
Python의 빠른 연산을 위한 Process 기반 병렬 처리
Introduction
회사에서 약 17,000장 가량의 고화질 이미지 데이터를 처리해야하는 일이 생겼는데 총 처리 시간이 약 10시간 가량 소요됐다.
너무 오랜 시간이 소요되기 때문에 이를 빠르게 바꿔보고자 병렬 처리를 해보려고 했다.
먼저 생각난 키워드는 multithreading이여서 threading 라이브러리에 대해 찾아보게 되었다.
하지만 python은 한 thread가 python 객체에 대한 접근을 제어하는 mutex인 GIL (Global Interpreter Lock)이 존재하여 CPU 작업이 적고 I/O 작업이 많은 처리에서 효과를 볼 수 있다. (더 이상은 너무 어려워요,,,)
Cython에서는 이렇게 nogil=True로 정의해 GIL를 해제하고 병렬 처리를 할 수 있다.
그렇다면 현재 문제인 대량의 고화질 이미지 데이터를 최대한 빠르게 처리하려면 어떻게 해야할까?
이 경우에는 process 기반의 병렬 처리를 지원하는 multiprocessing 라이브러리를 사용하면 된다.
multiprocessing
성능 비교를 위한 간단한 multiprocessing의 예제는 다른 글에 많아 본 글에서는 바로 어떻게 이 문제를 해결했는지 설명하겠다.
먼저 task를 수행할 main() 함수에 4가지 변수가 사용되어 multiprocessing.Pool.map() 메서드를 사용하지 못하여 multiprocessing.Pool.starmap() 메서드를 사용했다.multiprocessing.Pool(processes=${NUM_POOL})을 통해 process의 수를 정의할 수 있다. (multiprocessing.cpu_count() 메서드를 통해 현재 기기의 CPU 코어 수를 확인할 수 있다.)
마지막으로 process가 처리할 이미지를 정의하기 위해 args의 마지막 인덱스에 각 process가 처리할 이미지의 인덱스를 포함시켰다.
1 | import multiprocessing as mp |
multiprocessing의 성능을 확인하기 위해 이미지 100장에 대해 실험을 진행했고 결과는 아래와 같다.
1 | ORG: 210.292초 |
확실히 multiprocessing를 사용하지 않는 것 (ORG)에 비해 빠름을 확인할 수 있고, process의 수를 증가시킴에 따라 처리 시간이 짧아짐을 확인할 수 있다.
하지만 CPU 코어 수는 아래와 같이 64개인데 process의 수를 128로 설정해도 잘 실행됐고 오히려 빨랐다. (ChatGPT는 이러지 말라긴 하는데,,,)
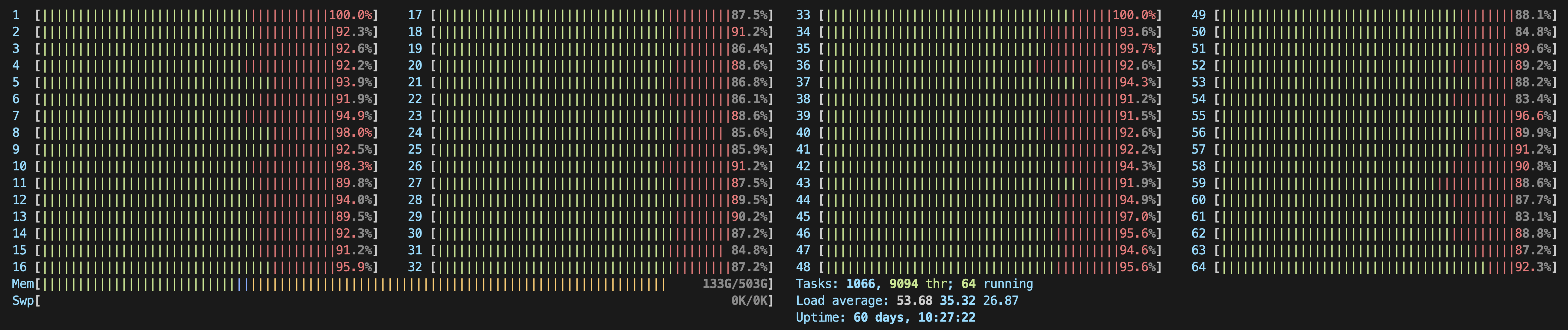
불타는 CPU
혹은 아래와 같이 진행해도 같다. (굳이 )starmap 메서드를 쓸 이유가 없었다…
1 | import multiprocessing as mp |
Progress Bar
단일 process에서 반복문을 실행할 때 tqdm 라이브러리를 사용하여 진행 상황을 확인할 수 있다.
하지만 병렬 처리 시 확인하기 쉽지 않아 아래와 같은 방법을 찾았다.
1 | import multiprocessing as mp |
1 | from tqdm.contrib.concurrent import process_map |
1 | import parmap |
실행 시간 자체는 모두 동일한 것으로 확인했다.