
TensorFlow (2)
Clustering
- 선형 회귀분석은 모델을 만들기 위해 입력 데이터와 출력 값(label)을 사용해 감독(Supervised) 학습 알고리즘
- 모든 데이터에 레이블이 있지 않음
- 비감독(Unsupervised) 학습 알고리즘
- 데이터 분석의 사전 작업으로 사용되기 좋음
K-means Clustering
- 데이터를 다른 묶음과 구분되도록 유사한 것끼리 자동으로 Grouping
- 알고리즘에 예측해야 할 타겟 변수나 결과 변수가 없음
- 텐서(Tensor) 이용
Tensor
- 동적 사이즈를 갖는 다차원 데이터 배열
| 텐서플로우 타입 | 파이썬 타입 | 설명 |
|---|---|---|
| DT_FLOAT | tf.float32 | 32비트 실수 |
| DT_INT16 | tf.int16 | 16비트 정수 |
| DT_INT32 | tf.int32 | 32비트 정수 |
| DT_INT64 | tf.int64 | 64비트 정수 |
| DT_STRING | tf.string | 문자열 |
| DT_BOOL | tf.bool | 불리언 |
- 각 텐서는 배열의 차원을 나타내는 랭크(rank)를 가짐
- 텐서의 랭크는 제한이 없음
- 랭크가 0이면 스칼라, 1이면 벡터, 2이면 행렬을 나타냄
- 텐서들을 다루기 위해 텐서플로우에선 변환 함수를 사용
K-means 알고리즘
- 주어진 데이터를 지정된 클러스터 갯수(K)로 Grouping
- 한 클러스터 내의 데이터들은 동일한 성질을 가지며 다른 그룹에 대하여 구별됨
- 센트로이드(Centroid)라 불리는 K개의 포인트로 서로 다른 그룹의 중심을 나타냄
- 데이터들은 K 클러스터 중 하나에만 속할 수 있음
- 클러스터를 구성하는데 직접 에러 함수를 최소화하려면 계산을 매우 많이 해야함
- 스스로 로컬 최솟값에 빠르게 수렴할 수 있는 방법이 개발됨(iterative refinement)
- 초기 단계 : K 센트로이드의 초기 값을 결정
- 할당 단계 : 가까운 클러스터에 데이터를 할당
- 수정 단계 : 각 클러스터에 대해 새로운 센트로이드 계산
- 데이터 중 K개를 임의로 선택하여 센트로이드로 삼아 초기값을 정함
- 할당 단게와 수정 단계는 알고리즘이 수렴되어서 클러스터 내의 데이터의 변화가 없을 때 까지 루프 안에서 반복됨
1 | import numpy as np |
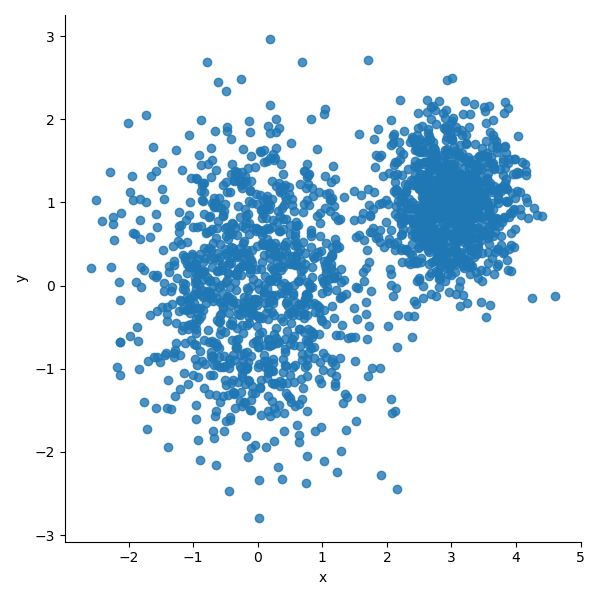
- 샘플 데이터 생성
- 두 개의 정규분포를 이용하여 2D 좌표계에 2000개의 포인트를 난수로 발생
1 | vectors = tf.constant(conjunto_puntos) |
vectors = tf.constant(conjunto_puntos)를 이용하여 무작위로 생성한 데이터를 가지고 상수 텐서를 만듦centroides = tf.Variable(tf.slice(tf.random_shuffle(vectors),[0,0],[k,-1]))를 이용하여 입력 데이터를 무작위로 섞어서 K개의 센트로이드를 선택- K개의 데이터 포인트는 2D 텐서로 저장됨
vectors는 D0 차원에 2000개의 배열을 가지고 있고 D1 차원에는 각 포인트의 x, y 좌표의 값을 가지고 있음centroids는 D0 차원에 4개, D1 차원에vectors와 동일한 2개의 배열을 가진 행렬
1 | expanded_vectors = tf.expand_dims(vectors, 0) |
- 각 포인트에 대해 유클리디언 제곱거리(Square Euclidean Distance)로 가장 가까운 센트로이드 계산하기 위해
tf.subtranct(vectors, centroids)를 사용 - 빼려는 두 텐서가 모두 2차원이지만 1차원 배열의 갯수가 다르므로
tf.expand_dims함수를 사용하여 두 텐서에 차원을 추가 - 2차원에서 3차원으로 만들어 뺄셈을 할 수 있도록 사이즈를 맞춰줌
vectors텐서에는 첫 번째 차원(D0)를 추가하고centroids텐서에는 두 번째 차원(D1)을 추가- 크기가 1이라는 것은 크기가 결정되지 않았다는 것을 의미
- 크기가 정해지지 않음을 이용하여 다른 차원의 수를 맞춤
1 | diff=tf.subtract(expanded_vectors, expanded_centroides) |
tf.subtract함수는expaned_vectors와expanded_centroids를 뺀 값을 가진diff텐서 리턴(D0 차원에는 센트로이드, D1 차원에는 데이터 인덱스, D2 차원에는 x, y값을 가진 텐서)sqr텐서는diff텐서의 제곱 값을 가짐distances텐서에서는tf.reduce_sum메소드에 파라미터로 지정된 차원(D2)가 감소된 것을 볼 수 있음
1 | assignments = tf.argmin(tf.reduce_sum(tf.square(tf.subtract(expanded_vectors, expanded_centroides)), 2), 0) |
- 위의 4줄로 쓴 코드는 이와같이 나타낼 수 있음
1 | means = tf.concat([tf.reduce_mean(tf.gather(vectors, tf.reshape(tf.where( tf.equal(assignments, c)),[1,-1])), reduction_indices=[1]) for c in range(k)], 0) |
- K개의 클러스터에 속한 모든 포인트의 평균을 가지고있는 K개의 텐서를 합친
means텐서 정의
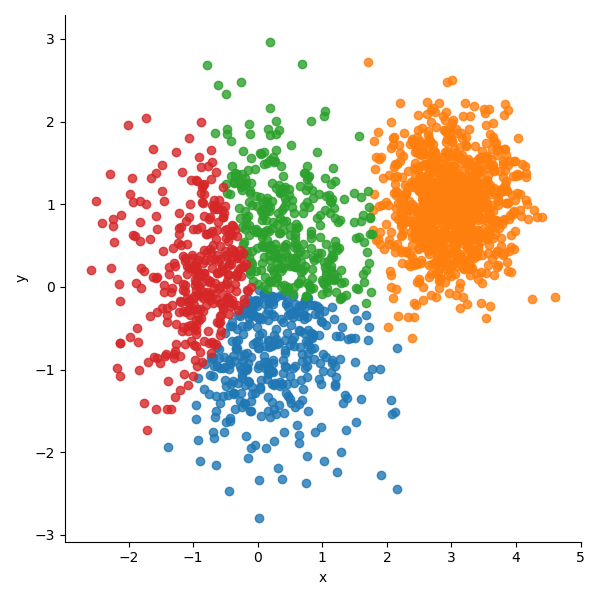
참고