위와 동일하게 CUDA 11.2를 사용하고 있어 TensorRT를 설치하기 위해 TensorRT 7.2.3 for Ubuntu 18.04 and CUDA 11.1 & 11.2 TAR package를 다운로드 받았다.
Reference
Download
1 2 3 4 5 6 7 8 9 10 11 12 13
~$ tar -xvzf TensorRT-7.2.3.4.Ubuntu-18.04.x86_64-gnu.cuda-11.0.cudnn8.1.tar.gz ~$ pip3 install --upgrade pip ~$ vi ~/.bashrc export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:${설치된 위치}/TensorRT-7.2.3.4/lib ~$ source ~/.bashrc ~$ cd TensorRT-7.2.3.4/python ~/TensorRT-7.2.3.4/python$ python3 -m pip install tensorrt-7.2.3.4-cp38-none-linux_x86_64.whl ~/TensorRT-7.2.3.4/python$ cd ../uff ~/TensorRT-7.2.3.4/uff$ python3 -m pip install uff-0.6.9-py2.py3-none-any.whl ~/TensorRT-7.2.3.4/uff$ cd ../graphsurgeon ~/TensorRT-7.2.3.4/graphsurgeon$ python3 -m pip install graphsurgeon-0.4.5-py2.py3-none-any.whl ~/TensorRT-7.2.3.4/graphsurgeon$ cd ../onnx_graphsurgeon ~/TensorRT-7.2.3.4/onnx_graphsurgeon$ python3 -m pip install onnx_graphsurgeon-0.2.6-py2.py3-none-any.whl
1 2 3 4 5 6 7
~$ python Python 3.8.6 | packaged by conda-forge | (default, Nov 272020, 19:31:52) [GCC 9.3.0] on linux Type"help", "copyright", "credits"or"license"for more information. >>> import tensorrt >>> tensorrt.__version__ '7.2.3.4'
하지만 최종 목표인 PyTorch 모델을 TensorRT로 변환하기 위해서는 torch2trt 모듈을 설치해야한다. 따라서 아래와 같이 진행해준다.
Reference
1 2 3
~$ git clone"https://github.com/NVIDIA-AI-IOT/torch2trt" ~$ cd torch2trt ~/torch2trt$ python setup.py install
1 2 3 4 5
~$ python Python 3.8.6 | packaged by conda-forge | (default, Nov 272020, 19:31:52) [GCC 9.3.0] on linux Type"help", "copyright", "credits"or"license"for more information. >>> from torch2trt import torch2trt
torch2trt
Reference
torch2trt는 아래와 같이 import하여 PyTorch 모델을 TensorRT로 변환할 수 있다.
현재 가중치를 로드한 모델 (with torch.no_grad():)이 사용하는 입력은 imgs, img_metas, cfg인데 img_metas는 후처리 과정에서만 사용되고 후처리 과정은 type이 변환되기 때문에 후처리 과정 자체를 별도 (TensorRT 외부)로 실행시켜 해결할 수 있고, cfg는 PAN_PP 객체 내부에 해당하는 값들을 고정하여 입력받지 않도록 코드를 변환할 수 있다. 이렇게 모델 구조를 적절히 변경하여 torch.tensor를 입력받고 torch.tensor를 출력해야한다.
Let’s Convert to TensorRT!
모든 준비가 되었으니 아래와 같이 torch2trt() 함수를 이용하여 TensorRT로 변환해보자.
[TensorRT] INTERNAL ERROR: Assertion failed: nbResizeDim >= 0 ../builder/Layers.cpp:4061 Aborting... Traceback (most recent call last): File "TensorRT.py", line 73, in <module> trt_model = torch2trt( File "/opt/conda/lib/python3.8/site-packages/torch2trt-0.4.0-py3.8.egg/torch2trt/torch2trt.py", line 778, in torch2trt outputs = module(*inputs) File "/opt/conda/lib/python3.8/site-packages/torch/nn/modules/module.py", line 1071, in _call_impl result = forward_call(*input, **kwargs) File "/home/jovyan/local/1_user/hgoh@agilesoda.ai/TwinReader/PANPP_TensorRT/models/pan_pp.py", line 64, in forward f1, f2, f3, f4 = self.fpem1(f1, f2, f3, f4) File "/opt/conda/lib/python3.8/site-packages/torch/nn/modules/module.py", line 1071, in _call_impl result = forward_call(*input, **kwargs) File "/home/jovyan/local/1_user/hgoh@agilesoda.ai/TwinReader/PANPP_TensorRT/models/neck/fpem_v2.py", line 70, in forward f3_ = self.smooth_layer3_1(self.dwconv3_1(self._upsample_add(f4, f3))) File "/home/jovyan/local/1_user/hgoh@agilesoda.ai/TwinReader/PANPP_TensorRT/models/neck/fpem_v2.py", line 67, in _upsample_add return F.interpolate(x, size=(H, W), mode='bilinear') + y File "/opt/conda/lib/python3.8/site-packages/torch2trt-0.4.0-py3.8.egg/torch2trt/torch2trt.py", line 310, in wrapper converter["converter"](ctx) File "/opt/conda/lib/python3.8/site-packages/torch2trt-0.4.0-py3.8.egg/torch2trt/converters/interpolate.py", line 77, in convert_interpolate_trt7 layer.set_input(1, shape._trt) File "/opt/conda/lib/python3.8/site-packages/torch2trt-0.4.0-py3.8.egg/torch2trt/torch2trt.py", line 1019, in _trt self._raw_trt = ctx.network._network.add_concatenation([d._trt for d inself]).get_output(0) RuntimeError: std::exception
ChatGPT 선생님 왈...
이 오류는 TensorRT를 사용하는 도중에 발생한 것입니다. 오류 메시지에서는 “nbResizeDim >= 0“ 단언문이 실패했다는 것을 알려줍니다. 이 단언문은 TensorRT에서 사용되는 크기 조정 작업에 관련된 것입니다. 이 오류는 TensorRT에서 입력 데이터를 처리하면서 발생할 수 있습니다. 입력 데이터의 크기가 예상되지 않은 경우에 발생할 가능성이 높습니다. 예를 들어, 모델을 실행할 때 입력 크기를 변경하거나, TensorRT를 사용하여 모델을 컴파일 할 때 입력 크기를 정의하는 방법을 변경하는 경우에 발생할 수 있습니다. 오류가 발생하는 정확한 코드 부분을 파악하기 위해, 스택 추적 정보를 살펴봐야 합니다. 여기서는 torch2trt 및 F.interpolate 함수에서 오류가 발생한 것으로 보입니다. 이 경우, F.interpolate 함수를 TensorRT에서 사용 가능한 형식으로 변환하는 데 실패했을 가능성이 있습니다. 해결 방법으로는, 입력 데이터의 크기를 확인하고 TensorRT에서 사용 가능한 형식으로 변환하기 전에 입력 데이터의 크기를 변경해야 할 수도 있습니다. 또는, TensorRT에서 F.interpolate 함수를 처리하는 데 필요한 추가 구성을 수행해야 할 수도 있습니다. 디버깅에 도움이 되는 로그를 활성화하고, TensorRT 버전을 최신으로 업그레이드하면 도움이 될 수 있습니다.
이 문제를 해결하기 위해 torch_tensorrt라는 모듈을 찾게 되었고, torch2trt와의 차이점을 여기서 알아볼 수 있다. 위 글에서 알 수 있듯 torch2trt가 프로토타입에 적합하다하여 가급적이면 해당 모듈로 진행하기 위해 use_onnx 옵션을 사용해 진행해보았다. 이를 위해 모델의 Upsampling 과정을 이렇게 수정했다.
[TensorRT] ERROR: ../rtSafe/cublas/cublasLtWrapper.cpp (74) - cuBLAS Error in CublasLtWrapper: 1 (Could not initialize cublasLt. Please check CUDA installation.) [TensorRT] ERROR: ../rtSafe/cublas/cublasLtWrapper.cpp (74) - cuBLAS Error in CublasLtWrapper: 1 (Could not initialize cublasLt. Please check CUDA installation.)
1 2
[TensorRT] ERROR: safeContext.cpp (124) - Cudnn Error in initializeCommonContext: 4 (Could not initialize cudnn, please check cudnn installation.) [TensorRT] ERROR: safeContext.cpp (124) - Cudnn Error in initializeCommonContext: 4 (Could not initialize cudnn, please check cudnn installation.)
1 2 3 4 5 6 7
[TensorRT] ERROR: CUDA initialization failure with error 2. Please check your CUDA installation: http://docs.nvidia.com/cuda/cuda-installation-guide-linux/index.html Traceback (most recent call last): File "TensorRT.py", line 75, in <module> trt_model = torch2trt( File "/opt/conda/lib/python3.8/site-packages/torch2trt-0.4.0-py3.8.egg/torch2trt/torch2trt.py", line 727, in torch2trt builder = trt.Builder(logger) TypeError: pybind11::init(): factory function returned nullptr
최상단의 리스트 내부에 튜플을 입력하여 최소, 최대, 적절한 텐서의 크기를 기입했고, 앞서 문제가 되었던 Upsampling 과정을 torch.nn.functional.interpolate() 함수가 아닌 torch.nn.Upsample() 함수로 교체하여 텐서 추적을 아래와 같이 가능케 했다.
models/pan_pp.py
1 2 3 4 5 6 7 8 9 10 11 12 13 14
# Before ... def_upsample(self, x, size, scale=1): _, _, H, W = size return F.interpolate(x, size=(H // scale, W // scale), mode='bilinear') ...
# After ... def_upsample(self, x, size, scale=1): _, _, H, W = size.size() upsample = nn.Upsample(size=(H // scale, W // scale), mode='bilinear') return upsample(x) ...
models/neck/fpem_v2.py
1 2 3 4 5 6 7 8 9 10 11 12 13 14
# Before ... def_upsample_add(self, x, y): _, _, H, W = y.size() return F.interpolate(x, size=(H, W), mode='bilinear') + y ...
# After ... def_upsample_add(self, x, y): _, _, H, W = y.size() upsample = nn.Upsample(size=(H, W), mode='bilinear') return upsample(x) + y ...
이렇게 변경한 이유는 아래에 기술했다. 무작정 상수를 torch.tensor로 바꿔주는게 정답이 아니며, torch.Tensor를 활용해도 정답은 아닌듯 하다.
ChatGPT 선생님의 가르침...
위의 _upsample_add() 함수는 PyTorch의 내장 함수 F.interpolate()를 사용하고 있기 때문에 추적 불가능한 nn.functional 모듈의 함수입니다. 따라서 이 함수를 사용하면 torch.jit.trace() 함수에서 TracerWarning이 발생합니다.
이 경우에는 F.interpolate() 대신 nn.Upsample()을 사용하여 추적 가능한 텐서로 변환할 수 있습니다. nn.Upsample()은 F.interpolate()와 같은 기능을 제공하지만, 모델 추적 과정에서도 추적 가능한 텐서로 처리됩니다.
또한 onnx_opset을 11로 정의해 아래 오류를 해결했다.
Error Log
1 2 3 4 5 6 7 8 9 10 11 12 13 14
/opt/conda/lib/python3.7/site-packages/torch/onnx/symbolic_helper.py:375: UserWarning: You are trying to export the model with onnx:Upsample for ONNX opset version 9. This operator might cause results to not match the expected results by PyTorch. ONNX's Upsample/Resize operator did not match Pytorch's Interpolation until opset 11. Attributes to determine how to transform the input were added in onnx:Resize in opset 11 to support Pytorch's behavior (like coordinate_transformation_mode and nearest_mode). We recommend using opset 11 and above for models using this operator. "" + str(_export_onnx_opset_version) + ". " [TensorRT] ERROR: Network must have at least one output [TensorRT] ERROR: Network validation failed. Traceback (most recent call last): File "TensorRT.py", line 118, in <module> torch.save(trt_model.state_dict(), "test.pth") File "/opt/conda/lib/python3.7/site-packages/torch/nn/modules/module.py", line 1261, in state_dict hook_result = hook(self, destination, prefix, local_metadata) File "/opt/conda/lib/python3.7/site-packages/torch2trt-0.4.0-py3.7.egg/torch2trt/torch2trt.py", line 571, in _on_state_dict state_dict[prefix + "engine"] = bytearray(self.engine.serialize()) AttributeError: 'NoneType' object has no attribute 'serialize'
Results
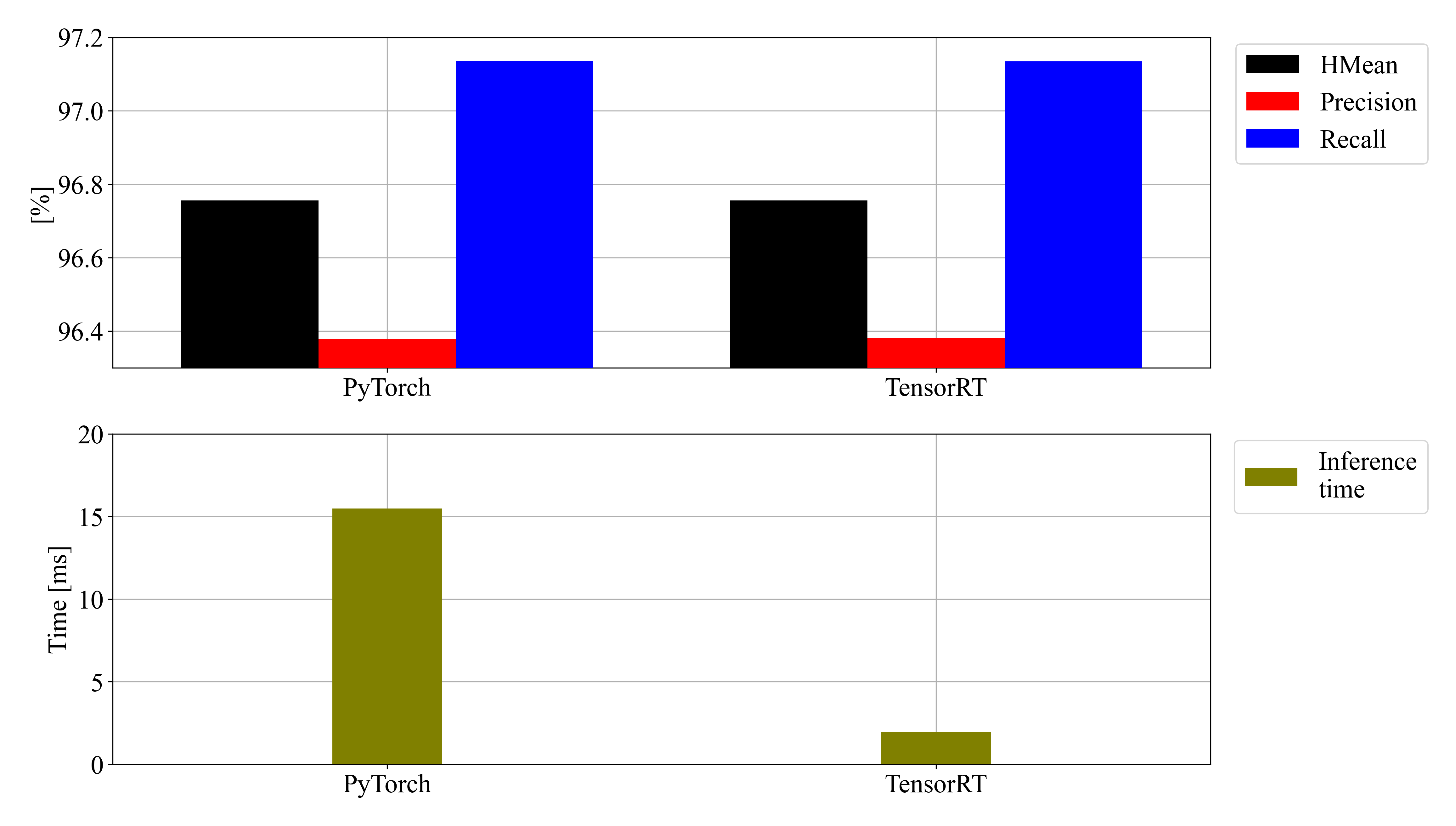
이렇게 PyTorch로 작성된 모델이 TensorRT로 변환되었다고 해서 모두 끝이 아니라 모델이 잘 작동하는지, 얼마나 빠르게 작동하는지 확인해봐야한다. 그를 위해 아래와 같이 test를 위한 스크립트를 작성했다. 이 과정을 통해 PyTorch 및 TensorRT 모델의 inference time을 측정하고, 결과물을 생성할 수 있다.
위 코드에서 알 수 있듯, TensorRT로 변환된 모델은 torch2trt.TRTModule()로 인스턴스를 생성하고 일반적인 PyTorch 모델이 가중치를 불러오는 것과 비슷하게 TRTModule.load_state_dict(torch.load('trt_model.trt'))로 불러올 수 있다. 최종적으로 출력된 결과 (bbox)들에 대해 정량적 평가 (CLEval)를 진행하였고, 결과는 아래와 같다.
HMean
Precision
Recall
Time
PyTorch
96.756 [%]
96.378 [%]
97.136 [%]
15.478 [ms]
TensorRT
96.756 [%]
96.381 [%]
97.135 [%]
1.964 [ms]
Difference
0.001 [%p]
0.003 [%p]
-0.001 [%p]
-13.514 [ms]
Percentage
0.001 [%]
0.003 [%]
-0.002 [%]
-87.313 [%]
아주 약간의 성능 변화 (아마 텐서 연산량 감소를 위해 여러가지 기법이 적용되면서 발생하는 현상으로 추정)가 있지만, 87%의 시간 감소를 확인했다.