
Deep Learning with PyTorch
Load Data
1 | import torch |

1 | fig_size = plt.rcParams["figure.figsize"] |
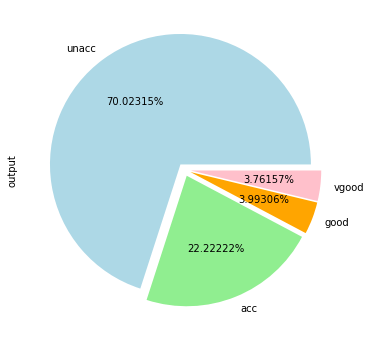
Data Tensorization
1 | categorical_columns = ['price', 'maint', 'doors', 'persons', 'lug_capacity', 'safety'] |
1 | tensor([[3, 3, 0, 0, 2, 1], |
1 | outputs = pd.get_dummies(dataset.output) |
1 | torch.Size([1728, 6]) |
Embedding Setup
1 | categorical_column_sizes = [len(dataset[column].cat.categories) for column in categorical_columns] |
1 | [(4, 2), (4, 2), (4, 2), (3, 2), (3, 2), (3, 2)] |
1 | print(dataset[categorical_columns[0]]) |
1 | 0 vhigh |
Data Segmentation
1 | total_records = len(dataset) |
1 | 1383 |
Model Construction
1 | class Model(nn.Module): |
1 | Model( |
Training Options Setup
1 | loss_function = nn.CrossEntropyLoss() |
1 | device(type='mps') |
Training!
1 | %%time |
1 | epoch: 1 loss: 1.48282647 |
Validation
1 | test_output_acc = test_output_acc.to(device = device, dtype = torch.int64) |
1 | Loss: 0.49808758 |
1 | from sklearn.metrics import classification_report, confusion_matrix, accuracy_score |
1 | [[230 52] |