
Implementing Mask R-CNN with PyTorch
Introduction
Mask R-CNN?
Mask R-CNN은 Faster R-CNN에 Segmentation 네트워크를 추가한 딥러닝 알고리즘으로, 객체 검출 (Object detection)과 분할을 모두 수행할 수 있습니다.
기존 Faster R-CNN은 RPN (Region Proposal Network)을 사용하여 객체의 경계 상자 (Bounding box)를 추출하고, 추출된 경계 상자를 입력으로 사용하여 객체 인식을 수행합니다. 이러한 방식은 객체의 위치와 클래스 정보를 검출할 수 있지만, 객체 내부의 픽셀-레벨 Segmentation 정보는 제공하지 않습니다.
Mask R-CNN은 Faster R-CNN의 RPN 뿐만 아니라, RoIAlign (Rectangle of Interest Alignment)을 사용하여 추출된 경계 상자 내부의 픽셀-레벨 Segmentation 정보를 추출할 수 있는 분할 네트워크를 추가합니다. 이를 통해, 객체 검출과 동시에 객체 내부의 픽셀-레벨 Segmentation 정보를 추출할 수 있습니다.
또한, Mask R-CNN은 이를 위해 Faster R-CNN과 함께 사용되는 합성곱 신경망 (Convolutional Neural Network)을 미세 조정 (Fine-tuning)하여 분할 네트워크의 성능을 최적화합니다.
Mask R-CNN은 객체 검출과 분할 작업에서 매우 강력한 성능을 보여주며, COCO (Common Objects in Context) 데이터셋에서 현재 가장 높은 정확도를 보이고 있습니다. 따라서, 객체 검출과 분할이 모두 필요한 다양한 응용 분야에서 활용되고 있습니다.
1 | ├── makeGT.py |
Mask R-CNN의 training, test, visualization, evaluation을 진행할 수 있게 PyTorch를 사용하여 위와 같은 구조로 개발하는 과정을 기록한다.
사용될 데이터는 ISIC 2016 Challenge - Task 3B: Segmented Lesion Classification이며 예시는 아래와 같다.
1 | ├── ISBI2016_ISIC_Part3B_Test_Data |
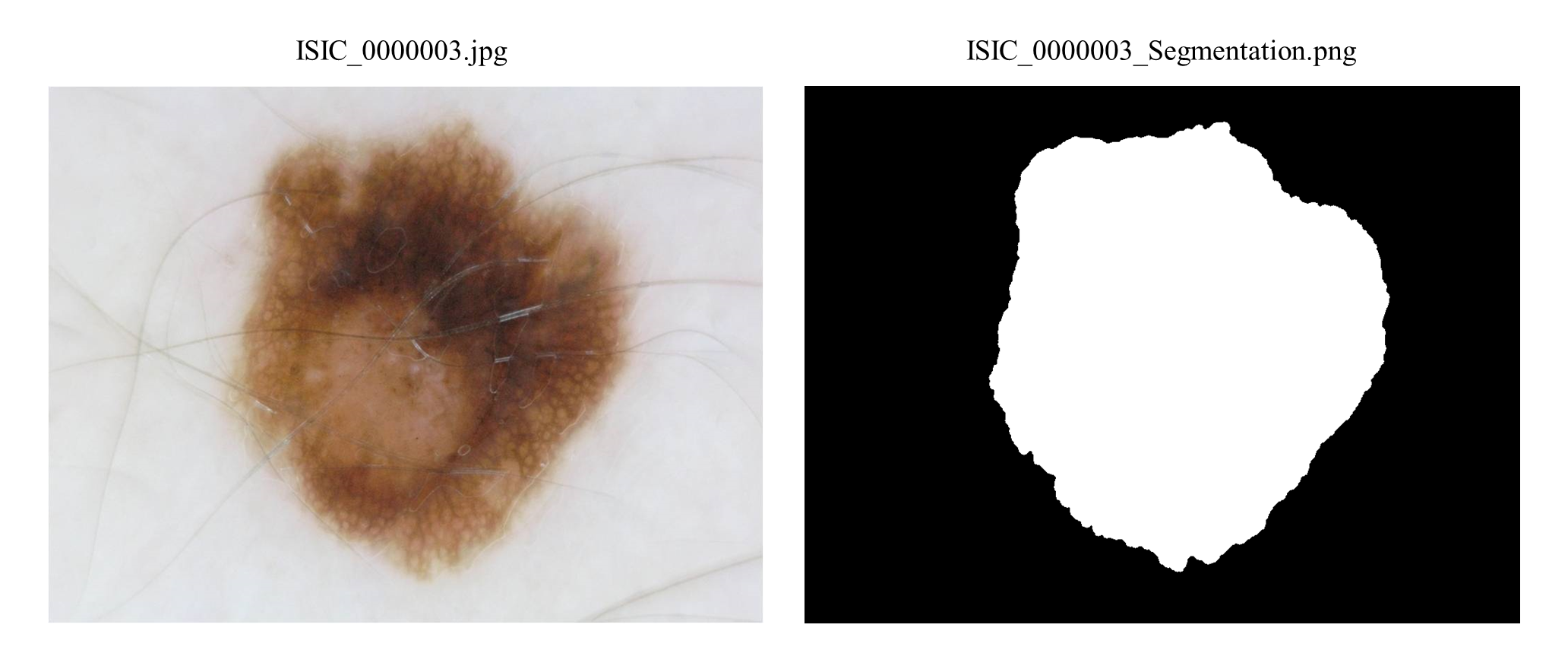
이 데이터는 두 가지 클래스 (benign, malignant)로 구성되어 있고 위 사진에서 알 수 있는 것처럼 분할된 mask를 함께 제공한다.
Mask R-CNN이 Segmentation 정보를 학습 및 테스트할 수 있도록 TrainingData와 TestData를 구성했고, 그를 위한 코드는 아래와 같다.
1 | import os |
위의 코드를 실행하면 아래와 같이 학습 및 테스트를 위한 데이터 디렉토리를 구성할 수 있다.
1 | ├── TestData |
Customized Dataset
이렇게 구성된 Dataset을 Load하기 위해 CustomizedDatset이라는 클래스를 개발해야한다.
1 | import os |
PyTorch로 구성된 Mask R-CNN이 학습 및 테스트 시 사용할 수 있기 위해 torch.utils.data.Dataset을 상속하였다.
인스턴스를 생성할 때 root를 입력받고, images 디렉토리와 masks 디렉토리 내부의 os.listdir()로 이미지와 마스크의 리스트들을 프로퍼티로 입력한다.
또한 학습 시 데이터 증강을 위해 transforms 프로퍼티를, 정규화를 위한 Normalize 프로퍼티를 추가했다.
1 | class CustomizedDataset(torch.utils.data.Dataset): |
가장 중요한 부분인 __getitem__() 메서드에서는 인덱스를 입력해주면 이미지 (img)와 메타 정보들 (target)을 출력해준다.
인스턴스 생성 시 정렬된 이미지와 마스크들 리스트 (self.imgs, self.masks)와 self.root를 통해 절대 경로 (img_path, mask_path)를 산출하고 PIL.Image로 각 해당하는 이미지를 불러왔다.
이후 Numpy로 간단한 데이터 핸들링을 거치고 torch.tensor로 변환 후 각 메타 정보에 해당하는 값들을 딕셔너리인 target에 입력해준 뒤 리턴해준다.
이렇게 개발된 CustomizedDataset의 예시는 아래와 같다.
1 | from model import CustomizedDataset |
CustomizedDataset의 데이터 증강을 위한 get_transform() 함수는 아래와 같이 구성되어있다.
1 | from utils import transforms as T |
마지막으로 학습 과정에서 학습과 테스트를 위한 torch.utils.data.DataLoader를 한번에 불러올 수 있는 load_data() 함수를 개발했다.
1 | from utils import utils |
Init Model
학습 및 테스트를 위한 데이터들은 준비를 완료했으니 학습 및 테스트를 할 모델을 구축해야한다.
따라서 아래와 같이 init_model() 함수를 통해 모델을 생성해줄 수 있다.
1 | import torchvision |
maskrcnn_resnet50_fpn(weights="DEFAULT") 메서드를 통해 COCO로 pre-trained 모델을 불러오고 분류기를 재정의해준다.
이는 bbox 및 mask 예측 모듈의 클래스 수가 변하기 때문에 신경망 구조가 필연적으로 변경되기 때문이다.
또한 모델의 원활한 학습과 테스트를 위해 utils 모듈을 준비한다.
Train
학습 및 테스트를 위한 데이터를 준비했고, 모델 또한 준비를 했으니 이제는 학습을 할 수 있다.
학습을 아래와 같이 구성할 수 있다.
1 | import argparse |
우선적으로 학습 코드를 실행시킬 때 몇가지 옵션을 간단히 수정하기 위해 argparse 모듈 기반 opts() 함수를 개발하였다.
이렇게 정의된 변수를 통해 학습 및 테스트 데이터, 모델, 그리고 학습을 위한 조건을 정의하였고 최종적으로 model.train.train() 함수로 학습을 진행한다.
해당 함수는 아래와 같이 구성된다.
1 | import torch |
학습 과정을 모니터링하기 위하여 TensorBoard를 기용하여 매 epoch 마다의 learning rate, 모델 내 다양한 loss, 최종 loss, precision, recall을 출력할 수 있도록 하였다.
TensorBoard의 시각화 예시는 아래와 같다.
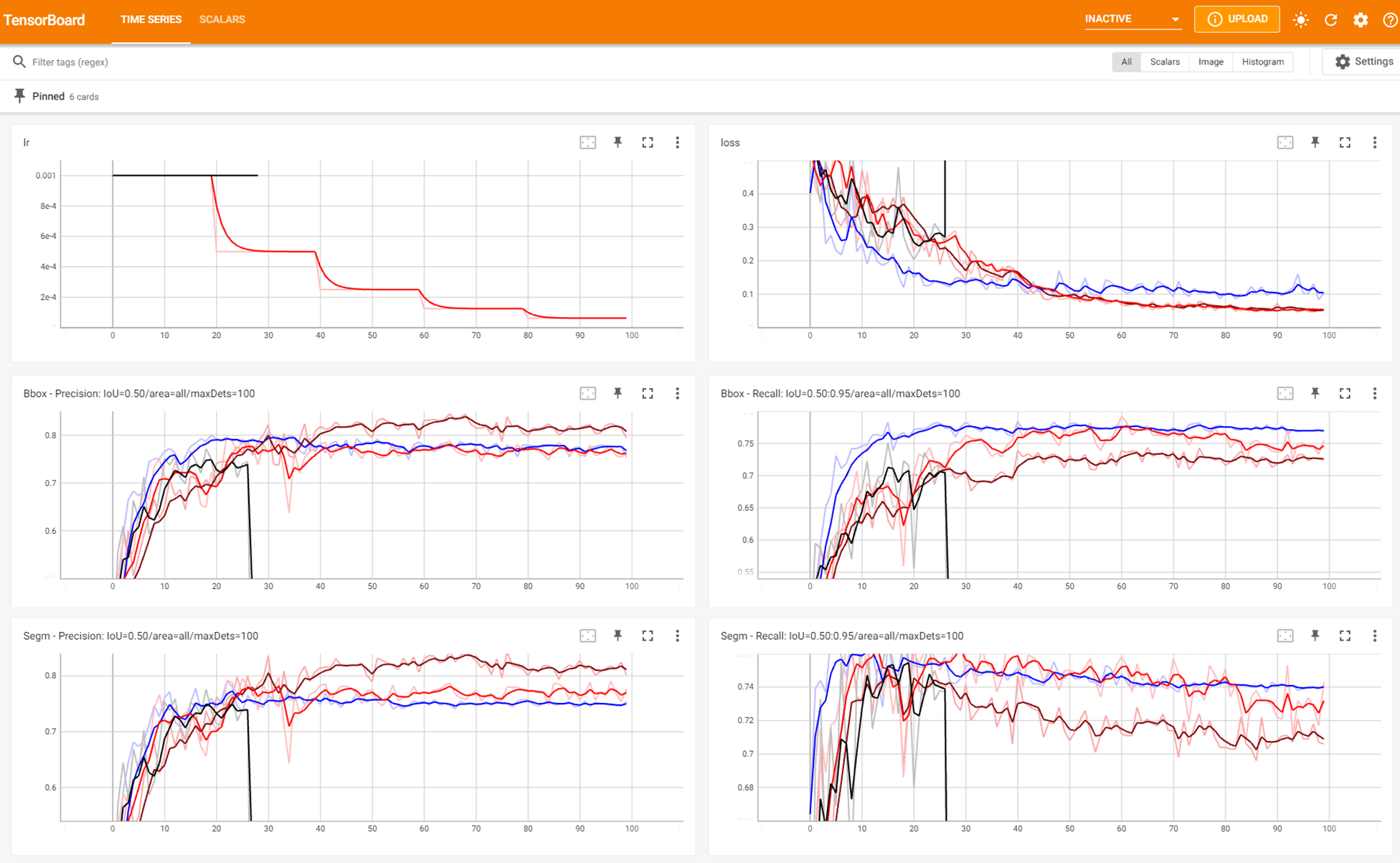
- SGD (lr=0.001, step_size=20)
- Adam (lr=0.001, step_size=30)
- Adam (lr=0.001, step_size=20)
- Adam (lr=0.001, step_size=20, Normalize)
또한 학습 과정 중 가중치를 저장하기 위해 매 20 epoch 마다 torch.save()를 실행할 수 있도록 개발했다.
Test
이제 온전히 학습된 가중치가 있으니 테스트 데이터에 대해 테스트를 진행할 수 있다.
테스트는 아래와 같이 진행할 수 있다.
1 | import argparse |
학습 코드와 유사하게 opts() 함수로 테스트 시 변수들을 입력할 수 있게 개발했고, 테스트 데이터 및 모델 불러온 후 최종적으로 model.test.test() 함수로 테스트를 진행한다.
테스트 코드를 개발하기 위해서는 두 가지가 필요하다.
- 모델의 출력을 시각화할 수 있는 함수
- 모델의 출력을 정량적으로 평가할 수 있는 함수
따라서 model.test.test() 함수는 아래와 같이 개발하였다.
1 | import os |
먼저 draw_gt() 함수는 기본적으로 모델 테스트 결과와 비교하기 위해 개발했다.
데이터 내의 mask와 label을 실제 사진에 입히고 시각화하는 함수다.
다음으로 get_results() 함수는 CocoEvaluator로 평가된 값들을 불러오고 TensorBoard에 출력할 수 있도록 데이터를 핸들링해주는 함수다.
입력으로 평가가 완료된 utils.coco_eval.CocoEvaluator 인스턴스를 받으면 내부의 결과 값들을 불러오고 해당하는 평가 지표의 이름과 함께 리턴해준다.init_output() 함수는 Mask R-CNN의 결과를 NMS로 후처리해주고, 출력된 결과를 CPU로 이동 후 Numpy 배열로 변환하고 리턴해준다.draw_res() 함수는 init_output() 함수에서 정리된 결과를 토대로 시각화하는 함수다.draw_gt() 함수와 같은 양식으로 시각화할 수 있도록 개발했다.
최종적으로 test() 함수에서 테스트 데이터에 대해 결과를 산출하고, 시각화한 뒤 정량적으로 평가하여 .csv 형식으로 저장하는 것을 확인할 수 있다.draw_gt() 함수와 draw_res() 함수를 통해 출력한 결과의 예시는 아래와 같다.
Reference
- PyTorch