
Paper Review: SOLAR
SOLAR 10.7B: Scaling Large Language Models with Simple yet Effective Depth Up-Scaling
Introduction
NLP 분야의 언어 이해와 상호작용에 대한 향상시킨 LLM의 도입으로 큰 변화가 진행되고 있다.
이러한 발전은 performance scaling law에 의해 더욱 큰 model 학습의 필요를 증대시켰다.
Mixture of experts (MoE)와 같은 방법을 통해 효율적이고 효과적이게 LLM을 scale-up을 할 수 있지만 종종 특별한 변화가 필요하여 광범위한 적용이 어려운 한계점이 존재한다.
따라서 효과적이고 효율적이게 LLM을 scaling up하며 사용 편의성을 위한 단순성을 유지하는 것은 매우 중요하다.
본 논문의 저자들은 sparse upcycling에 영감을 받아 효과적이고 효율적이며 단순한 LLM up-scale 방법인 depth up-scaling (DUS)를 제안한다.
DUS는 깊이 차원에 따라 base model을 scaling하고 지속적으로 scaled model을 pretraining하는 것으로 구성된다.
하지만 MoE를 통해 scaling하는 sparse upcycling과 다르게 DUS는 EfficientNet에서 사용한 방법과 유사한 depthwise scaling 방법을 LLM 구조에 적용했다.
DUS는 MoE와 같은 추가적인 module이 없으므로 학습 또는 추론 framework를 변경하지 않고도 사용하기 쉬운 Hugging Face와 같은 LLM framework에 즉시 호환된다.
모든 transformer 구조에 적용 가능한 DUS를 통해 저자들은 다양한 benchmark에서 기존 LLM model들 (Llama 2, Mistral 7B)을 뛰어넘는 성능을 보여준 107억개의 parameter를 갖춘 SOLAR 10.7B를 출시했다.
복잡한 지침들을 엄격히 지켜야하는 task들을 수행하기 위해 저자들은 SOLAR 10.7B-Instruct를 개발했으며 Mixtral-8x7B-Instruct model을 크게 능가하고 더 큰 모델에 비해 더 효과적인 것을 benchmark performance를 통해 확인했다.
Depth Up-Scaling
효율적인 LLM의 scale-up을 위해 base model의 pretrain 가중치를 사용한다.
Sparse upcycling와 같이 기존의 LLM model 구조를 확장하는 방법은 MoE를 사용하지만 저자들은 EfficientNet에서 영감을 받은 방법으로 다른 depthwise scaling 전략을 사용하여 확장 후 성능이 저하되므로 지속적 pretraining을 수행한다.
Base Model
DUS가 어떠한 $n$-layer transformer 구조에서도 사용할 수 있지만 저자들은 32-layer Llama 2 구조를 base model로 선정했다.
Llama 2 구조에 호환되는 최고의 성능 중 하나인 Mistral 7B의 pretrained 가중치를 사용했다.
Depthwise Scaling
- $n$: Base model의 layer 수
- $m$: Base model에서 제거할 layer 수
- $s$: Scaled model의 layer 수 (Hardware의 사양에 따라 결정)
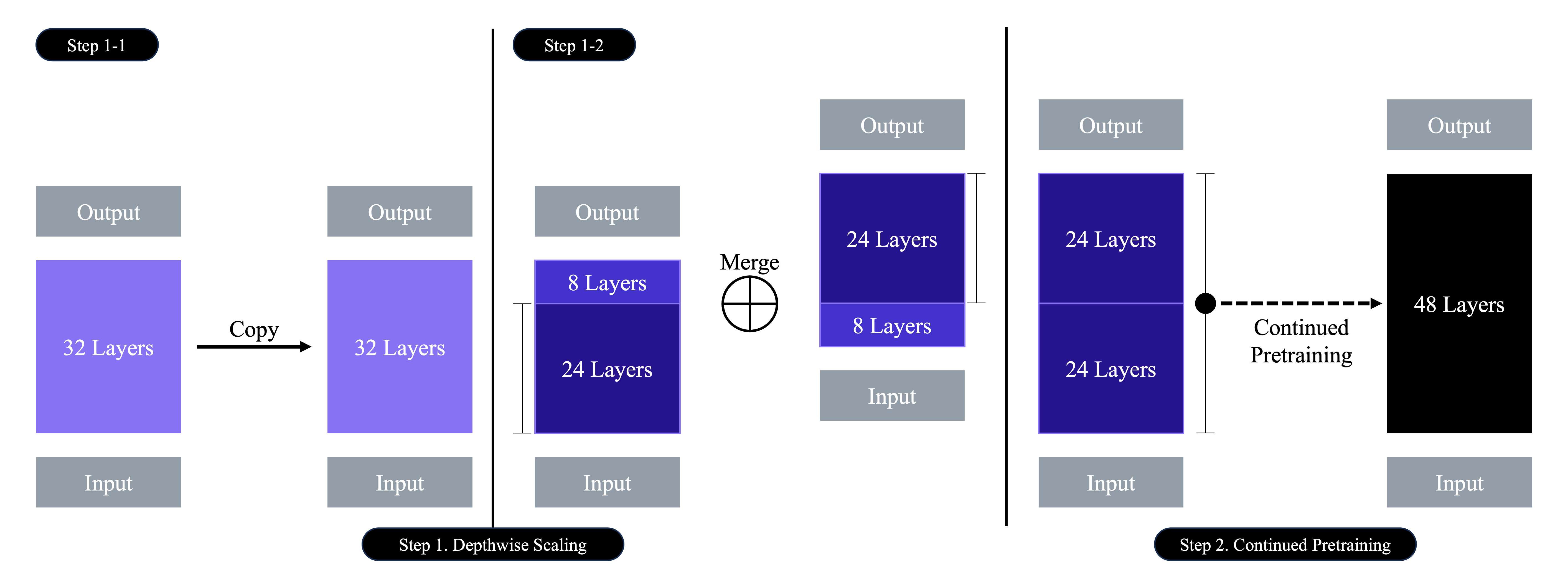
- $n$ layer들을 복제
- 원본 model에서 최종의 $m$ layer들을 삭제
- 복제 model에서 초기의 $m$ layer들을 삭제
- 두 model을 연결하여 $s=2\times(n-m)$ layer로 구성하여 확장 model 구성
저자들은 hardware의 제약과 확장된 model의 효율성을 위해 $m=8$ layer를 제거하여 $s=48$로 설정하였다. ($\because$ Parameter 수: 7 ~ 13B)
또한 Hugging Face에서 동시에 비슷한 방법으로 개발된 Mistral 11B를 함께 수록했다.
Continued Pretraining
Depthwise scaled model은 처음에 base model의 성능보다 떨어지기 때문에 지속적 pretraining을 수행한다.
저자들은 실험을 통해 sparse upcycling에서 관측된 현상과 같이 scaled model의 지속적 pretraing 동안 급속한 성능 회복을 관측했다.
Depthwise scaling의 간단한 대안은 layer를 단순히 반복하여 $n$ layer에서 $2n$ layer로 확장하는 것인데 해당 방법은 이음새 layer ($n$ layer, $n+1$ layer)의 불일치가 발생하며 이를 지속적 pretraining으로 해결하기 어려울 수 있다.
반면 depthwise scaling은 $2m$의 중간 layer를 삭제하기 때문에 이음새 layer의 불일치를 감소시키며 지속적 pretraining으로 이를 해결할 수 있다.
Comparison to Other Up-scaling Methods
Sparse upcycling과 다르게 DUS를 통해 확장된 model은 최적의 훈련 효율성을 위한 training framework, 빠른 추론을 위한 특수 CUDA kernel, gating network 또는 dynamic expert selection과 같은 module이 별도로 필요하지 않다.
따라서 DUS를 통해 확장된 model은 높은 효율성을 유지하며 기존 학습 및 추론 framework에 원활히 통합될 수 있다.
Training Details
DUS를 마치고 저자들은 instruction tuning과 alignment tuning을 수행하여 SOLAR 10.7B를 fine-tuning했다.
Instruction Tuning
Instruction tuning 단계에서는 QA format의 설명으로 model을 학습했다.
Open-source dataset를 주로 사용했으며 수학적 기능을 향상시키기 위해 math QA dataset를 합성했다.
저자들은 dataset을 구축하기 위해 아래 절차를 수행했다.
- Seed math data는 GSM8K와 같은 benchmark dataset과의 오염을 피하기 위해 Math dataset에서만 수집
- MetaMath와 유사한 process를 통해 seed math data의 질문과 답변을 rephrase
저자들은 이렇게 구축한 질문과 답변 쌍을 QA dataset으로 사용했으며 이를 Synth. Math-Instruct라고 명명했다.
Alignment Tuning
Alignment tuning 단계에서는 direct preference optimization (DPO)를 사용하여 사람 또는 GPT4와 같은 강력한 AI의 선호도로 fine-tuning된다.
Instruction tuning 단계와 유사하게 저자들은 open-source dataset과 Synth. Math-Instruct dataset을 사용했다.
Alignment data를 합성하기 위한 절차는 아래와 같다.
- Rephrase된 질문을 prompt로, rephrase된 답변을 chosen response로 설정 ($\because$
Synth. Math-Instructdata의 수학적 기능 향상 효과) - 기존의 답변은 rejected respnse로 설정
{prompt, chosen, rejected}DPO tuple 생성
저자들은 rephrase된 질문과 답변 쌍의 tuple들을 합쳐서 이를 Synth. Math-Alignment라고 명명했다.
Results
Experimental Details
Training Datasets
저자들이 instruction tuning 단계와 alignment tuning 단계에 사용한 학습 dataset들은 아래 표와 같다.
| Properties | Alphaca-GPT4 (Instruction) |
OpenOrca (Instruction) |
Synth. Math-Instruct (Instruction) |
Orca DPO Pairs (Alignment) |
Ultrafeedback Cleaned (Alignment) |
Synth. Math-Alignment (Alignment) |
|---|---|---|---|---|---|---|
| Total # Samples | 52K | 2.91M | 126K | 12.9K | 60.8K | 126K |
| Maximum # Samples Used | 52K | 100K | 52K | 12.9K | 60.8K | 20.1K |
| Open Source | O | O | X | O | O | X |
특정 dataset은 전체 dataset을 사용하진 않았으며 정해진 양을 subsample하여 사용했다.
Open-source가 아닌 dataset은 MetaMathQA dataset와 같은 open-source dataset으로 대체할 수 있다.
Dataset 구축을 위한 기타 정보는 아래와 같다.
- Instruction dataset: Alpaca-styled chat template을 사용해 reformat
- OpenOrca와 같은 dataset: Benchmark dataset과 겹치는 data를 filtering ($\because$ Derived from FLAN)
- Alignment dataset: Zephyr를 따라 전처리 (
{prompt, chosen, rejected}triplet format)
Evaluation
Hugging Face Open LLM Leaderboard는 아래와 같이 여섯 종류의 평가 방법을 제공한다.
| Evaluation Method | Description | Assessment Content |
|---|---|---|
| ARC (AI2 Reasoning Challenge) |
과학 문제 해결을 위한 질문과 답변 | 자연 과학의 다양한 분야에서 추론 능력 평가 |
| HellaSWAG | 상황에 맞는 문장 완성 문제 | 일상 생활, 교육 자료 등에서 추출한 시나리오를 바탕으로 상황 인식 및 언어 이해 능력 평가 |
| MMLUC (Massive Multitask Language Understanding) |
광범위한 주제에 대한 질문과 답변 | 문학, 역사, 과학, 수학 등 다양한 분야의 질문에 대한 이해 |
| TruthfulQA | 진실성을 평가하는 질문과 답변 | 진실성, 정확성, 신뢰성 있는 정보 제공 능력 평가 |
| Winogrande | 상황 기반 선택형 질문 | 상황에 따른 적절한 대명사 선택을 통해 언어 이해력 평가 |
| GSM8K | 초등학교 수준의 수학 문제 | 다양한 수학 문제 해결을 통한 계산 능력 및 수학적 추론 평가 |
저자들은 6가지 task로 model을 평가했다.
Model Merging
TIES-Merging과 같은 model merging 방법으로 추가 학습 없이 model의 성능을 향상시킬 수 있다.
저자들은 instruction tuning 단계와 alignment tuning 단계에서 학습한 model의 일부분을 merge했다.
MergeKit와 같이 유명한 open source도 존재하지만 저자들은 그들만의 merging 방법을 구현했다.
Main Results
저자들은 SOLAR 10.7B model과 SOLAR 10.7B-Instruct model에 대해 평가를 진행했고 Qwen 14B와 Mistral 7B와 같이 비슷한 크기의 pretrained model에 비해 뛰어난 성능을 보인다고 주장한다.
또한 최고 성능의 open-source LLM Mixtral 8x7-Instruct-v0.1 또는 Qwen 72B에 비해 크기가 더 작음에도 불구하고 SOLAR 10.7B-Instruct model은 H6 기준 가장 높은 점수를 기록했다.
따라서 저자들은 이 결과를 통해 DUS가 fine-tuning 시 SOTA 성능을 달성할 수 있는 model을 확장할 수 있다고 주장한다.
Ablation Studies
저자들은 instruction tuning 단계와 alignment tuning 단계에 대해 ablation study를 제공한다.
Instruction Tuning
Ablation on the training datasets.
SFT: Supervised fine-tuning
| Model | Alpaca-GPT4 | OpenOrca | Synth. Math-Instruct |
H6 (Avg.) |
|---|---|---|---|---|
| SFT v1 | O | X | X | 69.15 |
| SFT v2 | O | O | X | 69.21 |
| SFT v3 | O | O | O | 70.03 |
| SFT v4 | O | X | O | 70.88 |
| SFT v3+v4 (Merged) |
O | O | O | 71.11 |
- SFT v1 vs. SFT v2: OpenOrca dataset의 활용 여부에 따라 동작 방식 변화
- SFT v1 vs. SFT v4:
Synth. Math-Instructdataset을 활용하여 GSM8K score 향상 - SFT v3, SFT v4 vs. SFT v3+v4: 동작 방식이 다른 두 model의 merging을 통해 성능 향상
Alignment Tuning
Ablation on the training datasets.
SFT v3를 DPO의 SFT base model로 사용
| Model | Ultrafeedback Clean | Synth. Math-Alignment |
H6 (Avg.) |
|---|---|---|---|
| DPO v1 | O | X | 73.06 |
| DPO v2 | O | O | 73.42 |
| DPO v1+v2 (Merged) |
O | O | 73.21 |
- SFT base model (SFT v3) vs. DPO v1
- H6 3.03 상승
- 대부분의 task에 대해 개선되었지만 GSM8K에 대해서 성능 감소
- DPO v2
Synth. Math-Alignmentdataset의 추가로 GSM8K에 대한 성능이 SFT v3에 비해 낮지만 DPO v1에 비해 향상- 다른 task에 대해 약간의 성능 변화 존재 (부정적 영향 X)
- DPO v1+v2
- DPO v2에 비해 성능 감소
- SFT v3, SFT v4 vs. SFT v3+v4: Model의 장단점이 서로 다른 병합으로 성능 향상
- DPO v1, DPO v2 vs. DPO v1+v2: DPO v2는 DPO v1보다 더욱 엄격히 개선되어 성능 하락
Ablation on the SFT base models.
Ultrafeedback Clean과Synth. Math-Alignmentdataset 사용
| Model | Base SFT Model | H6 (Avg.) |
|---|---|---|
| DPO v2 | SFT v3 | 73.42 |
| DPO v3 | SFT v3+v4 (Merged) |
73.58 |
- SFT v3 vs. SFT v3+v4: 모든 task에 대해 더 높은 성능
- DPO v2 vs. DPO v3
- GSM8K에 대한 약간의 성능 차이를 제외하면 거의 성능 변화가 없음
- 항상 SFT base model의 성능 차이가 alignment-tuned model로 이어지진 않음
Ablation on different merge methods.
동일한 학습 dataset과 SFT base model (DPO v2, DPO v3) 사용
각 model의 장점을 최대화하기 위해 서로 다른 hyper-parameter 사용
| Model | H6 (Avg.) |
|---|---|
| Cand. 1 | 73.73 |
| Cand. 2 | 73.28 |
- Cand. 1 vs. Cand. 2
- GSM8K에 대해 Cand. 1의 성능 우위
- 나머지 task에 대해 Cand. 2의 성능 우위
| Model | Merge Method | H6 (Avg.) |
|---|---|---|
| Merge v1 | Average (0.5, 0.5) | 74.00 |
| Merge v2 | Average (0.4, 0.6) | 73.93 |
| Merge v3 | Average (0.6, 0.4) | 74.05 |
| Merge v4 | SLERP | 73.96 |
- Merge methods
- Average (a, b): Model의 가중치 평균화
- a: Cand. 1의 가중치
- b: Cand. 2의 가중치
- SLERP
- Average (a, b): Model의 가중치 평균화
- 서로 다른 merge 방법이 H6 score에 큰 영향을 주지 않음
- Merge될 각 model들의 충분히 다른 강점이 존재한다면 merge 방법은 중요하지 않을 수 있음
최종적으로 저자들은 Merge v1 model을 SOLAR 10.7B-Instruct model로 선택했다.
Conclusion
저자들은 depth up-scaled (DUS)을 통해 107억 개의 parameter를 가진 SOLAR 10.7B model과 SOLAR 10.7B-Instruct model을 개발했다.
다양한 NLP task에 대해 계산 효율성을 유지하며 Llama 2, Mistral 7B 및 Mistral-7B-Instruct와 같은 model들에 비해 우수한 성능을 확인했다.
따라서 DUS는 소규모 LLM에서 고성능 LLM으로 확장하는데 효과적이다.