
TensorFlow (3)
MNIST 데이터셋
- 훈련용 6만개와 테스트용 1만개로 이루어진 손글씨 숫자의 흑백이미지 데이터 - 여기서 다운
- 이미지를 다루는 경우 데이터 전처리나 포맷팅이 시간이 많이 걸리므로 이 데이터셋을 이용함
- 가로세로 비율은 그대로 유지하고 20x20 픽셀로 정규화(normalization)되어 있음
- 정규화 알고리즘(가장 낮은 것에 맞춰 전체 이미지 해상도를 감소시킴)에 사용된 anti-aliasing 처리 때문에 이미지에 회색 픽셀이 들어 있음
- 이미지의 중심을 계산하여 28x28 픽셀 크기의 프레임 중앙에 위치
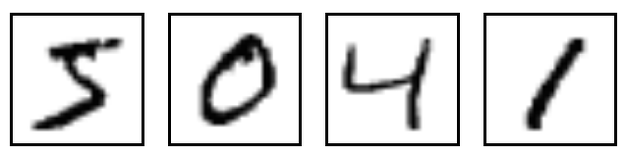
- supervised learning(감독 학습)를 위하여 이미지 데이터에 어떤 숫자인지를 나타내는 label 정보가 들어있음
- 레이블 데이터와 함께 전체 숫자 이미지를 로드
- 훈련 과정 동안 학습 모델은 이미지를 입력받아 각 카테고리(0~9)에 대한점수를 원소로 갖는 벡터 형태로 결과를 출력
- 출력 점수와 기대 점수의 차이를 측정하는 에러함수를 계산
- 학습모델은 이 에러를 줄이기 위해 가중치(weight) 파라미터와 수억개의 레이블된 훈련용 데이터가 있음
- 쉽게 데이터를 다운로드하기 위해
input_data.py스크립트를 사용
1 | from tensorflow.examples.tutorials.mnist import input_data |
- 훈련 데이터가 들어있는
mnist.train과 테스트 데이터가 들어 있는mnist.test를 얻음 - 데이터의 각 엘리먼트는 이미지와 레이블로 구성
- 훈련 이미지는
mnist.train.image로 참조가 가능, 레이블은mnist.train.labels로 참조가 가능
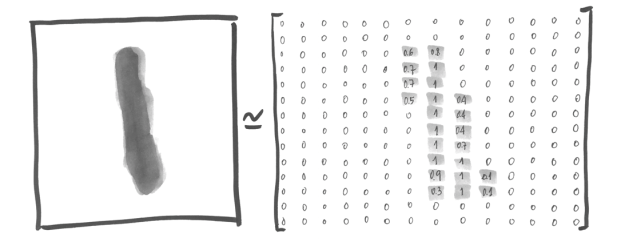
- 0과 1 사이의 값으로 각 픽셀의 검은 정도가 표시됨
- 28x28 = 784개의 숫자 배열로 표현될 수 있음
- 이미지가 784차원의 벡터 공간에 있는 일련의 포인트들로 변환된 것
- 이미지를 2차원 구조로 표현하면 일부 정보를 잃어버릴 수 있어 어떤 컴퓨터 비전 알고리즘에는 결과에 영향을 미칠 수 있음
1 | import tensorflow as tf |
(55000, 784)의 결과를 얻을 수 있으며 첫 번째 차원은 각 이미지에 대한 인덱스이며 두 번째 차원은 이미지 안의 픽셀의 밝기(0~1)를 나타냄(흰색이 0, 검은색이 1)- 레이블을 10개의 엘리먼트(0~9)로 구성된 벡터로 표현
- 벡터는 레이블 숫자에 대응되는 위치에 1의 값을 가지고 그 외에는 0값을 가짐(2의 레이블 벡터는 [0,0,1,…,0])
1 | import tensorflow as tf |
(55000, 10)의 결과를 얻을 수 있으며 위에 설명한 것과 같이 55000가지의 레이블이 10종류로 나열되어 있다고 이해하면 됨
인공 뉴런
뉴런은 가중치
W와 오프셋b를 학습시켜 어떻게 포인트들을 분류하는지를 배움
(b는 뉴럴 네트워크에서 bias라고 불림)
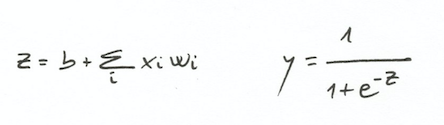
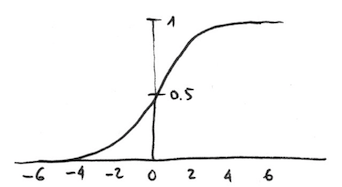
- 가중치
W를 사용하여 입력 데이터X의 가중치 합을 계산하고 오프셋b를 더함 0또는1의 결과로 만들기 위해 비선형 활성화 함수를 적용함(sigmoid function)
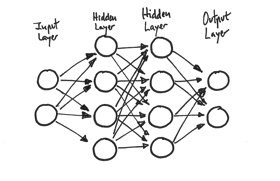
- Neural Network는 여러가지 방식으로 연결되어 있고 각기 다른 활성화 함수들을 사용하는 뉴런들을 합쳐 놓은 것
- 입력을 받는 하위 layer(Input layer), 결괏값을 내는 상위 layer(Output layer)처럼 여러개의 layer로 뉴런을 구성
- Neural Network는 Hidden layer라 불리는 여러개의 중간 layer를 가질 수 있음
softmax
- 입력 이미지가 주어졌을 때 0~9까지 각 숫자와 얼마나 비슷한지에 대한 확률을 얻기
- 상호 배타적인 레이블에 대한 결과로 확률 분포를 담은
출력 벡터를 가짐 - 10개의 확률 값을 가진
출력 벡터는 각각 0에서 9까지의 숫자에 대응되는 것이고 확률의 전체 합은 1임 출력 벡터는 출력 레이어를 softmax 활성화 함수로 구성하여 얻어짐- softmax함수를 사용한 뉴런의 출력값은 그 레이어의 다른 뉴런의 출력값에 영향을 받게 되고 그들의 출력값의 합은 1이 돼야함
- 이미지가 어떤 레이블에 속하는지 근거(evidence)들을 계산
- 근거들을 각 레이블에 대한 확률로 변환
클래스 소속 근거(evidence of belonging)
- 픽셀의 진한 정도에 대한 가중치 합을 계산
- 어떤 클래스 픽셀에는 없는 진한 픽셀이 이미지에 있다면 가중치는 음의 값이 되고 클래스의 진한 픽셀이 이미지와 자주 겹친다면 가중치는 양의 값

- 붉은 색은 음의 가중치를 나타내고 푸른색은 양의 가중치를 나타냄
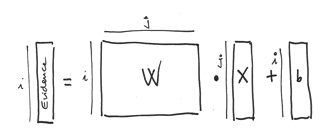
- 각
i(0~9)에 대해 784개 엘리먼트(28x28)를 가지는 행렬W(i)를 얻음 W의 각 엘리먼트j는 입력 이미지의 784개의 컴포넌트j에 곱해지고b(i)가 더해짐
클래스 소속 확률
y=softmax(evidence)
- softmax함수를 사용하여 근거들의 합을
예측 확률 y로 산출 출력 벡터는 합이 1인 확률 함수가 되어야 함
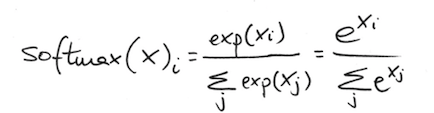
- 각 컴포넌트를 정규화하기 위해 softmax함수는 입력 값을 모두 지수 값을 바꾸어 정규화함
- 지수 함수를 사용하면 가중치를 크게하는 효과를 얻을 수 있음
- 한 클래스의 근거가 작을 때 이 클래스의 확률도 더 낮아짐
- softmax는 가중치의 합이 1이 되도록 정규화하여 확률 분포를 만들어 줌
- 예측이 잘 되면 1에 가까운 값이 하나가 있게 되고 다른 출력값은 0에 가깝게 되지만 예측값이 뚜렷하지 않을 때는 여러 레이블이 비슷한 확률을 가지게 됨
TensorFlow Programming
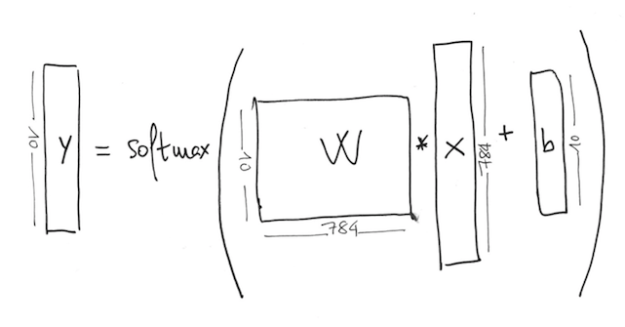
1 | W = tf.Variable(tf.zeros([784,10])) |
- 가중치
W와 바이어스b를 저장할 변수 2개를 만듦 - 이 변수들은
tf.Variable함수를 사용하여 생성되었고 초깃값을 가짐(모두 0으로 setting된 상수 텐서를 초깃값으로 함)
1 | x = tf.placeholder("float", [None, 784]) |
x포인트에 대한 정보를 저장하기 위한 2차원 텐서- 텐서
x는 MNIST 이미지를 784개의 실수 벡터로 저장하는데 사용 - None이라고 지정한 것은 어떤 사이즈나 가능하다는 것으로 여기서는 학습 과정에 사용될 이미지의 갯수
1 | y = tf.nn.softmax(tf.matmul(x,W) + b) |
tf.nn.softmax(logits, name=None)함수는 softmax함수를 구현한 것- 텐서 하나가 파라미터로 주어져야하며 이름은 선택사항
- 입력한 텐서와 같은 크기와 종류의 텐서를 리턴
- 이미지 벡터
x와 가중치 행렬W를 곱하고b를 더한 텐서를 입력 - 반복하여 훈련하는 알고리즘을 이용하여 가중치
W와 바이어스b를 얻을 수 있는 코드가 필요 - 반복이 일어날 때마다 훈련 알고리즘은 훈련 데이터를 받아 Neural Network에 적용하고 결과를 기댓값과 비교하게 됨
코스트 함수를 사용하여 얼마나 모델이 나쁜지를 측정코스트 함수를 최소화하는W와b를 얻는 것이 목적- 보통 Neural Network에서는 Cross entropy error(교차 엔트로피 에러)같은 측정 방식을 사용함
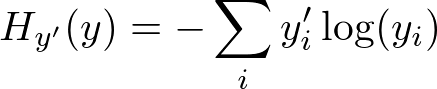
y(i)는 예측된 확률 분포,y'(i)는 레이블링 된 훈련 데이터로부터 얻은 실제 분포y=y'일때 최솟값을 얻음- 설명
1 | y_ = tf.placeholder("float", [None,10]) |
- 교차 엔트로피 함수를 구현하기 위해 실제 레이블을 담고 있는 새로운 플레이스홀더
1 | cross_entropy = -tf.reduce_sum(y_*tf.log(y) |
tf.log()를 사용해 y의 각 엘리먼트 로그값을 구함y_의 각 엘리먼트와 곱함tf.reduce_sum함수를 사용하여 텐서의 모든 엘리먼트를 더함
1 | train_step = tf.train.GradientDescentOptimizer(0.01).minimize(cross_entropy) |
- 샘플에 대한 에러가 계산되면 다음번 루프 반복에서 기댓값과 계산된 값의 차이를 줄이기 위해 모델을 반복적으로 수정(파라미터
W와b를 수정) backpropagation(백프로파게이션)(에러를 후방으로 전파하는 것) 알고리즘을 사용- 출력값으로부터 얻은 에러를 가중치
W를 재계산하기위해 뒤쪽으로 전파시키는 것(특히 Multi layer에서 중요) - 학습속도 0.01과 그래디언트 디센트 알고리즘을 사용하여 크로스 엔트로피를 최소화하는 백프로파게이션 알고리즘 사용
minimize()메소드가 실행될때 텐서플로우는 손실함수(loss function)에 연관된 변수들을 인식하고 각각에 대해 기울기를 계산
1 | sess = tf.Session() |
- 알고리즘을 모두 작성하고
tf.Session()으로 세션을 시작하면 시스템에서 사용 가능한 디바이스에서 텐서플로우의 연산을 실행
1 | sess.run(tf.global_variables_initializer()) |
- 모든 변수 초기화
1 | for i in range(1000): |
train_step에서 산출된 파라미터는 그래디언트 디센트 알고리즘에 다시 참여- 모델을 훈련시키려면
train_step을 반복적으로 샐행 - 루프 시작 첫번째 코드에서 훈련 데이터셋으로부터 무작위로 100개를 추출함
- 루프가 반복될때마다 전체 데이터를 사용할 수도 있음
- 100개의 샘플 데이터를 플레이스홀더에 사용하여 주입
- 그래디언트 디센트 기반의 머신러닝 알고리즘은 텐서플로우의 자동화된 미분 기능 이용
모델 평가
1 | correct_prediction = tf.equal(tf.argmax(y,1), tf.argmax(y_,1)) |
- Boolean 리스트를 리턴
- 예측한 것이 얼만큼 맞았는지 확인하려면 Boolean을 수칫값(부동소수점)으로 아래와 같이 변경
1 | accuracy = tf.reduce_mean(tf.cast(correct_prediction, "float")) |
- ex)
[True, False, True, True] = [1,0,1,1]이고 평균값은 0.75로 정확도의 퍼센트를 나타냄
1 | print(sess.run(accuracy, feed_dict={x: mnist.test.images, y_: mnist.test.labels})) |
feed_dict파라미터로mnist.test를 전달하여 테스트 데이터셋에 대한 정확도를 계산
전체 코드
1 | import tensorflow as tf |
- 실행결과
1 | 0.9167 |
과정 Printing
1 | import tensorflow as tf |
참고
영상