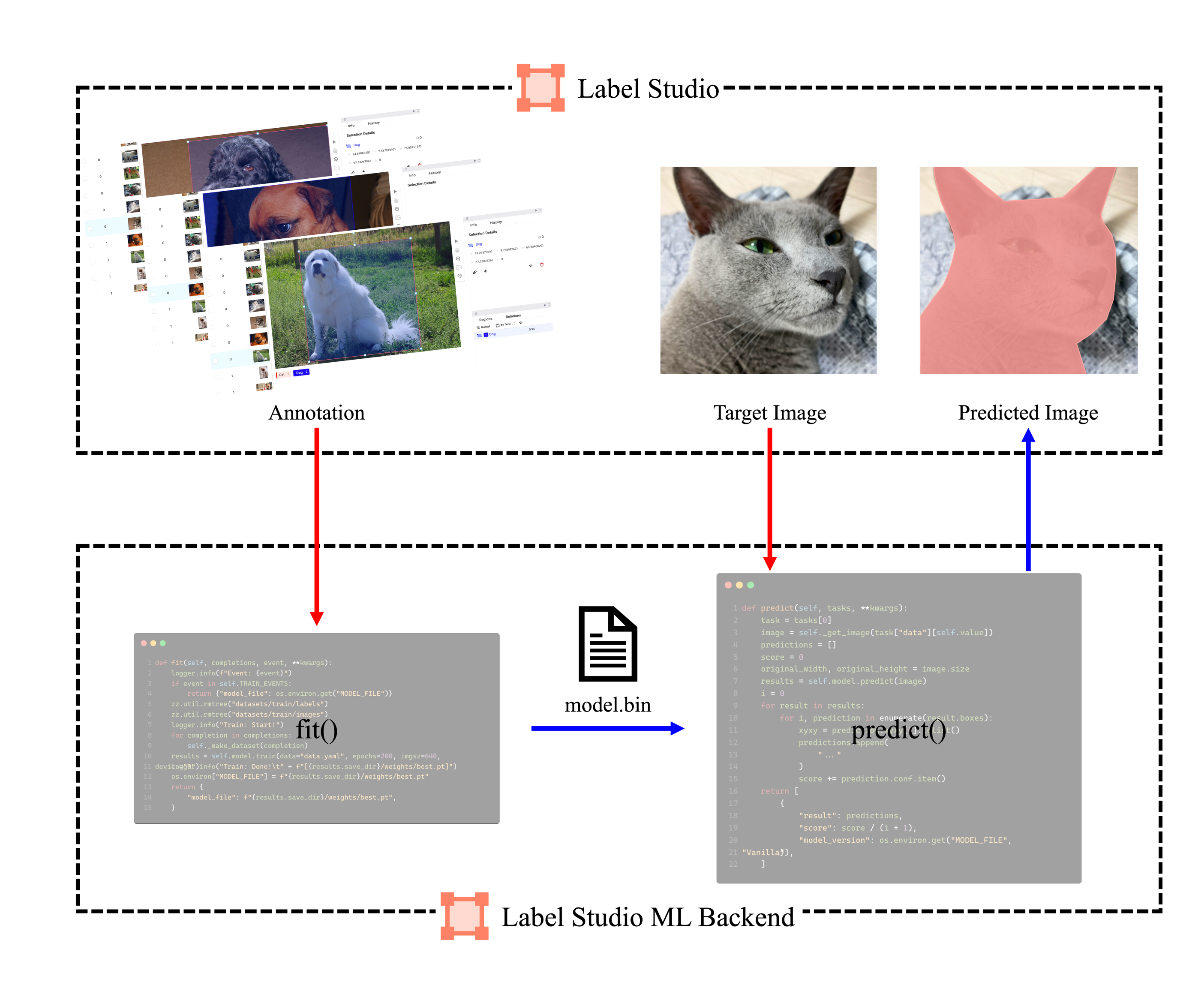
predict(): 입력된 data에 대해 model의 출력을 Label Studio format으로 변경 후 UI에 제공fit(): Label Studio 내 annotation이 완료된 data를 학습하고 load
Hands-On
Label Studio ML Backend 사용을 위해 label-studio-ml을 설치한다.
1 | pip install label-studio-ml |
공식 page에서 제공하는 dummy model을 아래와 같이 구성한다.
Example code
1 | from label_studio_ml.model import LabelStudioMLBase |
model.py가 존재하는 경로에서 아래 명령어를 실행하면 backend를 구동할 수 있다.
1 | label-studio-ml init my_backend |

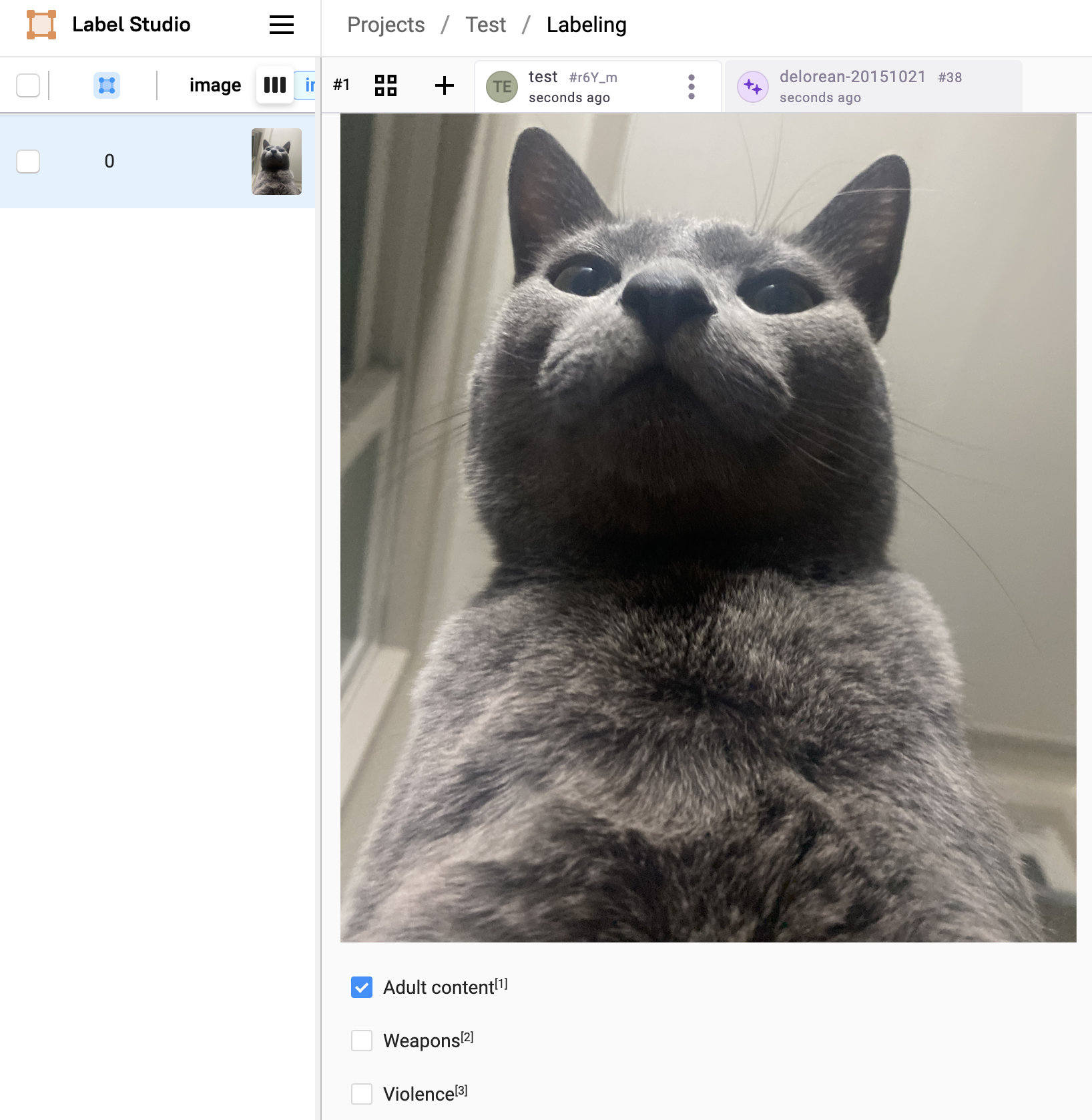
Label Studio UI에서 위와 같은 설정을 마치고 새로운 task를 누르면 아래와 같이 backend가 예측한 결과를 확인할 수 있다.
YOLOv8
실제 상황에서 사용할 수 있는 backend를 구성하기 위해 detection과 segmentation에 대해 학습과 추론이 매우 간편한 ultralytics의 YOLOv8를 사용한다.
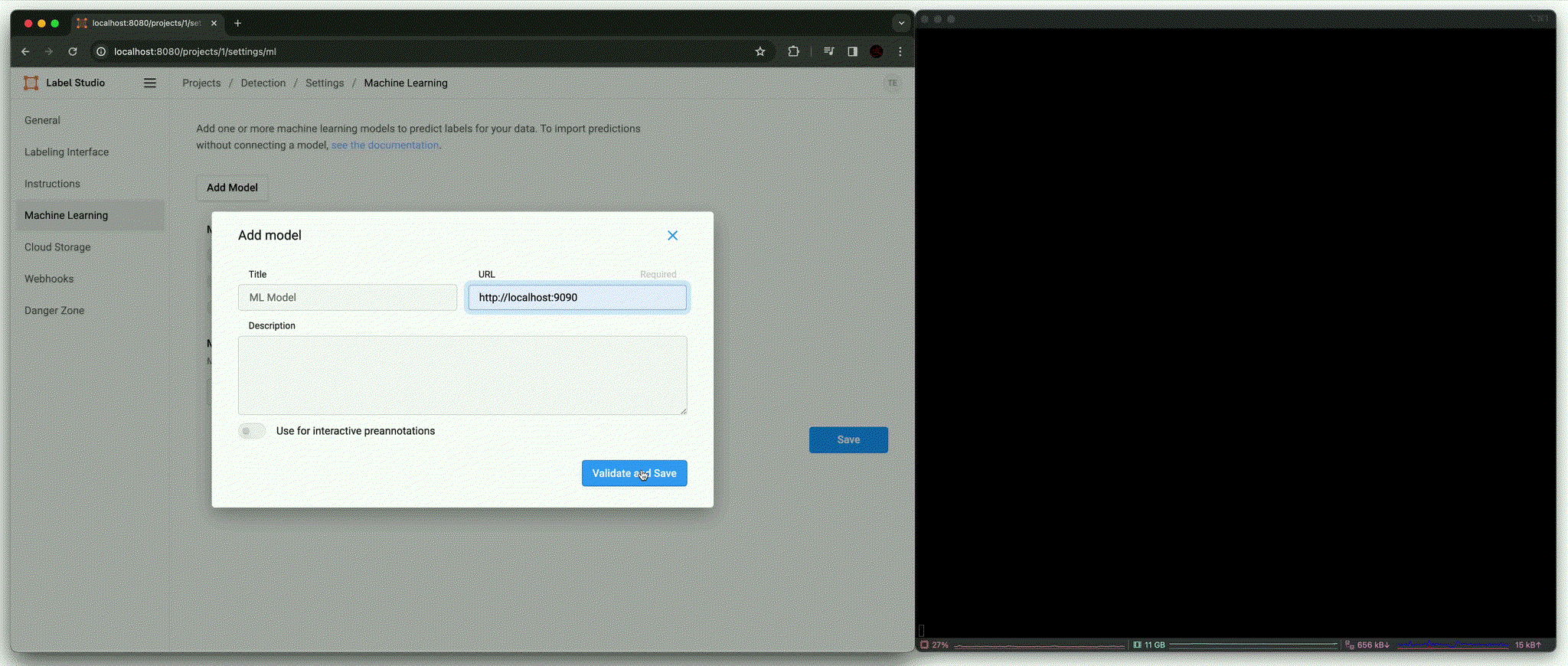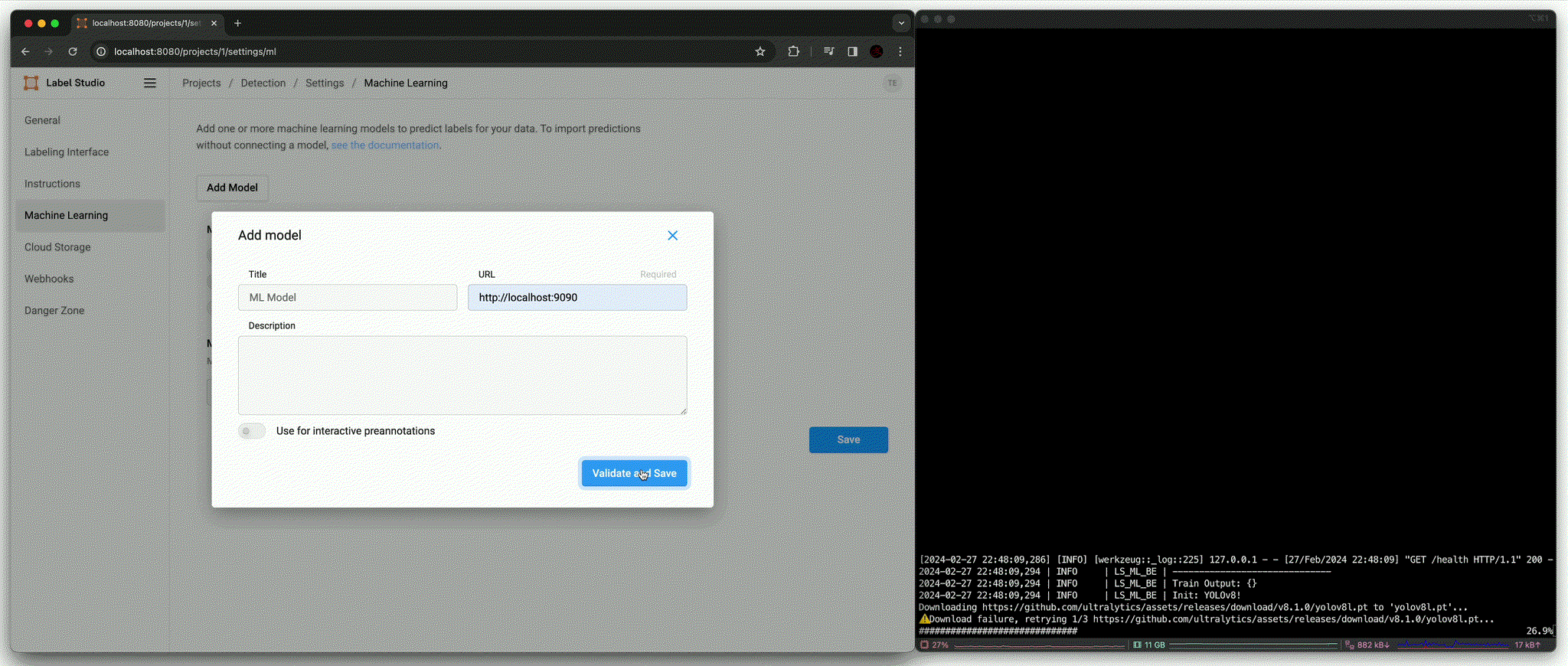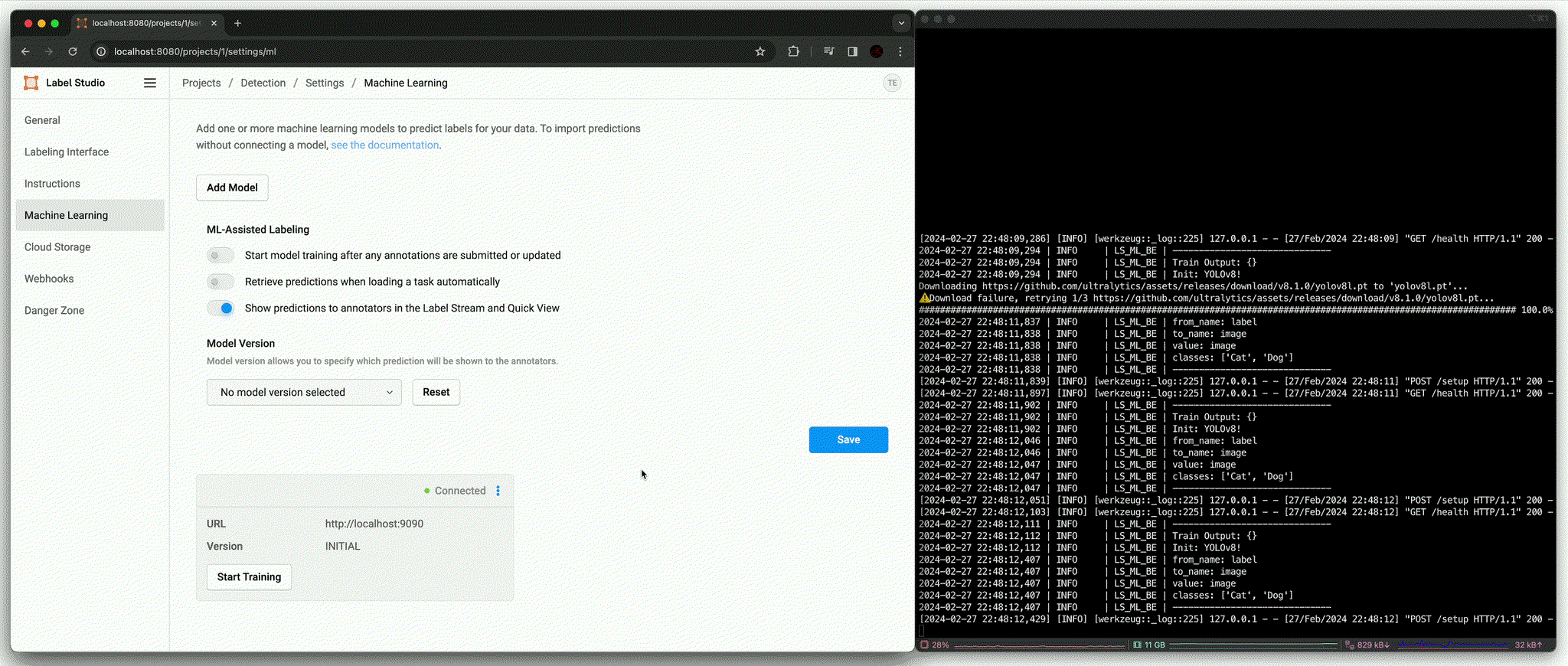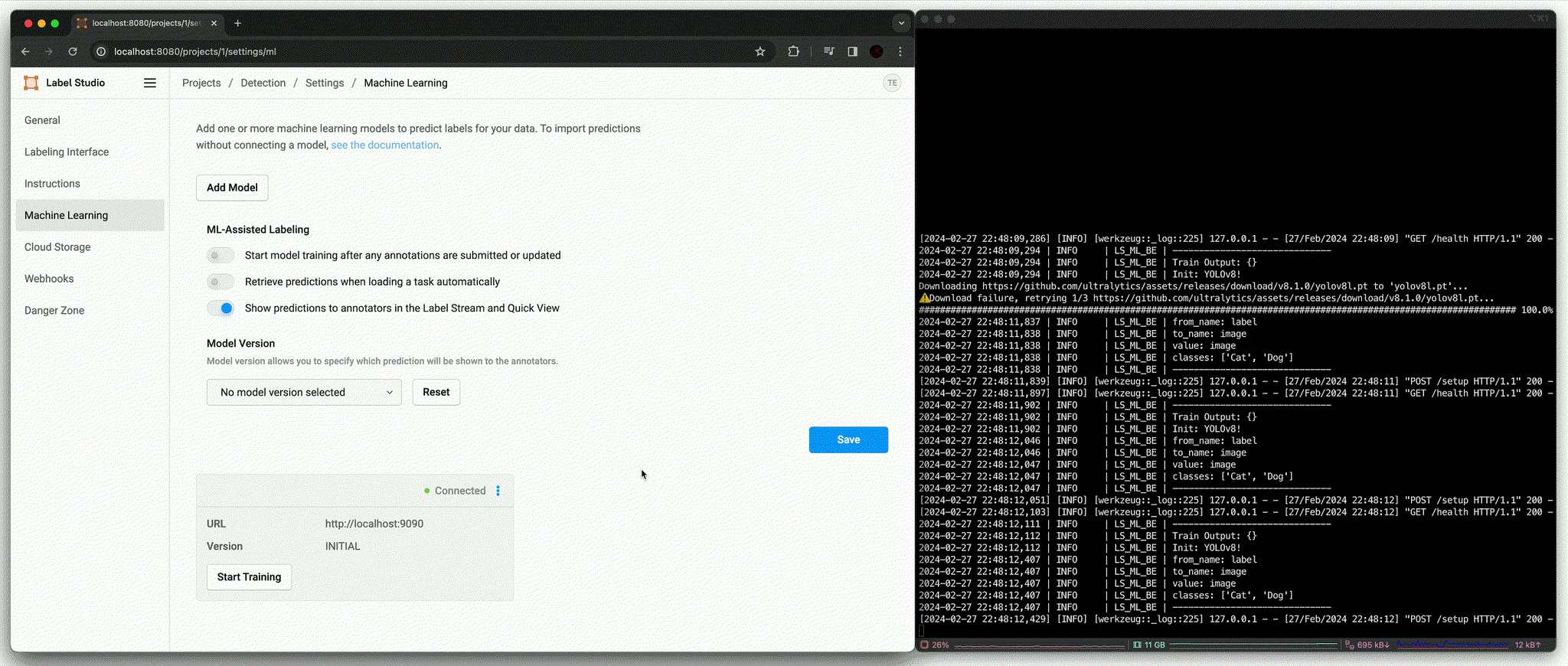
위의 dummy model 예시와는 다르게 image가 필요하기 때문에 아래와 같이 access token을 미리 복사해둔다.
Detection
YOLOv8 기반 Label Studio ML Backend 사용 시나리오는 아래와 같다.
predict():ultralytics에서 제공하는 pre-trained model (yolov8l.pt)로 대상 image의 detection 결과 중 class를 제외한 bbox 영역만을 사용하여 labelingfit(): 유의미한 수의 data가 annotation이 완료되었을 때 fine-tuningpredict(): Fine-tuned model을 통해 대상 image의 detection 결과를 모두 사용하여 labeling
이를 수행하기 위한 전체 code는 아래와 같으며 dummy model의 예시와 동일하게 backend를 구동한다.
전체 code
1 | path: ./ |
1 | import os |
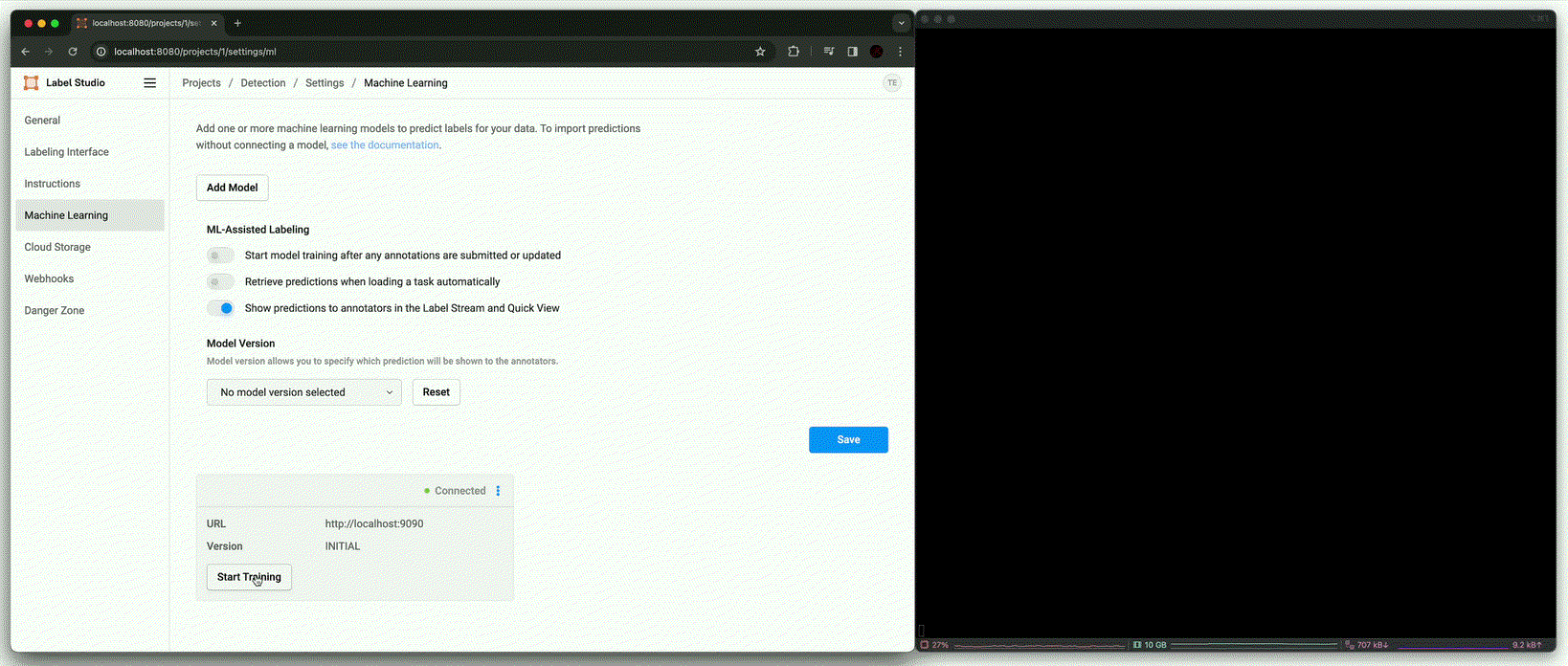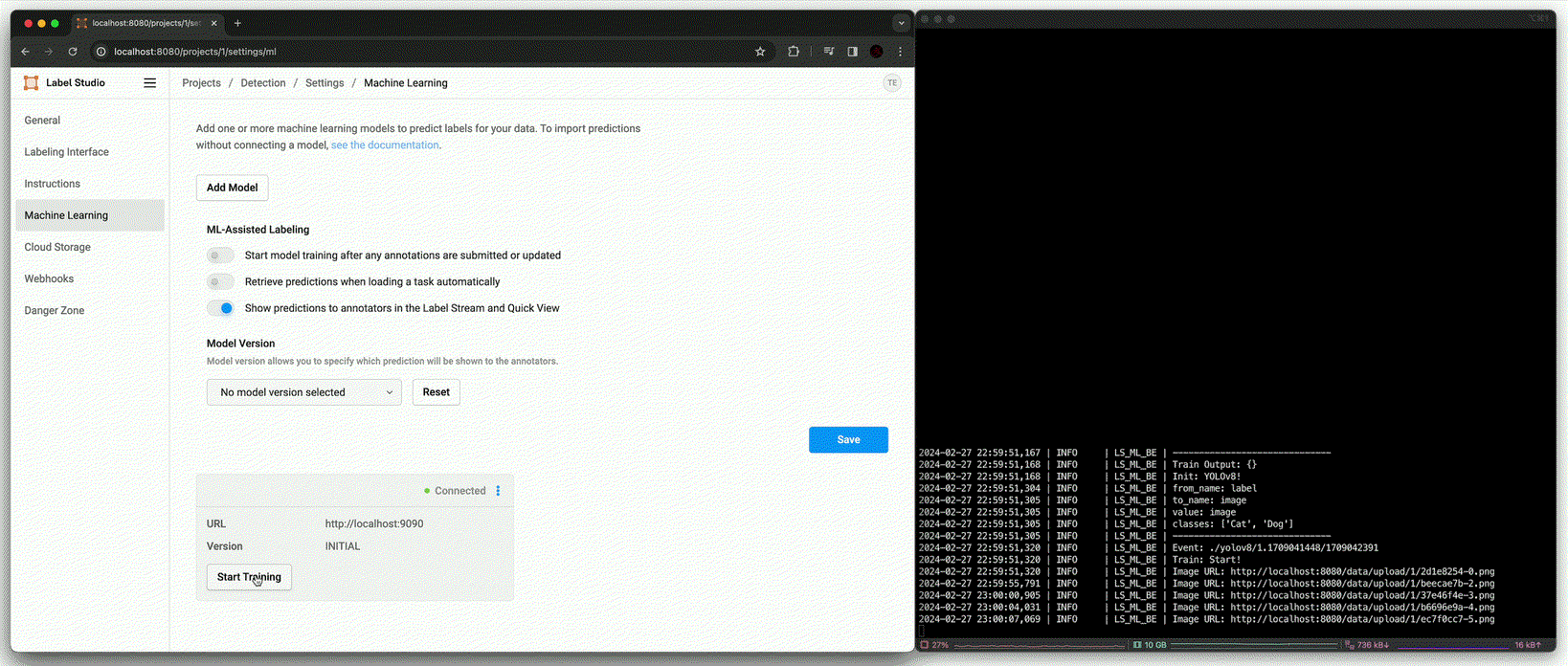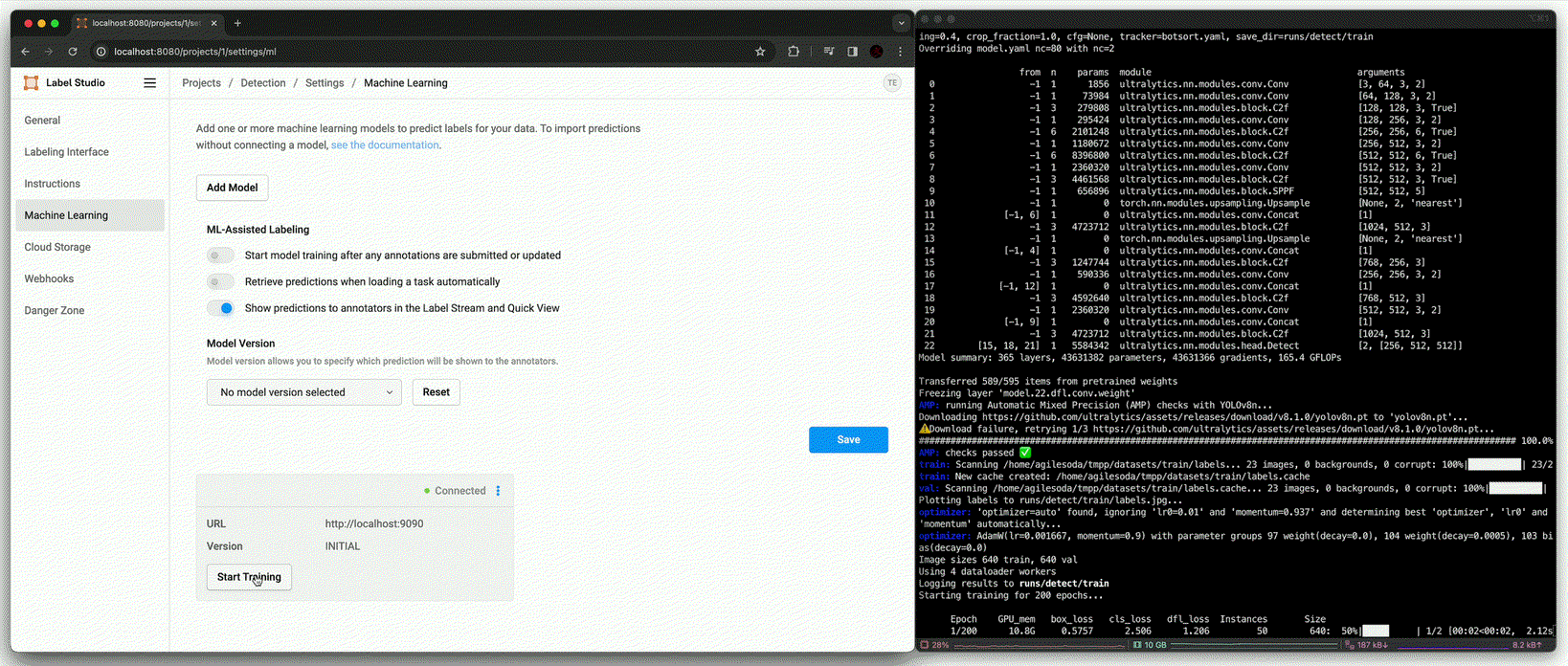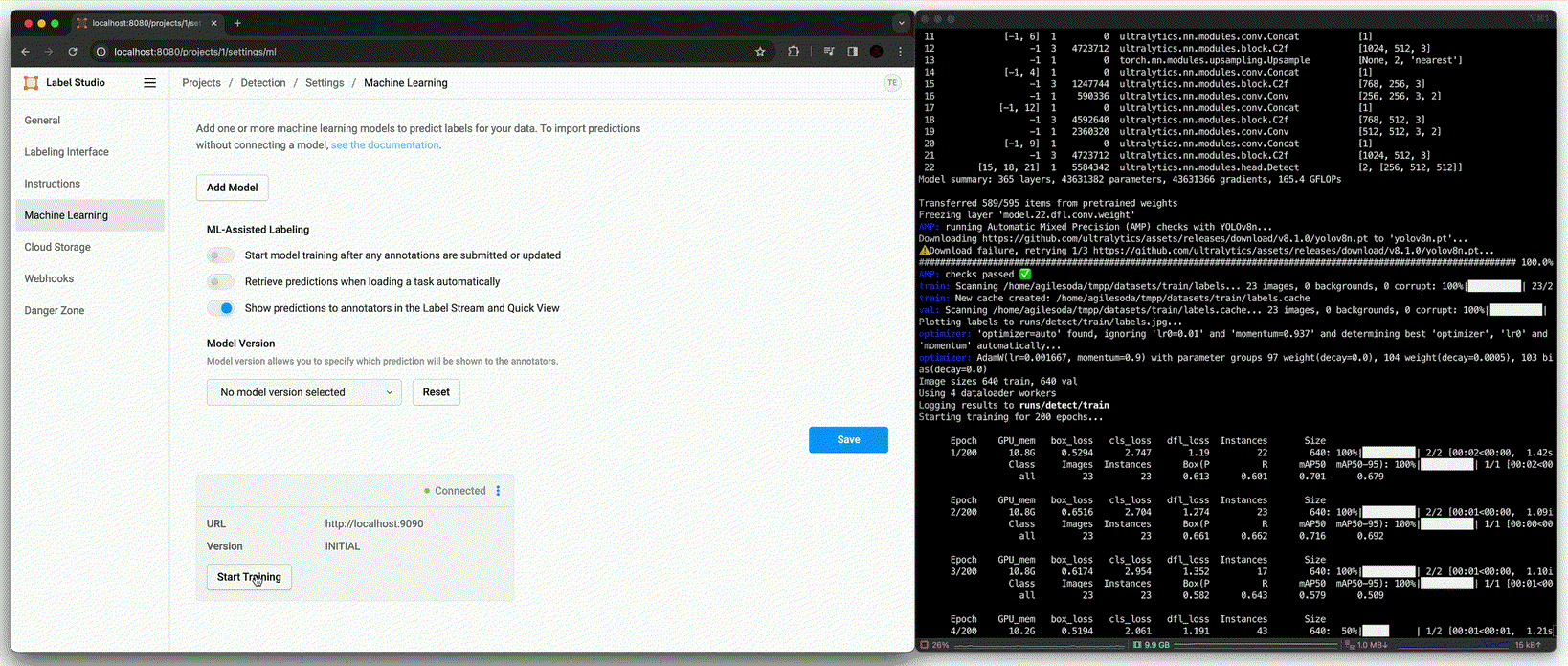
Add model
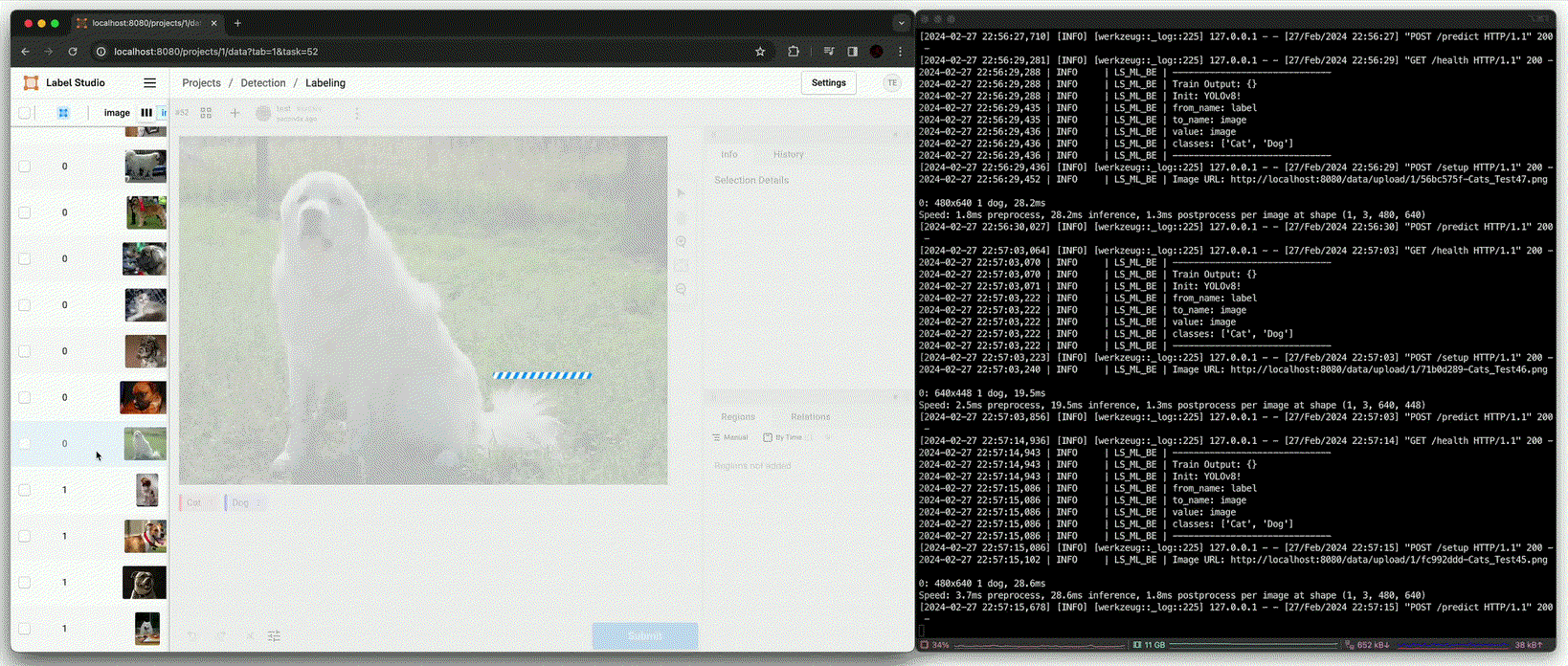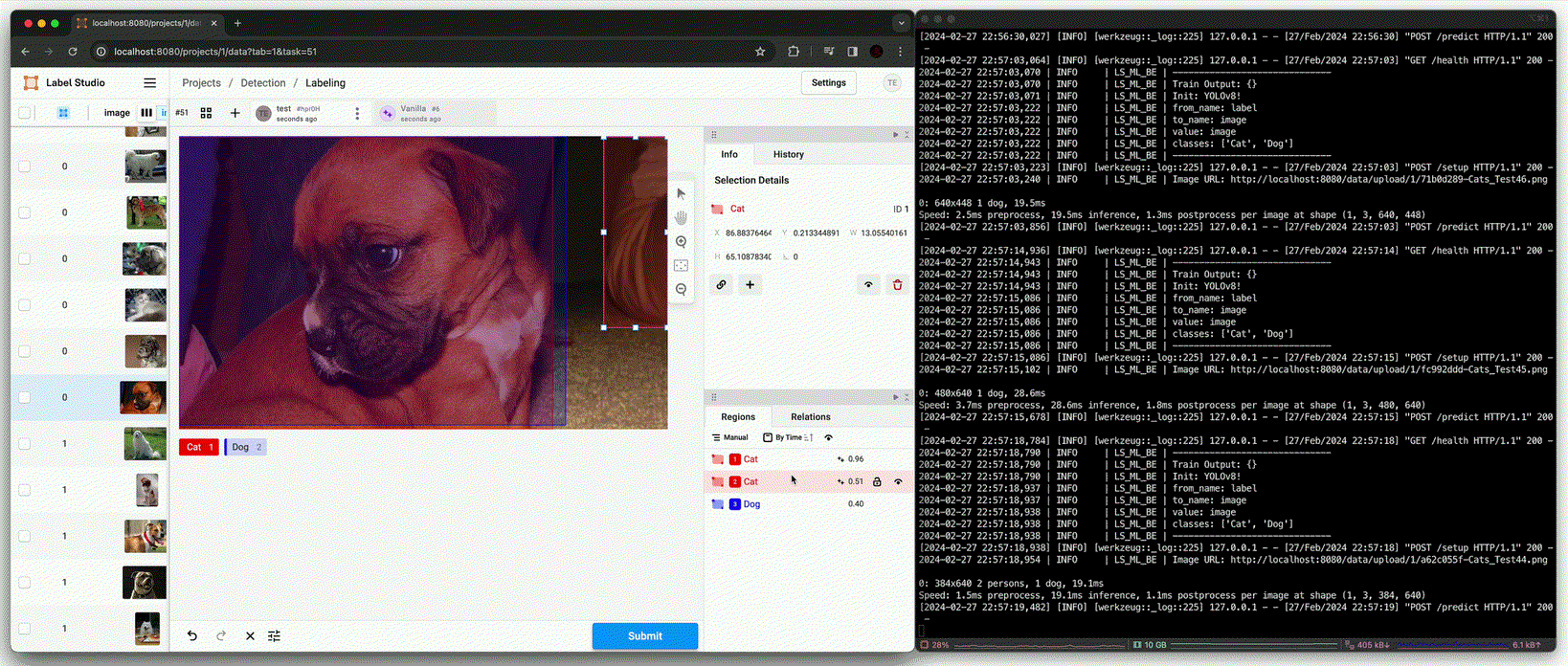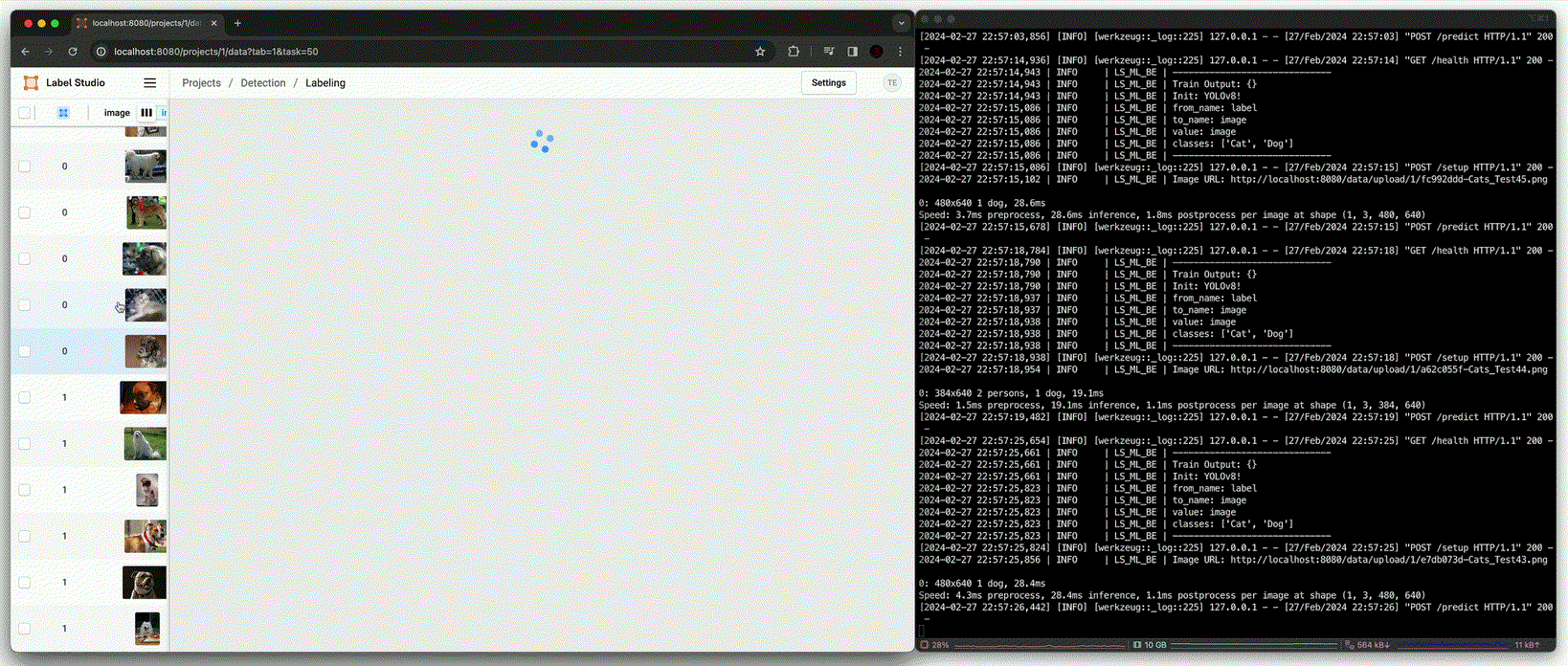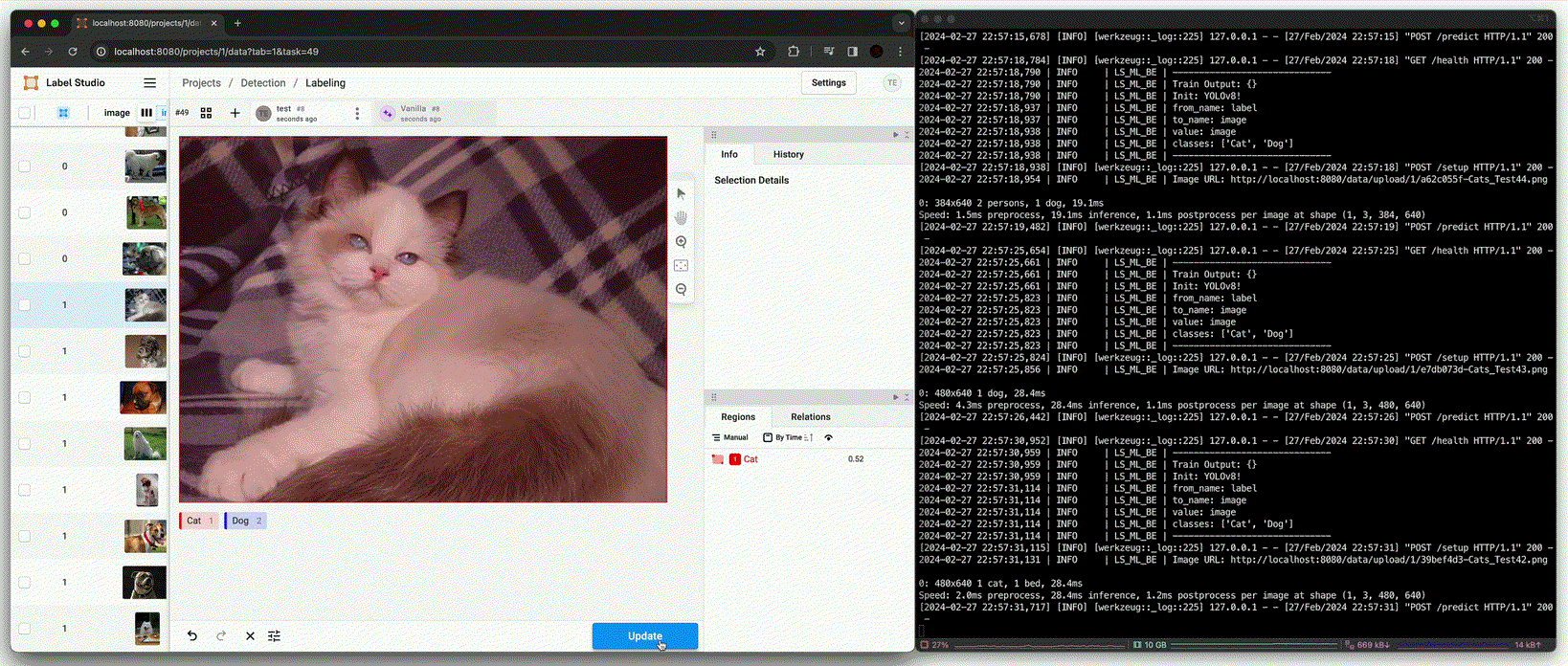
Annotation using pre-trained model [
predict()(Beforefit())]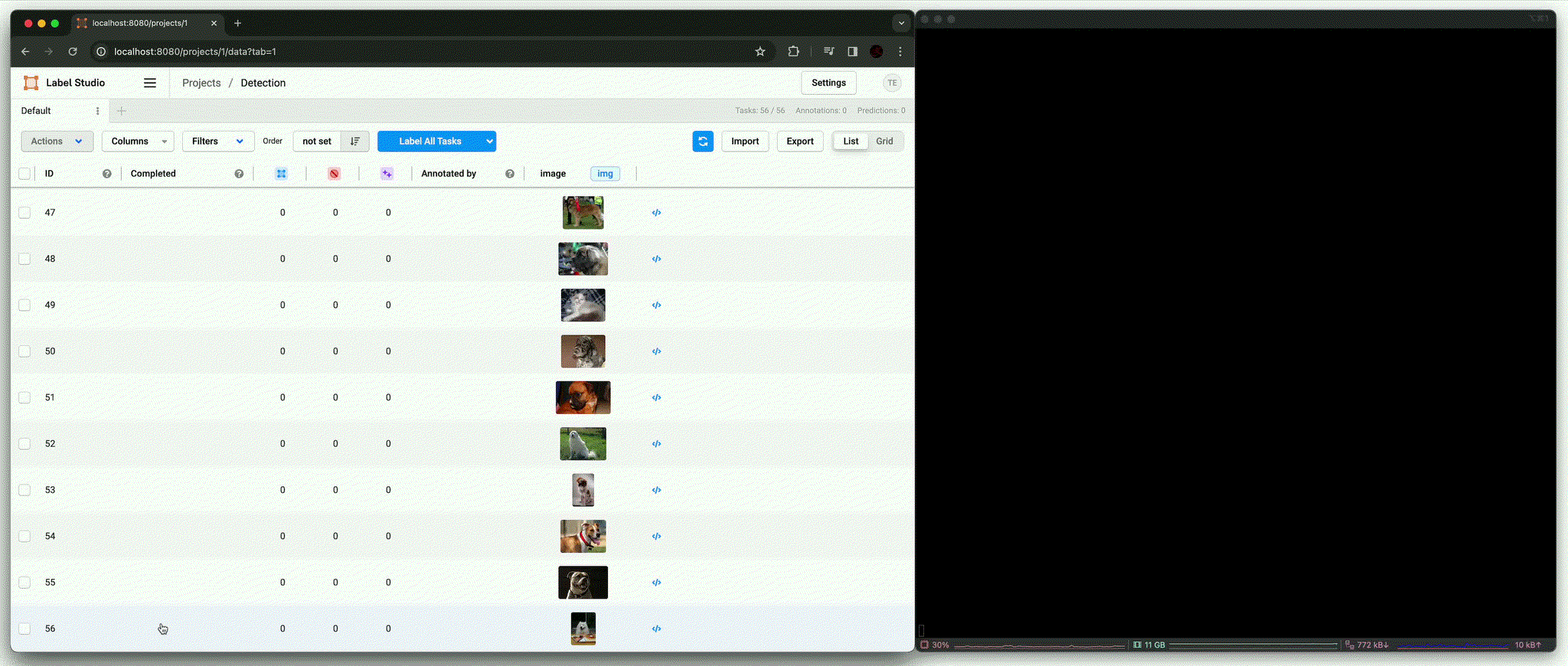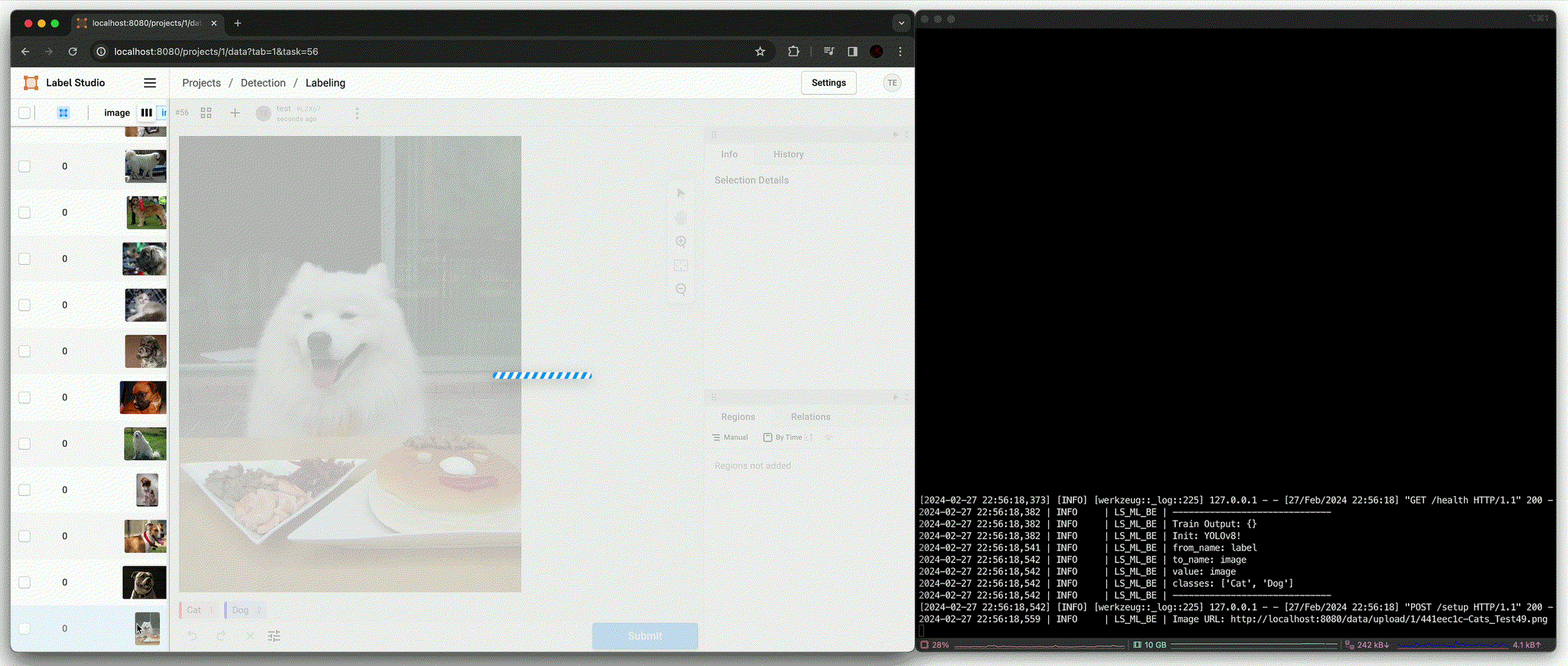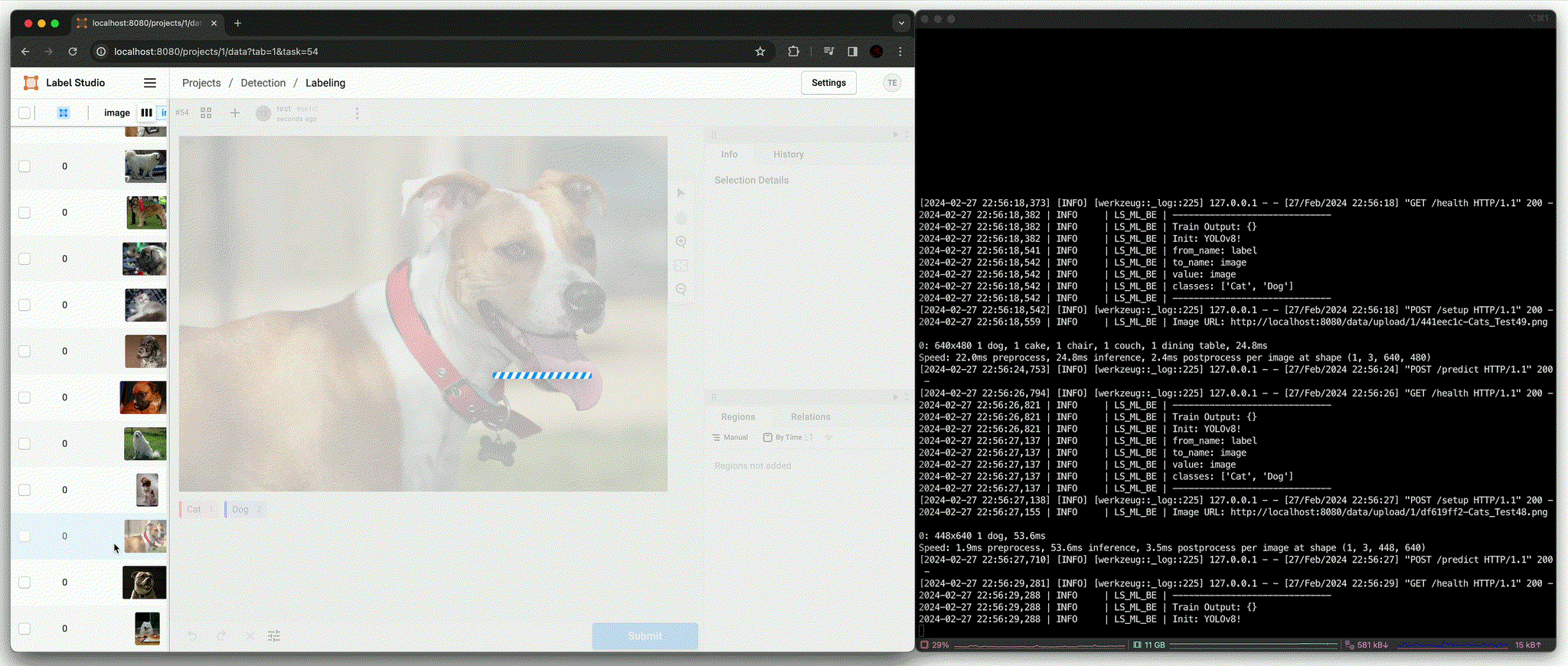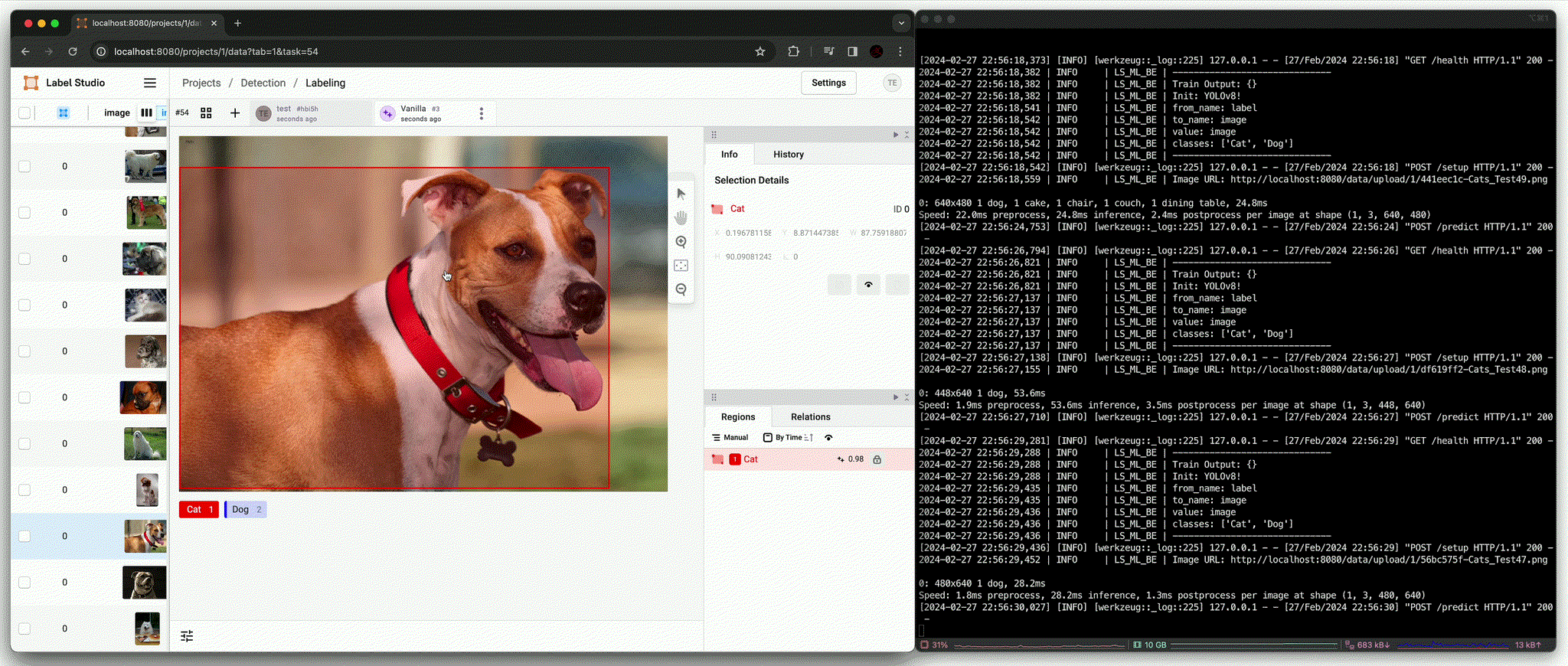
Training [
fit()]
Annotation using trained model [
predict()(Afterfit())]
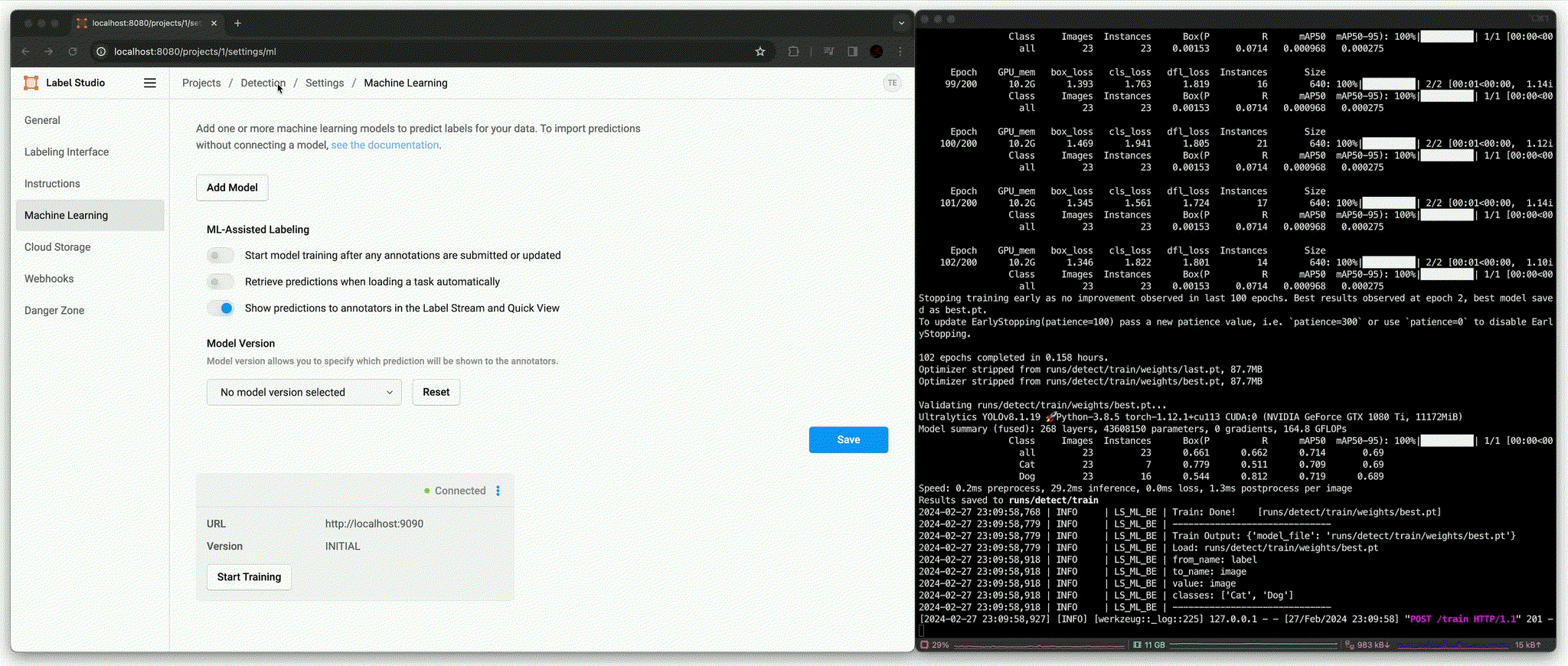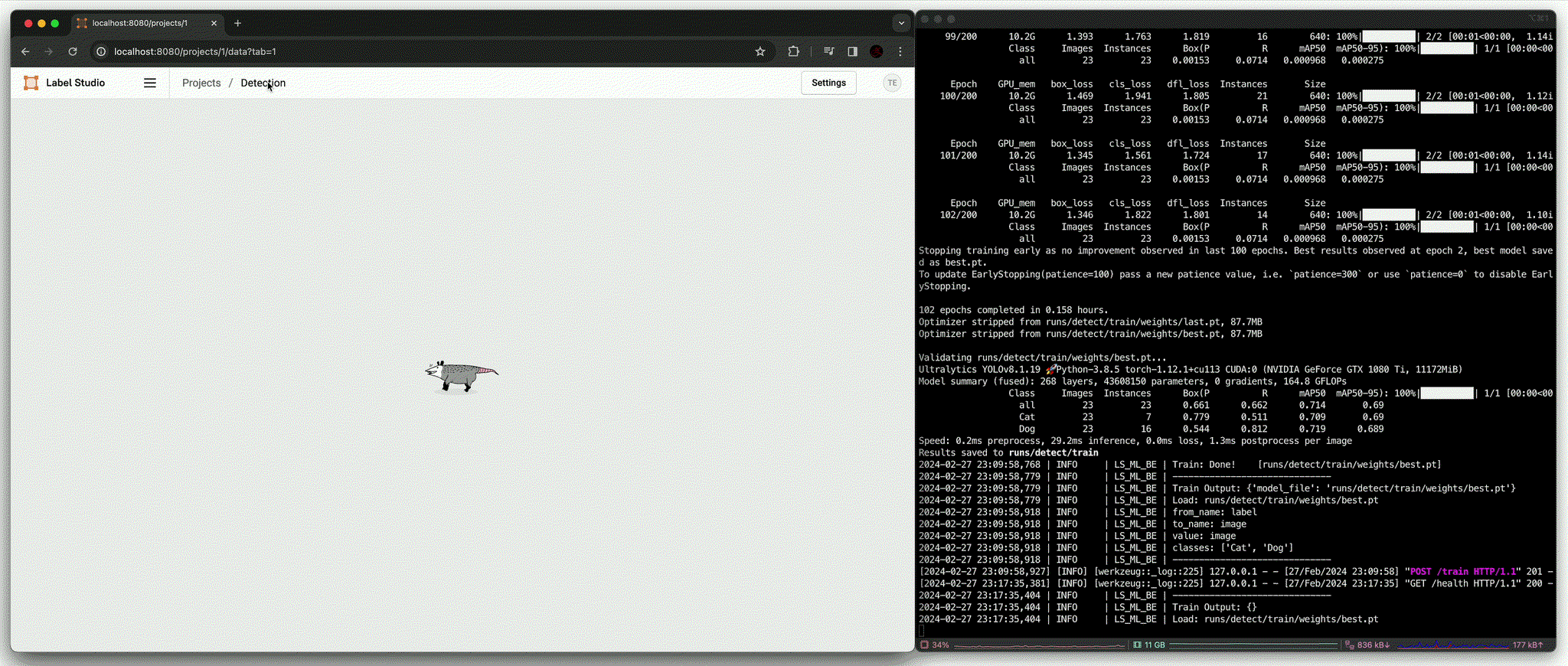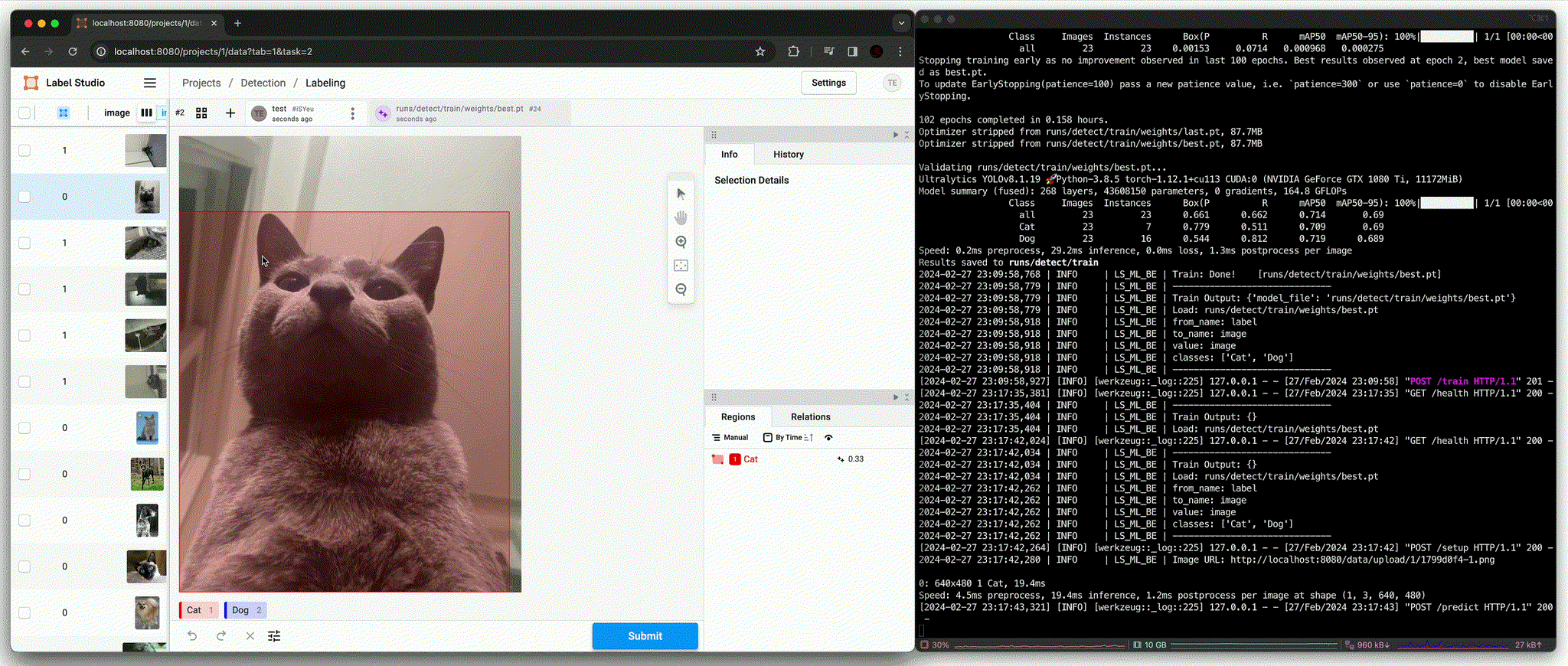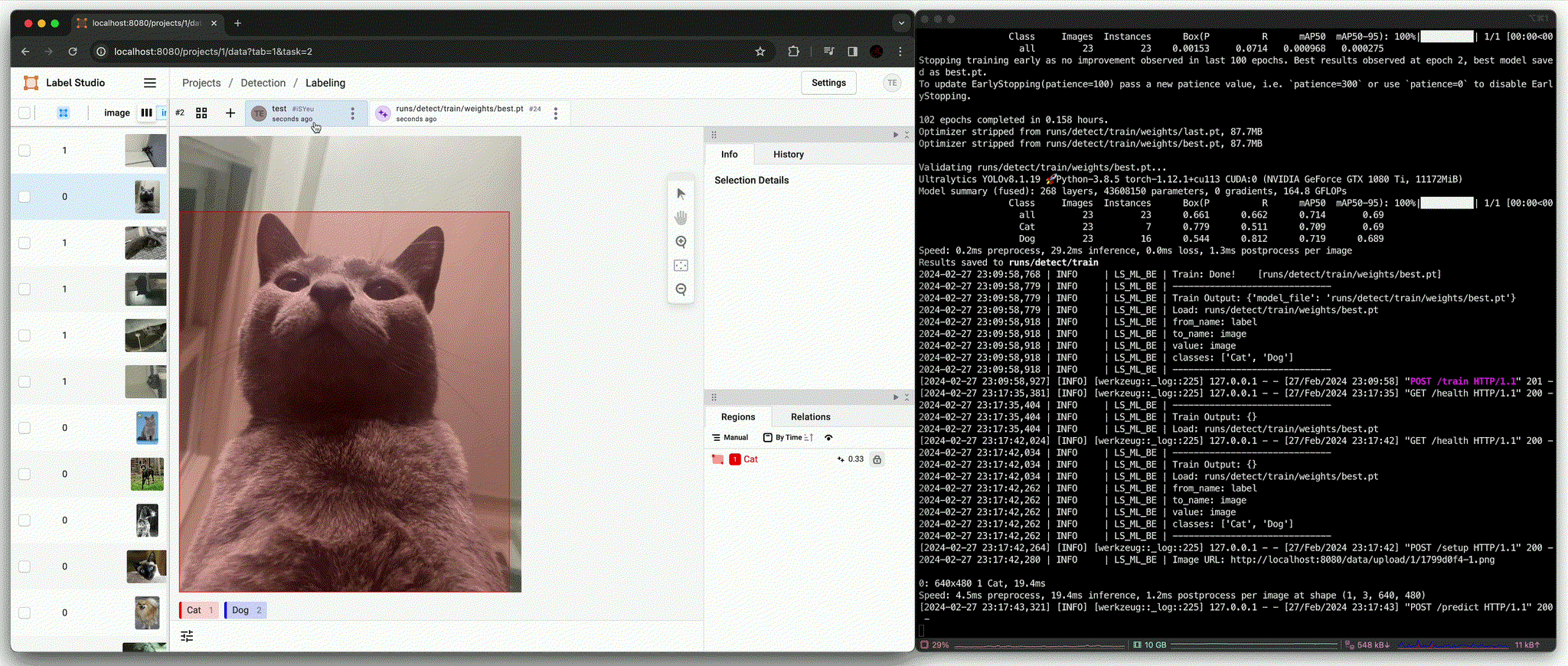
결과적으로 학습에 포함되지 않았던 image에 대해 정확한 bbox와 class 결과를 추론하는 것을 확인할 수 있다.
Segmentation
Segmentation도 Detection과 같이 동일한 시나리오와 구성을 가지지만, Label Studio와의 학습 data와 출력의 format이 다르기 때문에 아래와 같이 code를 수정했다.
전체 code
1 | import os |
Add model
Annotation using pre-trained model [
predict()(Beforefit())]
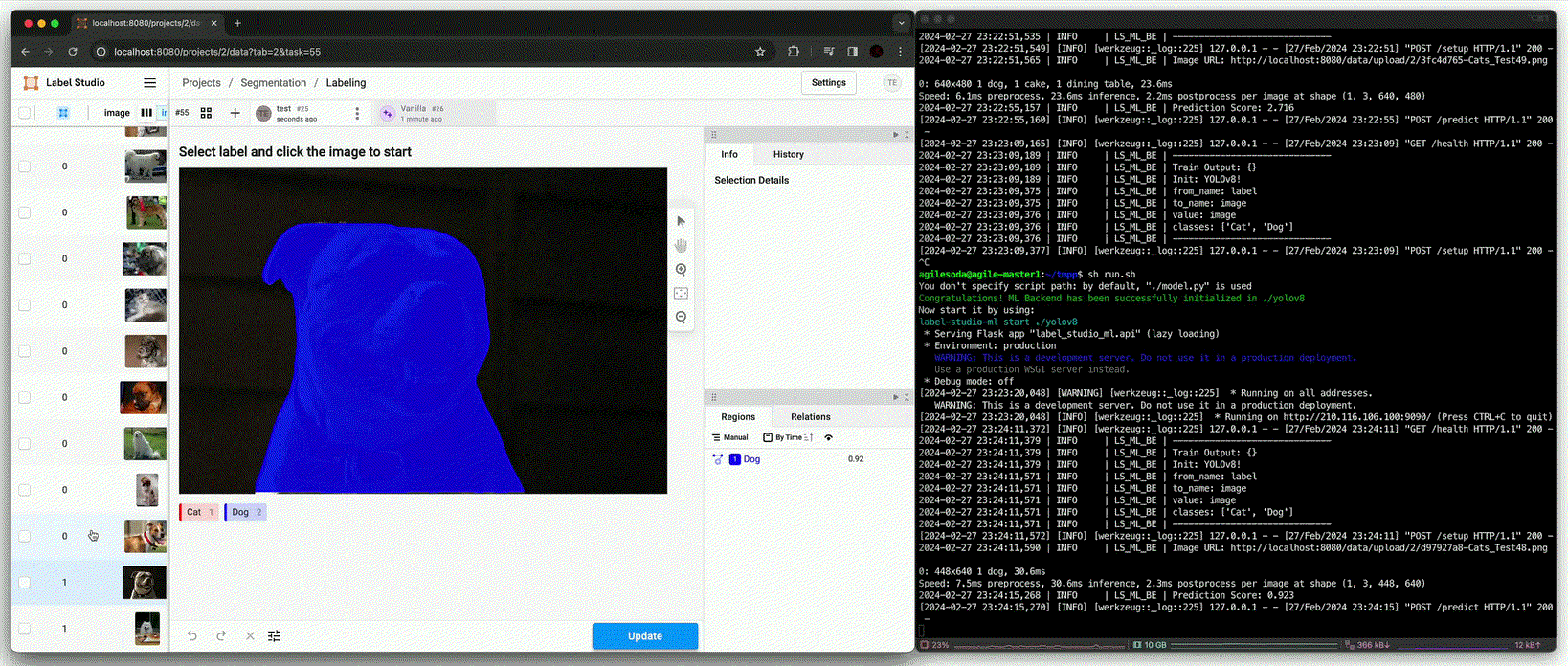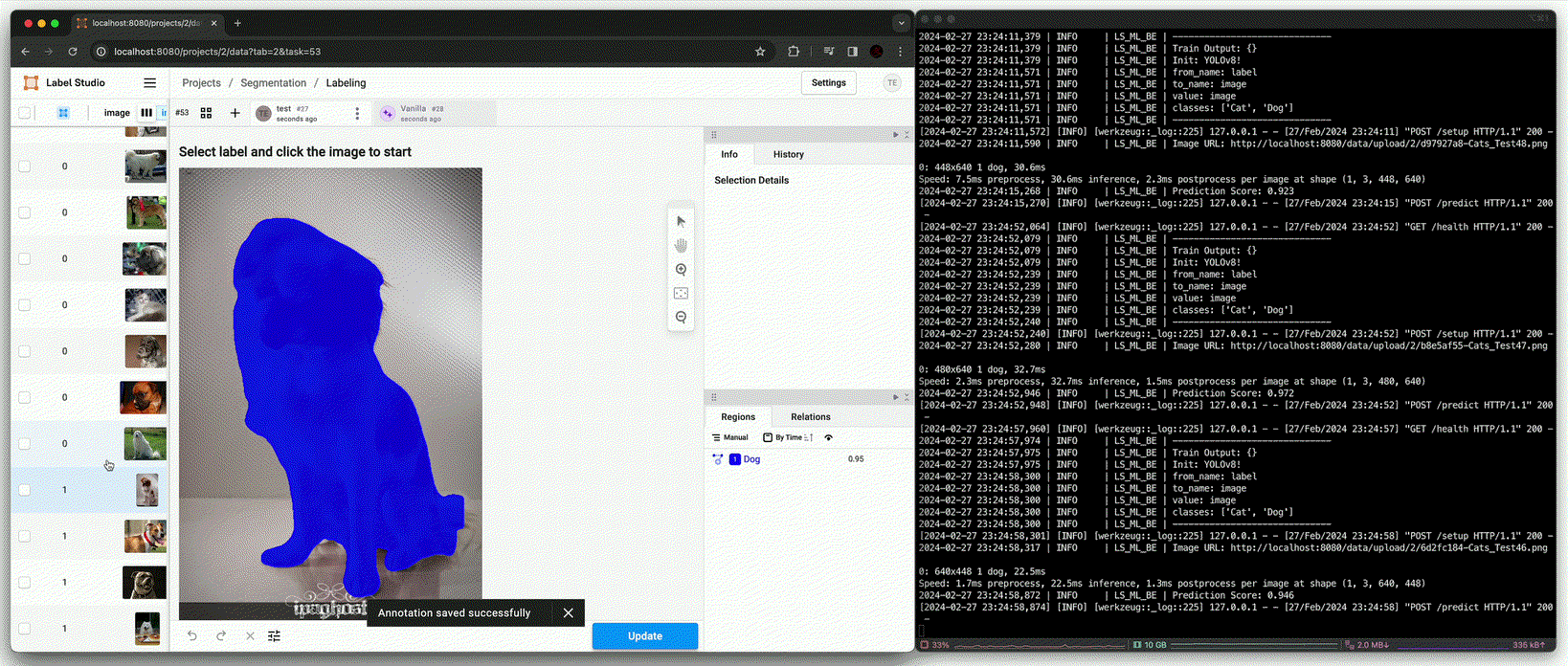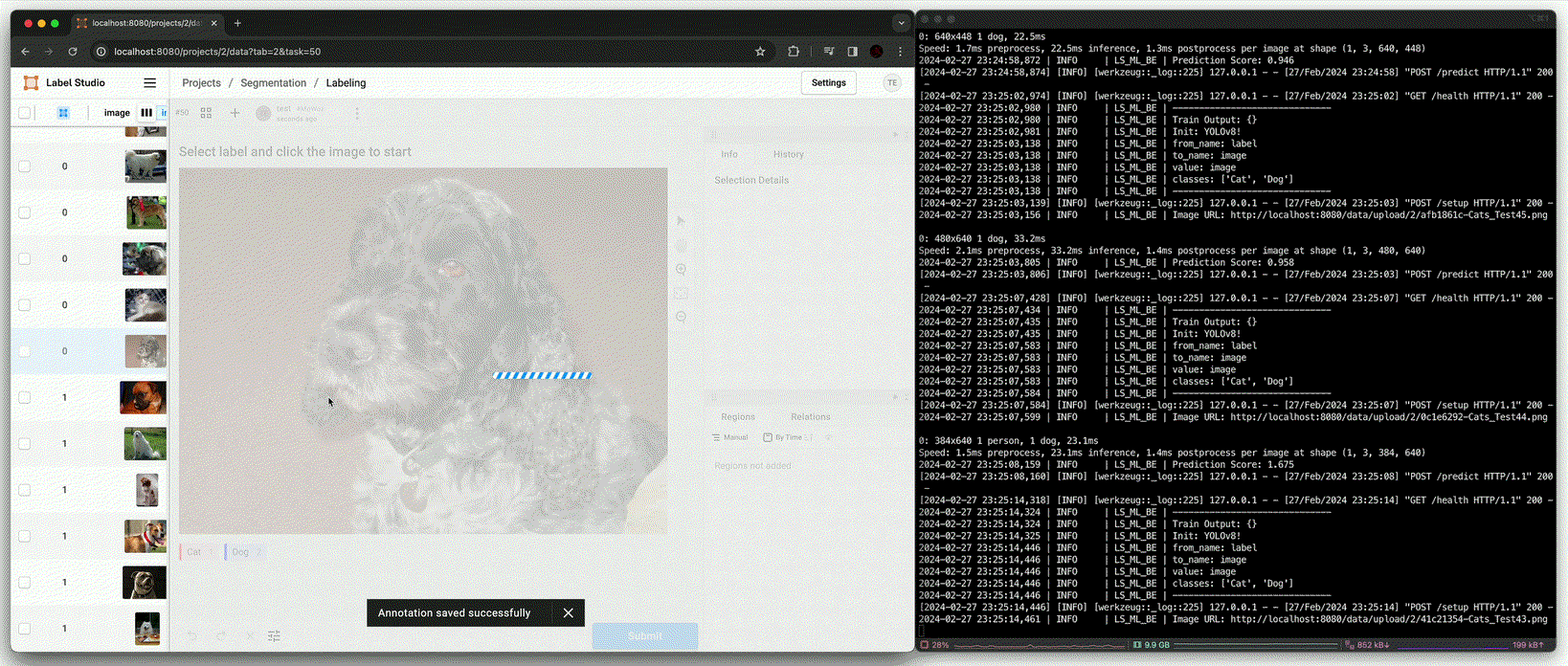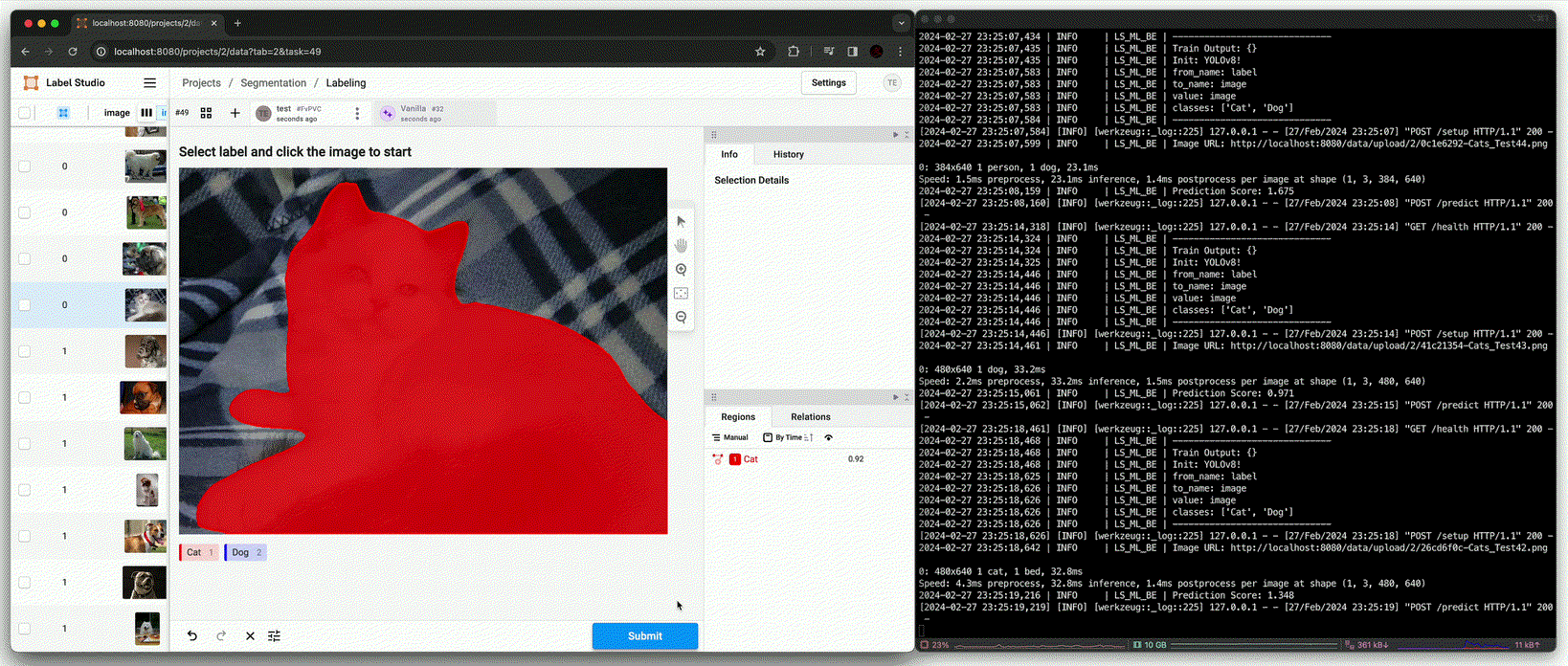
Training [
fit()]
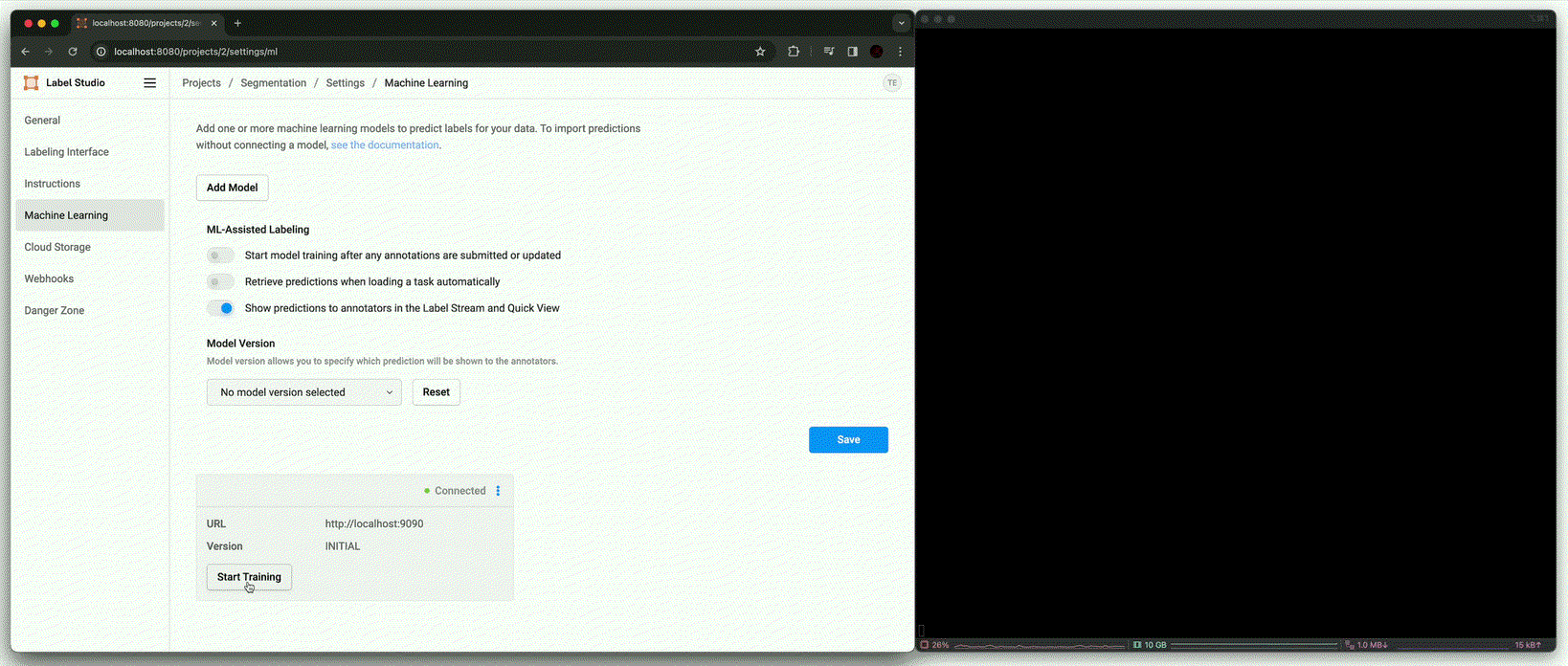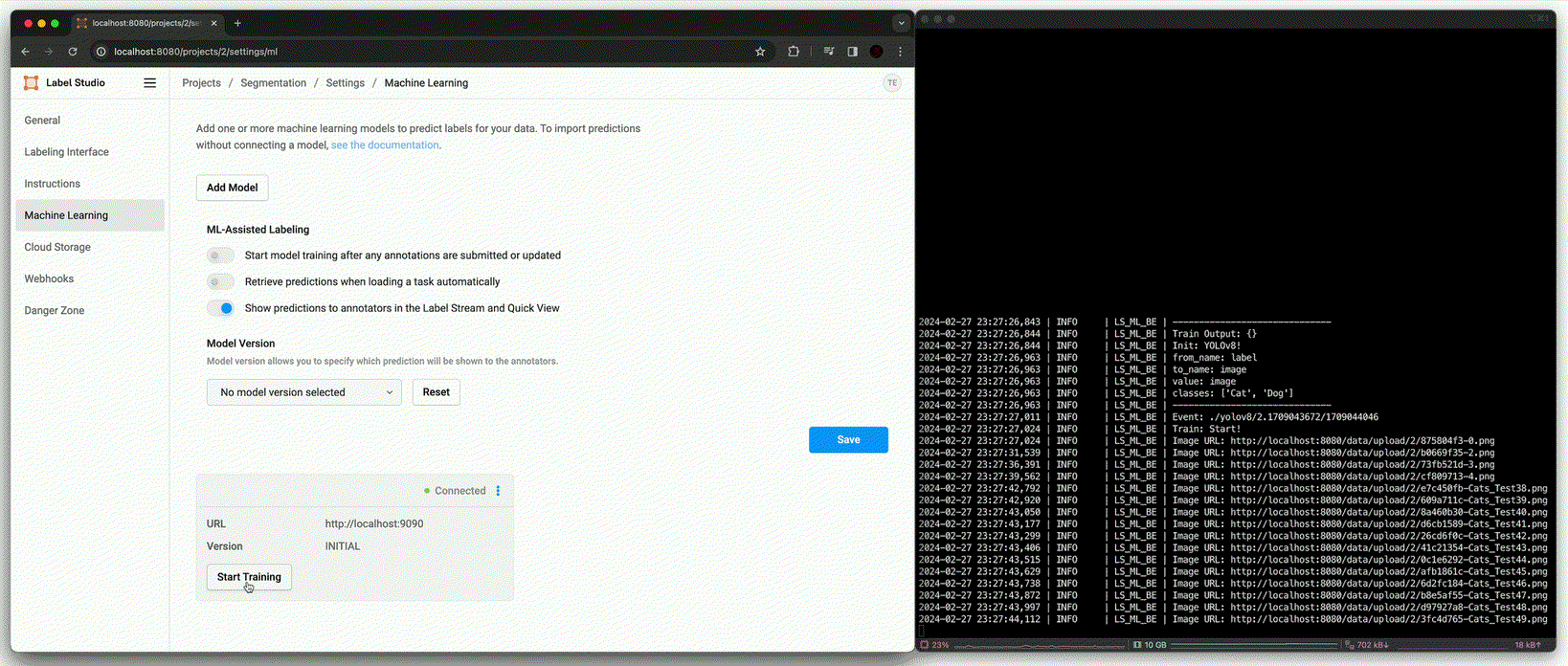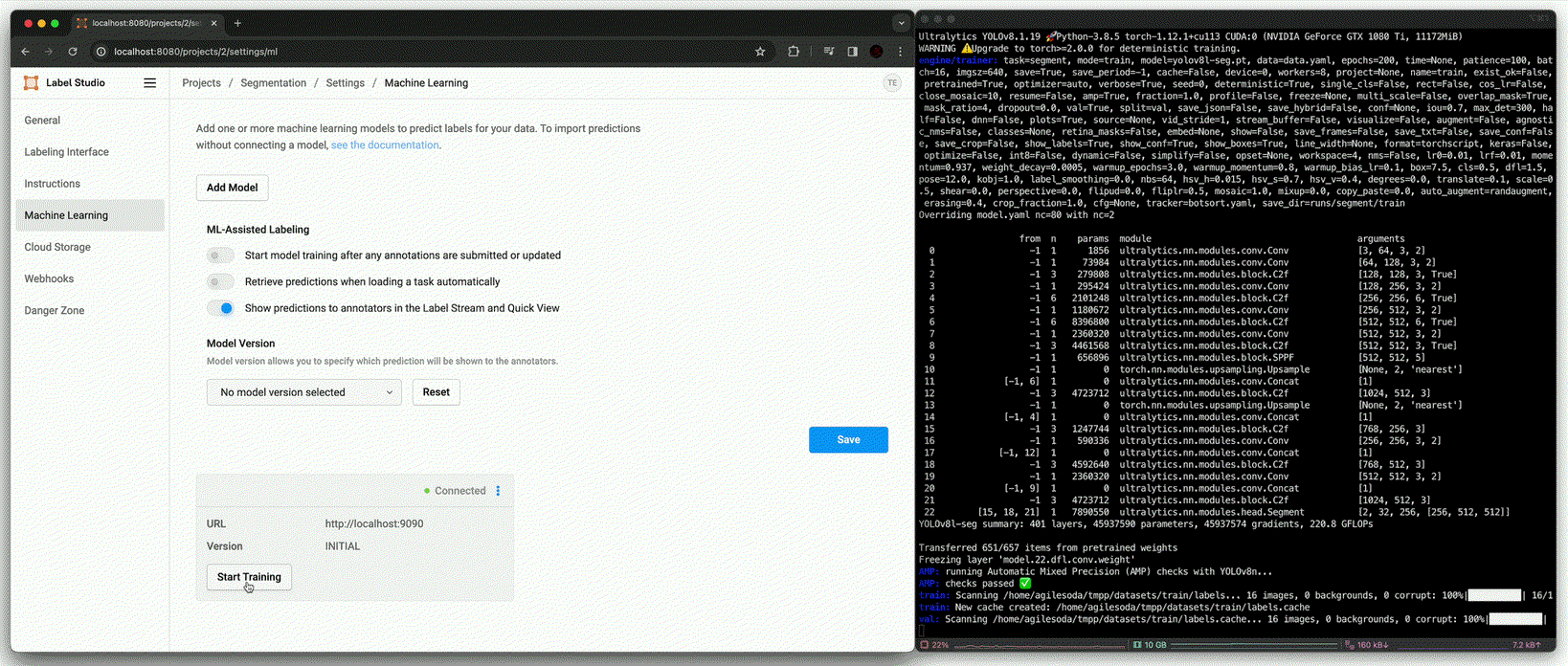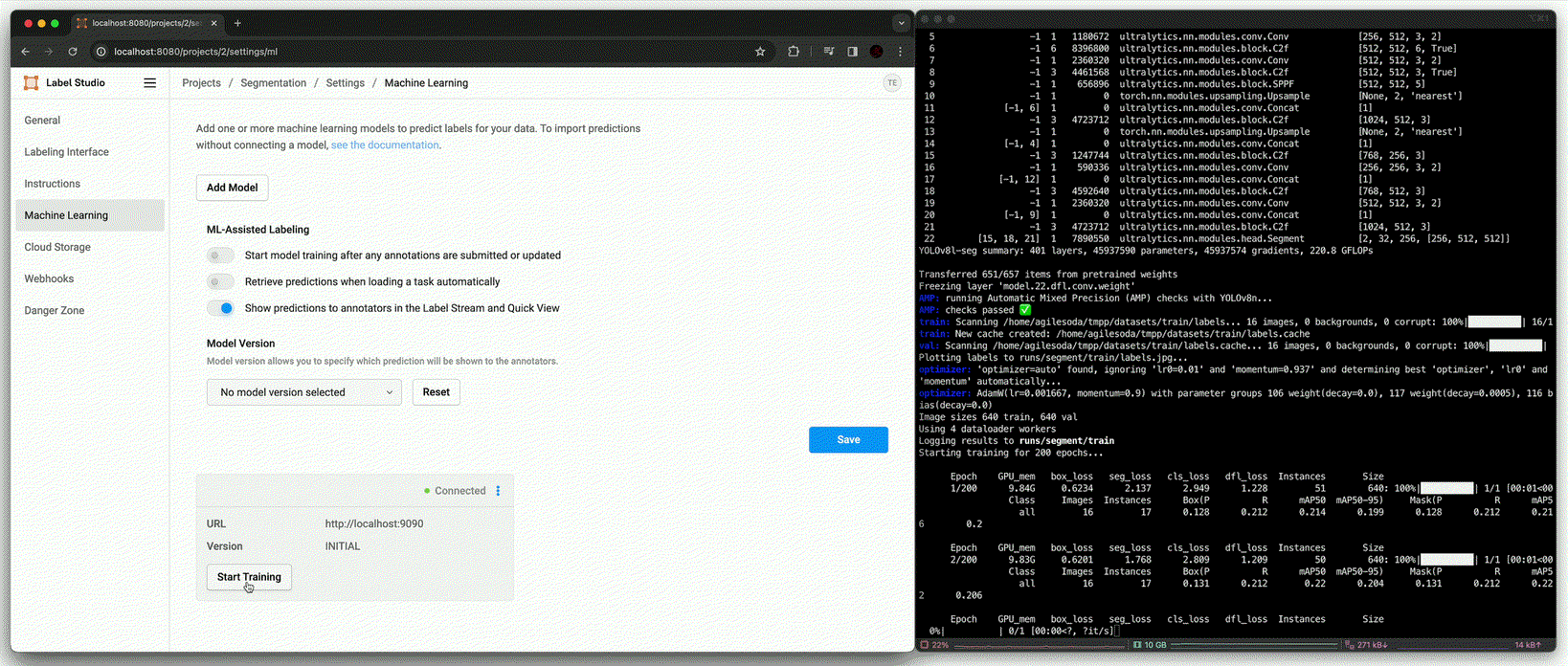
Annotation using fine-tuned model [
predict()(Afterfit())]
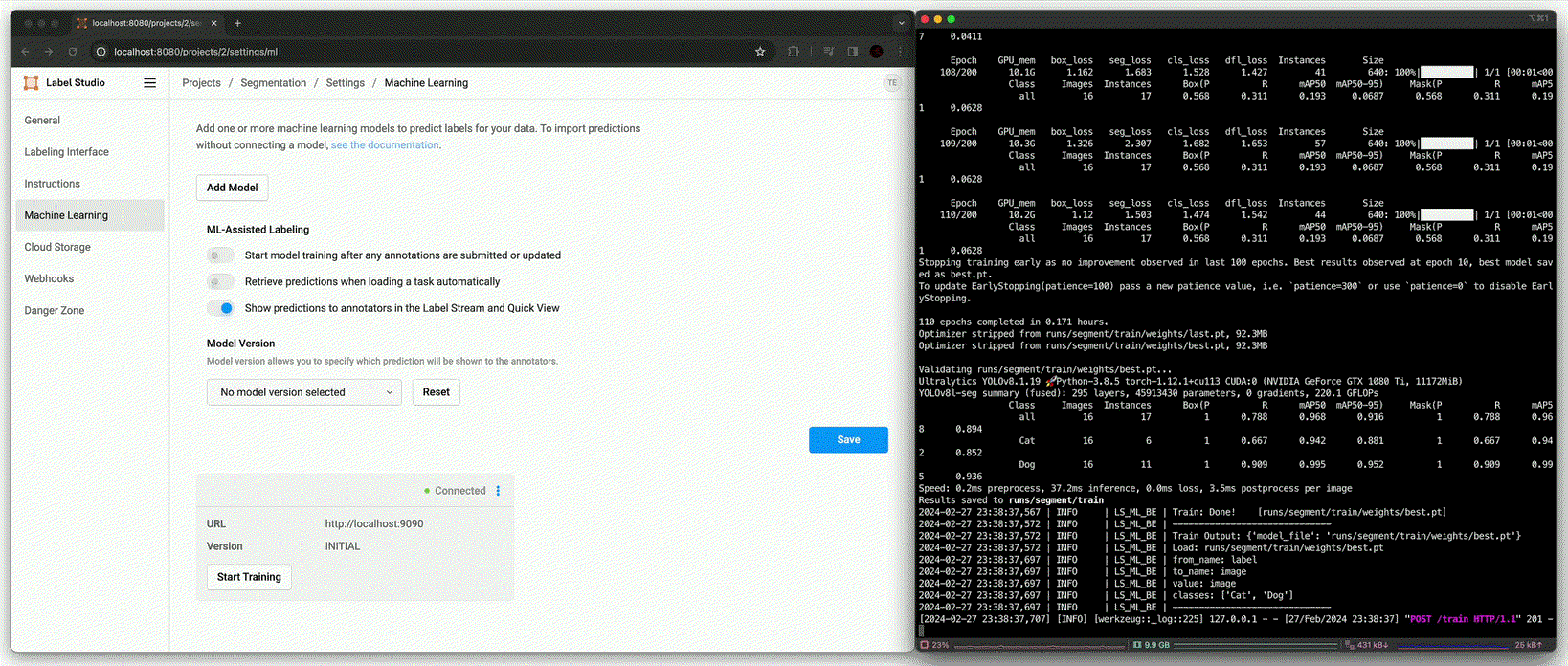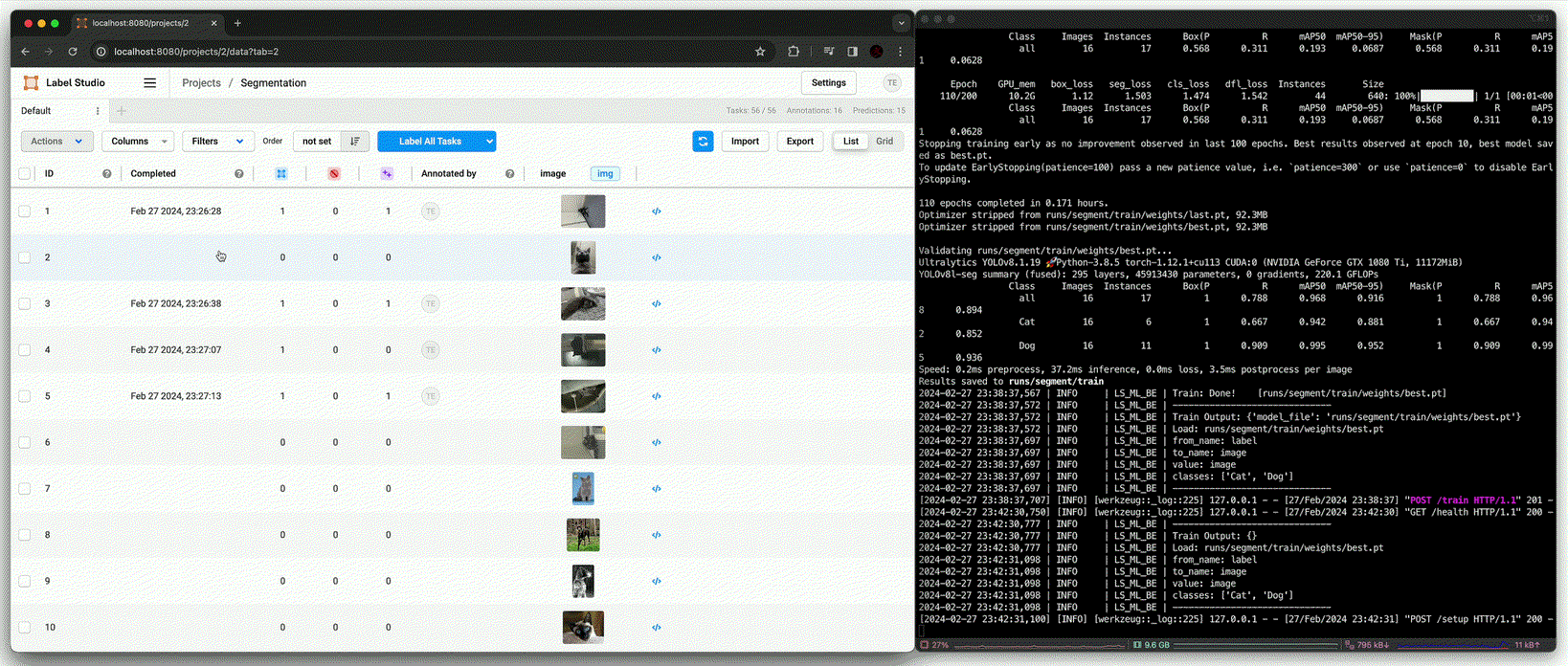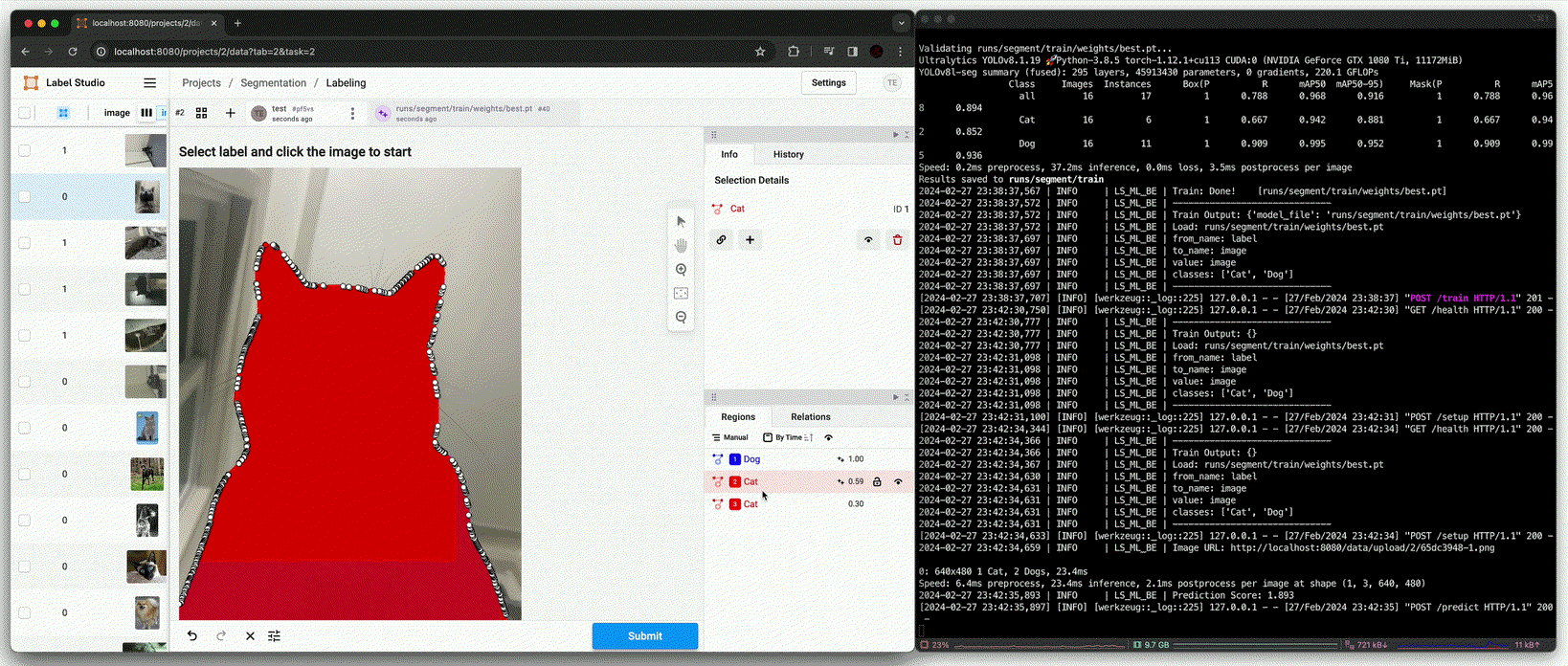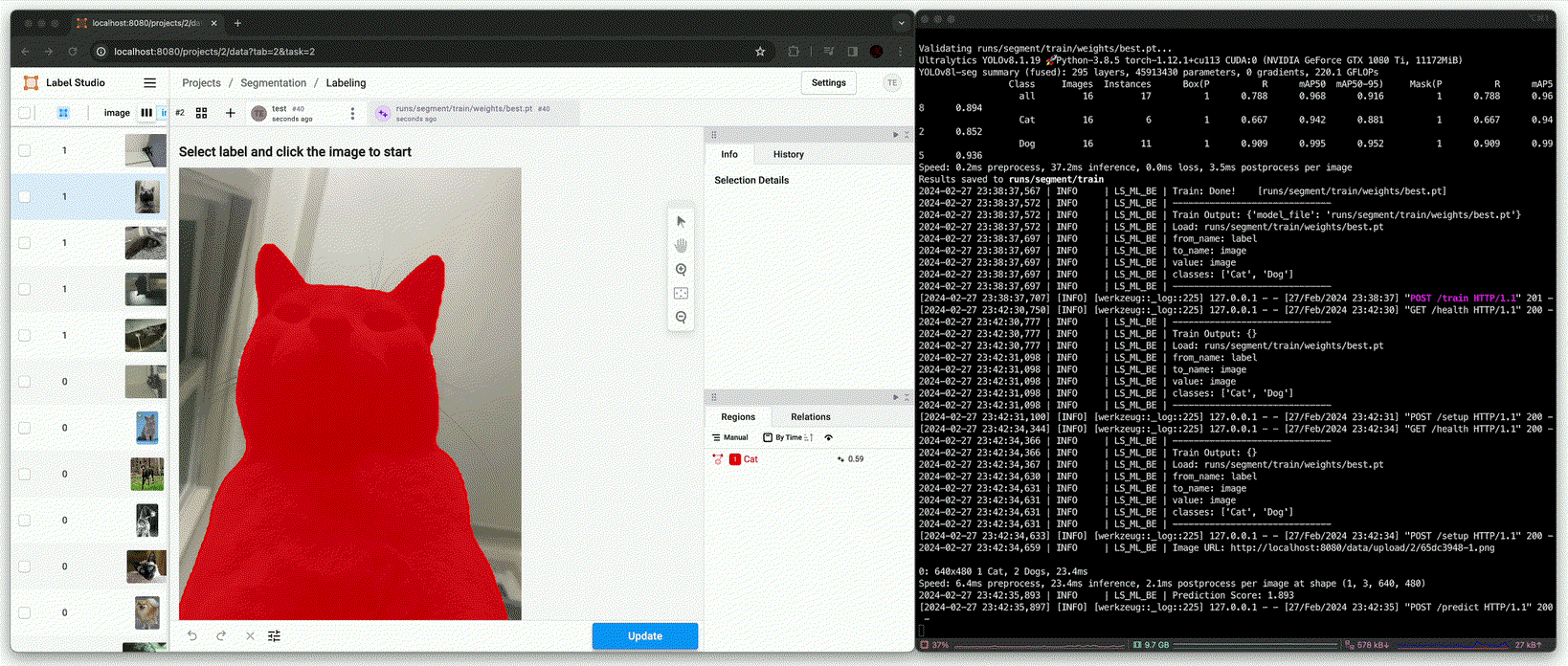
Detection의 추론 성능까지는 못미치지만, NMS와 같은 추론 시 사용될 변수를 조정하여 사용하면 annotation 시 큰 도움이 될 수 있다.
Production
Docker Compose
model.py & data.yaml
1 | import os |
1 | path: ../data |
Dockerfile
1 | FROM nvidia/cuda:12.3.2-cudnn9-runtime-ubuntu22.04 |
docker-compose.yaml
1 | version: "3.8" |
Add model 시 URL을 http://backend:9090로 작성만 하면 잘 작동한다.
Kubernetes
model.py & data.yaml
1 | import os |
1 | path: ../data |
Dockerfile
1 | FROM nvidia/cuda:12.3.2-cudnn9-runtime-ubuntu22.04 |
redis.yaml
1 | apiVersion: v1 |
backend.yaml
1 | apiVersion: apps/v1 |
label-studio.yaml
1 | apiVersion: apps/v1 |
Add model 시 URL을 http://backend.${NAMESPACE}:9090와 같은 형태로 작성만 하면 잘 작동한다.
Issues
TypeError: argument of type ModelWrapper is not iterable
TypeError: argument of type ModelWrapper is not iterable1 | Traceback (most recent call last): |
위와 같은 issue 발생 시 LABEL_STUDIO_ML_BACKEND_V2=True 환경 변수를 추가하면 해결된다.
AssertionError: job returns exception
AssertionError: job returns exception1 | [2024-02-26 23:10:57,401] [ERROR] [label_studio_ml.model::get_result_from_last_job::141] 1708956600 job returns exception: |
Webhook 기능을 끄면 해당 error가 발생하지 않는다.
학습이 완료된 model을 다시 load하여 기존 model을 load하는 현상
1 | 2024-02-26 22:13:37,932 | INFO | LS_ML_BE | Train: Done! [runs/segment/train24/weights/best.pt] |
위와 같이 학습 완료 후 학습된 model을 잘 load했지만 다시 초기 model을 불러오는 issue가 발생했다.
이는 Label Studio version 1.4.1 이후 completions (annotations) 대신 event를 사용하기 때문이다.따라서 해당 version 이후에 event가 입력되면 비어있는 train_output이 출력되어 발생한 문제다.
해결에 실패하여… 환경 변수 정의를 통해 학습이 완료된 model을 load하고 다시 새로운 model을 load하는 것을 방지했다.
LABEL_STUDIO_USE_REDIS=true
LABEL_STUDIO_USE_REDIS=trueProduction level로 나아가서 Docker Compose 및 Kubernetes를 이용한 Label Studio ML Backend를 배포하는 것을 시도했으나 predict()는 잘 수행하지만 fit()을 수행하지 못하는 현상에 의해 실패했다.
아래 code는 Docker Compose를 통해 Label Studio ML Backend를 배포하는 code인데 위의 예시들과 같이 Start Training을 눌러서 fit()을 수행하려 했지만 log 조차 출력되지 않았다.
전체 code
1 | import os |
1 | FROM python:3.8-slim |
1 | version: "3.8" |
이를 해결하기 위해 Settings > Cloud Storage > Add Source Storage > Redis를 시도했지만 오류가 발생하여 LABEL_STUDIO_USE_REDIS=false로 선언하여 해결했다.
RuntimeError: DataLoader worker (pid(s) *) exited unexpectedly
RuntimeError: DataLoader worker (pid(s) *) exited unexpectedly공유 memory 크기 제한으로 발생하는 문제이기 때문에 아래와 같이 공유 memory를 확장하여 해결한다.
1 | apiVersion: apps/v1 |