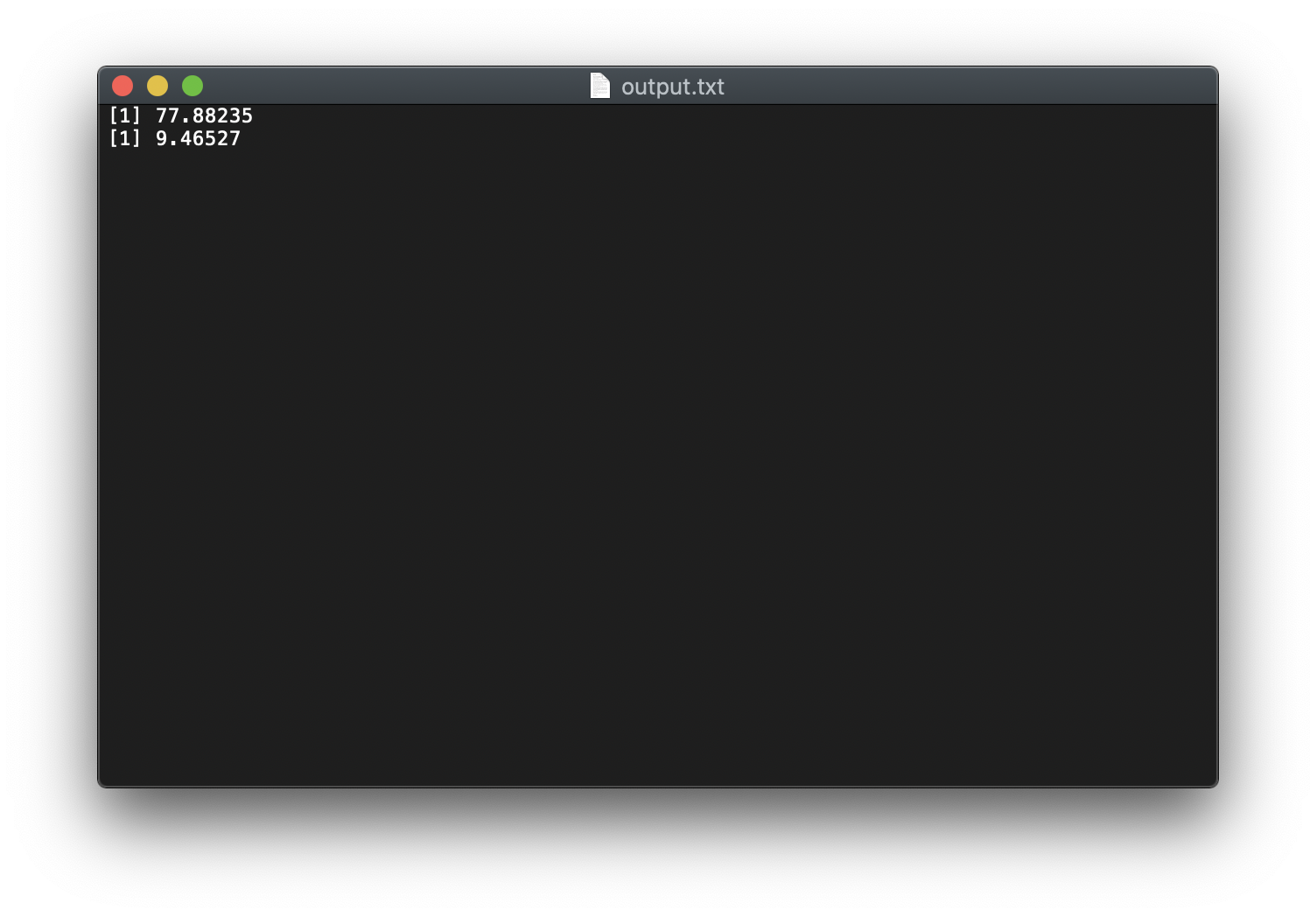
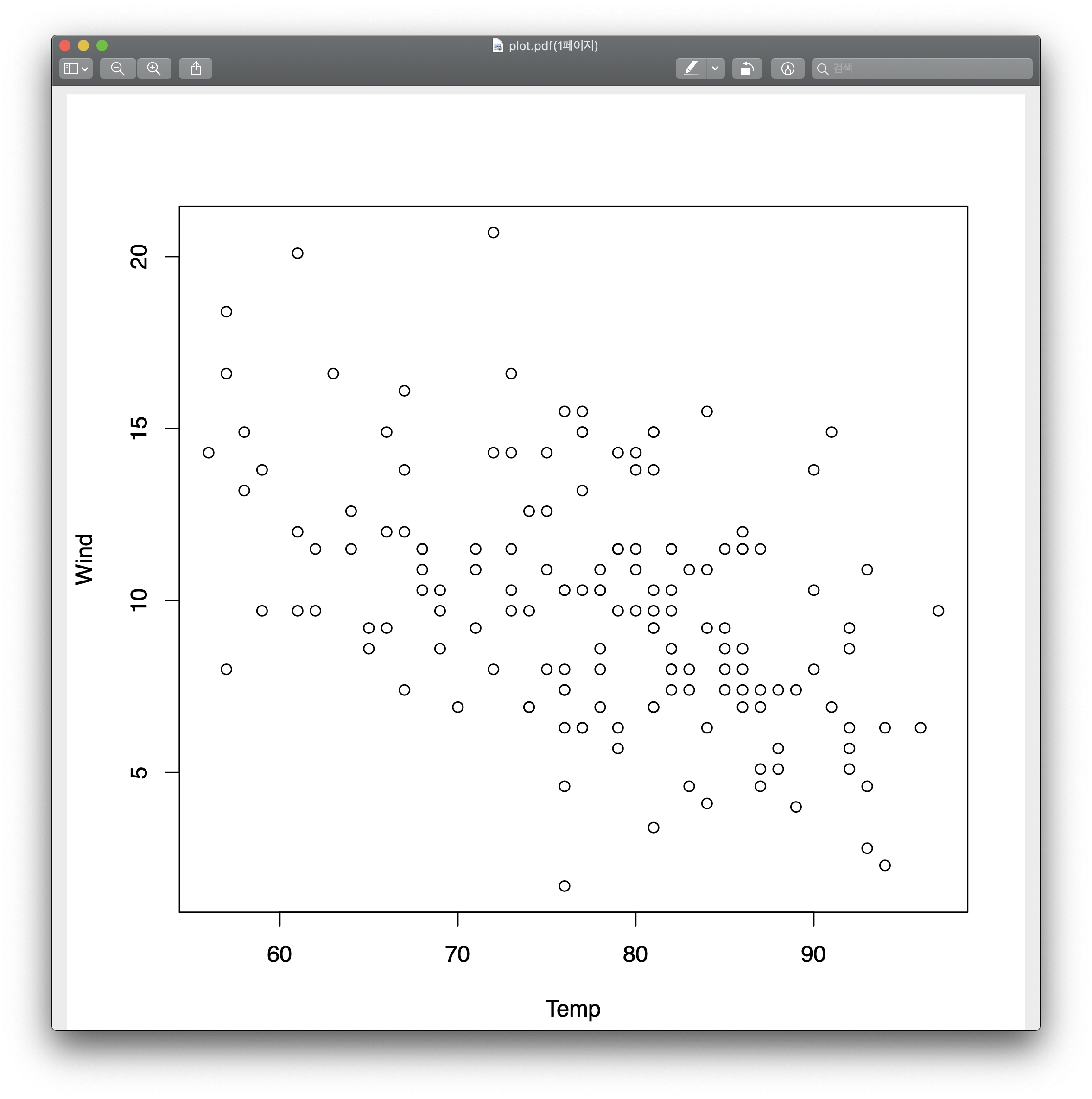
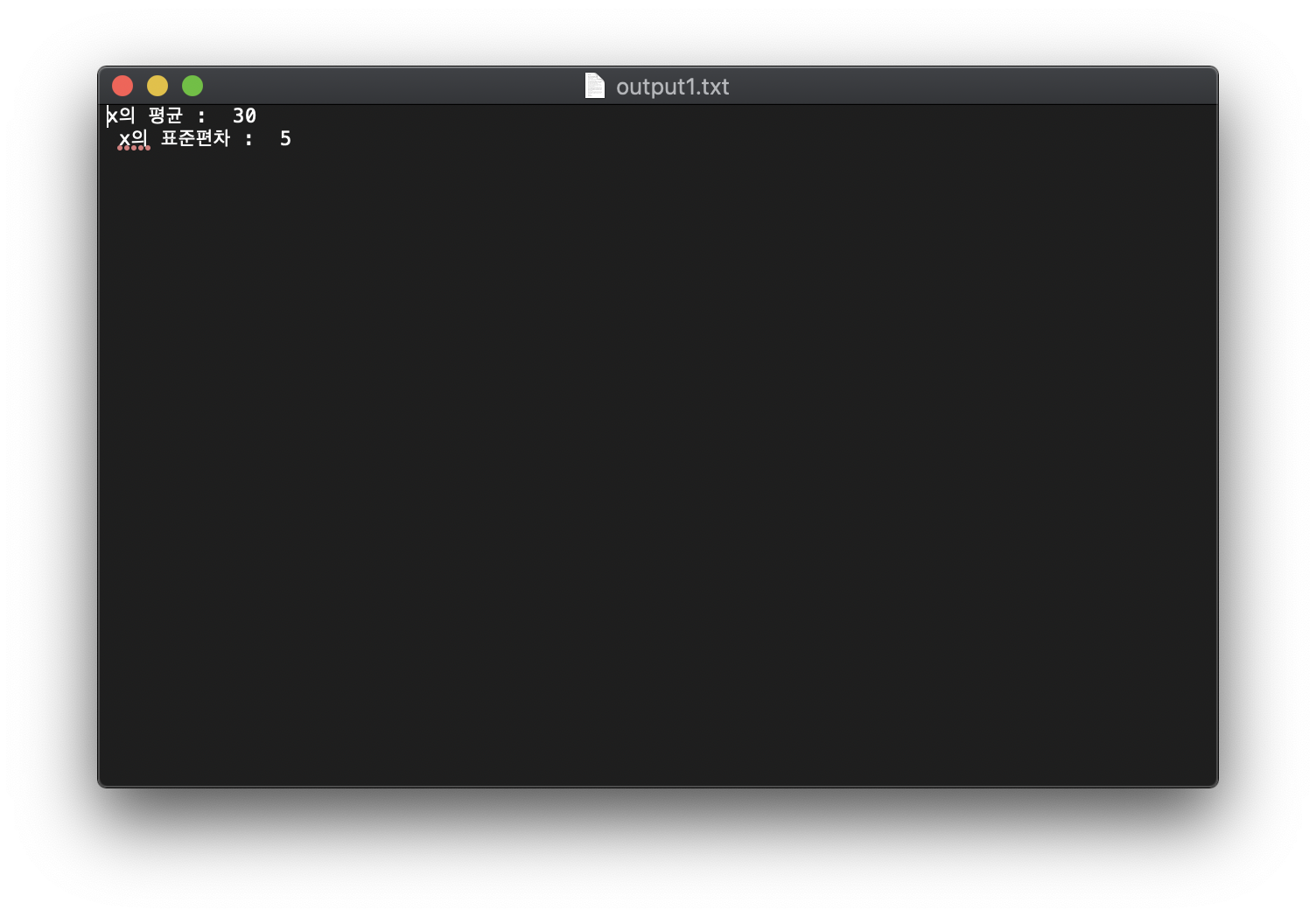
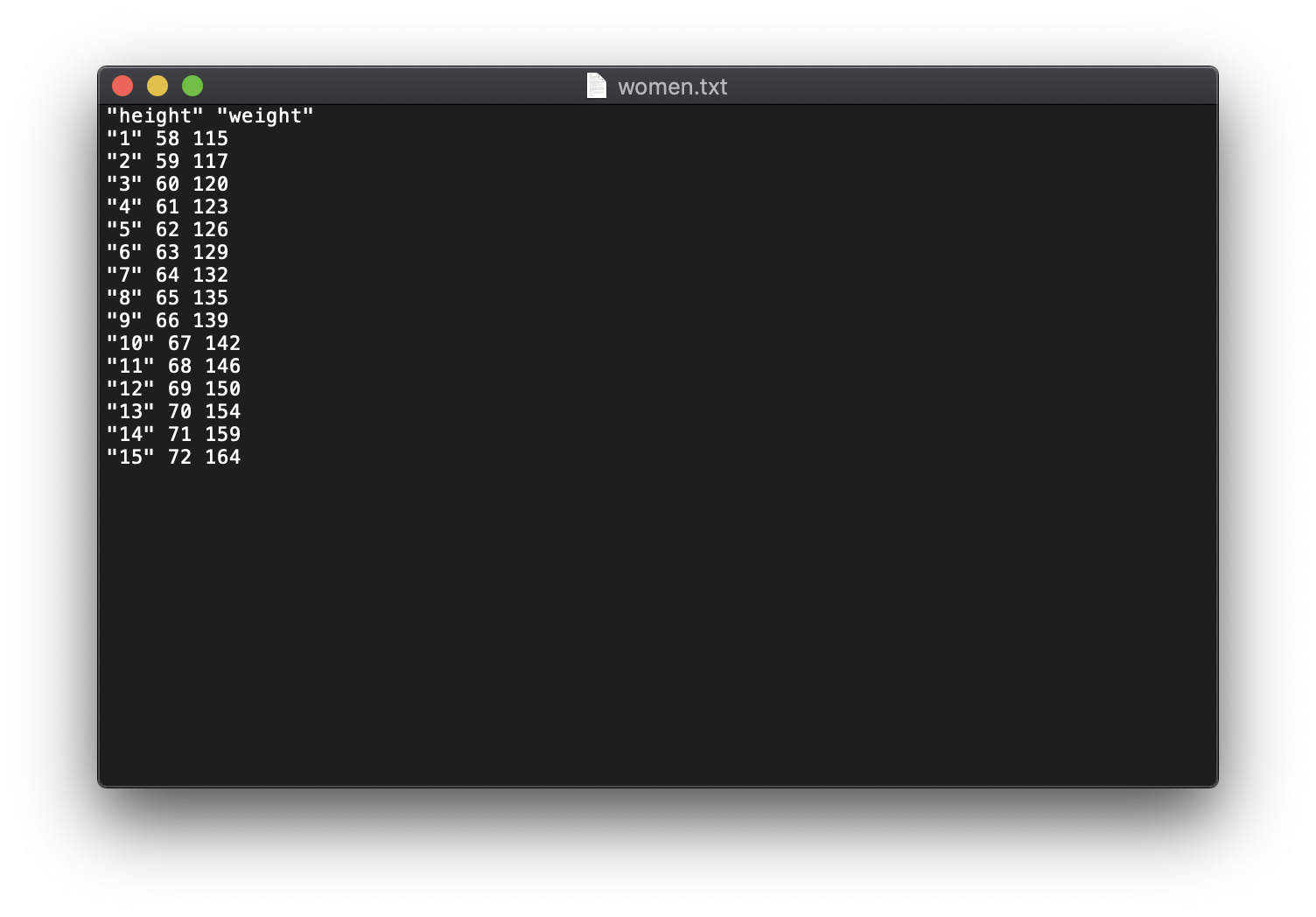
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
| > substr('응용통계학',1,3)
[1] "응용통"
> time='201912311504'
> year=substr(time,1,4);year
[1] "2019"
> month=substr(time,5,6);month
[1] "12"
> day=substr(time,7,8);day
[1] "31"
> hour=substr(time,9,10);hour
[1] "15"
> sec=substr(time,11,12);sec
[1] "04"
> z=c('응용통계학','정보통계학')
> substr(z,c(1,3),c(2,5))
[1] "응용" "통계학"
> cities=c('New York,NY','Ann Arbor,MI','Chicago,IL')
> states=substr(cities,nchar(cities)-1,nchar(cities));states
[1] "NY" "MI" "IL"
> city=strsplit(cities,split=',');city
[[1]]
[1] "New York" "NY"
[[2]]
[1] "Ann Arbor" "MI"
[[3]]
[1] "Chicago" "IL"
|