
Paper Review: PagedAttention
Efficient Memory Management for Large Language Model Serving with PagedAttention
Introduction
GPT $_[$$_{5}$$_,$$_{37}$$_]$, PaLM $_[$$_{9}$$_]$과 같은 large language models (LLMs)의 등장으로 programming assistant $_[$$_{6}$$_,$$_{18}$$_]$와 범용적인 chatbot $_[$$_{19}$$_,$$_{35}$$_]$과 같은 새로운 applications로 인해 우리의 일과 일상에 큰 영향을 미치기 시작했다.
다양한 cloud 회사들 $_[$$_{34}$$_,$$_{44}$$_]$이 hosted services로 이러한 applications를 제공하기 위해 경쟁 중이지만, 매우 비싸고 GPU와 같은 hardware 가속기가 매우 많이 필요하다.
최근 추정에 따르면 LLM 요청 처리 비용은 기존 keyword query보다 10$\times$ 더 비쌀 수 있다 $_[$$_{43}$$_]$.
따라서 이러한 높은 비용을 고려했을 때, LLM serving system의 throughput을 높이고 요청당 비용을 줄이는 것이 더욱 중요해지고 있다.
LLM의 core에는 autoregressive Transformer model $_[$$_{53}$$_]$이 있고, 이 model은 입력 (prompt)과 지금까지 생성한 출력 tokens의 이전 sequence를 기반으로 한 번에 하나씩 단어들 (tokens)을 생성한다.
매 요청마다 이러한 값비싼 process는 termination token을 출력하기 전까지 반복되며 이러한 순차적 생성 process는 workload를 memory에 집중시켜 GPU의 연산 능력을 충분히 활용하지 못하고 throughput을 제한한다.
pie "Parameters (26GB, 65%)" : 65 "KV Cache (>30%)" : 30 "Others" : 5Figure 1. Memory layout when serving an LLM with 13B parameters on NVIDIA A100. The parameters persist in GPU memory throughout serving. The memory for the KV cache is (de)allocated per serving request
Throughput은 다수의 요청을 batching하여 개산할 수 있지만 batch 내에서 다수의 요청을 처리하려면 각 요청을 위한 memory가 효율적으로 관리되어야한다.
예를 들어, Fig. 1은 40GB RAM을 가지는 NVIDIA A100 GPU에서 130억 (13B) parameter
LLM의 memory 분포를 보여준다.
약 65%의 memory가 serving 중 고정적이게 model 가중치로 할당되고, 약 30%의 memory가 요청에 대한 동적인 상태 (dynamic states)를 저장하기 위해 사용될 것이다.
Transformers에서 이러한 상태는 KV cache $_[$$_{41}$$_]$라고 불리는 attention mechanism과 관련된 key와 value tensors로 구성되며, 이는 이전 tokens의 context를 나타내어 순서대로 새 출력 token을 생성한다.
그리고 남아있는 나머지 memory는 LLM을 평가할 때 생성되는 일시적인 tensor인 activation을 포함한 다른 data에서 사용된다.
Model의 가중치는 고정되어있고, activations는 GPU memory의 작은 부분만 차지하므로 KV cache가 관리되는 방식은 최대 batch size를 결정하는데 중요하며 비효율적으로 관리될 경우 KV cache memory는 batch size를 크게 제한하고, 결과적으로 LLM의 throughput을 제한할 수 있다.
해당 논문에선 기존의 LLM serving systems $_[$$_{31}$$_,$$_{60}$$_]$에서 KV cache memory를 효율적으로 관리하지 못함을 관측한다.
이는 주로 대부분의 deep learning frameworks $_[$$_{33}$$_,$$_{39}$$_]$가 tensor를 contiguous memory에 저장해야하고 요청의 KV cache를 contiguous memory space에 저장하기 때문이다.
그러나 기존 deep learning workloads의 tensors와 다르게 KV cache는 model이 새로운 token을 생성함에 따라 그리고 시간이 지남에 따라 동적으로 증가하거나 감소하며, lifetime과 길이는 알 수 없는 고유한 특성을 가지고 있고 이러한 특성으로 기존 systems의 접근 방식은 두 가지 측면에서 상당히 비효율적이다.
- 기존의 systems $_[$$_{31}$$_,$$_{60}$$_]$는 internal/external memory fragmentation으로 어려움을 겪음
- 요청의 최대 길이 (e.g., 2048 tokens)를 가지는 연속된 chunk of memory를 미리 할당
- 요청의 실제 길이가 최대 길이보다 훨씬 작을 수 있기 때문에 심각한 internal fragmentation 발생 가능
- 사전에 실제 길이를 알더라도 전체 chunk가 요청의 lifetime 동안 할당되기 때문에 더 짧은 다른 요청은 현재 사용되지 않는 chunk의 어떤 부분도 활용할 수 없기 때문에 여전히 비효율적
- 각 요청마다 미리 할당된 크기가 다를 수 있기 때문에 external memory fragmentation이 심각할 수 있음
- 기존의 systems에서는 memory 공유의 기회를 활용할 수 없음
- LLM service는 parallel sampling과 beam search와 같은 고급 decoding algorithm을 사용하여 요청당 여러 출력을 생성하는 경우가 많고 요청은 KV cache를 부분적으로 공유할 수 있는 여러 sequence로 구성됨
- 하지만 sequence의 KV cache가 서로 separate contiguous spaces에 저장되기 때문에 기존 systems에서 memory 공유 불가능
위 한계점들을 해결하기위해 저자들은 memory fragmentation 및 sharing에 대한 Operating System (OS)의 solution인 paging을 사용한 virtual memory에서 영감을 받은 PagedAttention을 제안한다.
PagedAttention은 요청의 KV cache를 고정된 개수의 token에 대한 attention keys와 values를 포함할 수 있는 block 단위로 나눈다.
PagedAttention에서 KV cache block은 반드시 연속된 공간에 저장되지는 않을 수 있다.
따라서 OS의 virtual memory와 같이 KV cache를 더욱 유연하게 관리할 수 있다. (blocks ~= pages, tokens ~= bytes, requests ~= processes)
이 설계는 비교적 작은 block을 사용하고 필요에 따라 할당함으로써 internal fragmentation을 완화하며 모든 block의 크기가 동일하기 때문에 external fragmentation도 해결한다.
추가적으로 block 단위로 memory 공유가 가능하여 동일한 요청과 관련된 여러 sequence 또는 여러 요청 간에도 memory 공유가 가능하다.
본 연구에서는 PagedAttention 기반의 high-throughput distributed LLM serving engine인 vLLM을 구축하여 KV cache memory 낭비를 거의 없앤다.
vLLM은 PagedAttention과 함께 설계된 block 수준 memory 관리 및 preemptive request scheduling을 사용하며, 단일 GPU memory 용량을 초과하는 LLM을 포함하여 다양한 크기의 GPT $_[$$_{5}$$_]$, OPT $_[$$_{62}$$_]$, LLaMA $_[$$_{52}$$_]$와 같은 널리 사용되는 LLM을 지원한다.
다양한 model과 workload에 대한 평가 결과, vLLM은 model 정확도에 전혀 영향을 미치지 않으면서 state-of-art systems $_[$$_{31}$$_,$$_{60}$$_]$ 대비 LLM serving throughput을 2~4배 향상시킨다.
이러한 개선은 sequence가 길수록, model이 클수록, decoding algorithm이 복잡할수록 더욱 확연하게 차이를 보인다.
- LLM serving 시 memory 할당의 문제점을 파악하고, 이것이 serving 성능에 미치는 영향 정량화
- OS의 virtual memory와 paging에서 영감을 받은 non-contiguous paged memory에 저장된 KV cache에서 작동하는 attention algorithm인 PagedAttention 제안
- PagedAttention을 기반으로 구축된 distributed LLM serving engine인 vLLM을 설계 및 구현
- 다양한 scenarios에서 vLLM을 평가하고 FasterTransformer $_[$$_{31}$$_]$ 및 Orca $_[$$_{60}$$_]$와 같은 기존 최첨단 solution 보다 성능이 훨씬 우수함
Background
해당 절에서는 일반적인 LLM의 생성 및 serving 절차와 LLM serving에 사용되는 iteration 수준 scheduling을 설명한다.
Transformer-Based Large Language Models
Language modeling의 과제는 list of tokens ($x_1,…,x_n$)의 확률을 modeling하는 것이다.
언어는 자연스러운 순차적 순서가 있으므로 전체 sequence에 대한 결합 확률을 조건부 확률의 곱으로 인수분해하는 것이 일반적이다 (a.k.a. autoregressive decomposition $_[$$_{3}$$_]$):
$$
P(x)=P(x_1)\cdot P(x_2|x_1) \dotsb P(x_n|x_1,…,x_{n-1})
$$
Transformers $_[$$_{53}$$_]$는 확률을 대규모로 modeling하는 표준 architecture가 되었다.
Transformer 기반 language model의 가장 중요한 구성 요소는 self-attention layer다.
Input hidden state sequence $(x_1,…,x_n)\in\mathbb{R}^{n\times d}$에 대해 self-attention layer는 먼저 각 위치 $i$에 대해 선형 변환을 적용하여 query, key, value vector를 얻는다:
$$
q_i=W_qx_i,\ k_i=W_kx_i,\ v_i=W_vx_i
$$
그리고 self-attention layer는 한 위치의 query vector에 그 앞의 모든 key vector를 곱하여 attention score $a_{ij}$를 계산하고 value vector에 대한 가중 평균으로 출력 $o_i$를 계산한다:
$$
a_{ij}=\frac{\exp(q^\top k_j/\sqrt{d})}{\Sigma^i_{t=1}\exp(q_i^\top k_t/\sqrt{d})},\ o_i=\sum_{j=1}^{i}a_{ij}v_j
$$
위 수식 외에, embedding layer, feed-forward layer, layer normalization $_[$$_{2}$$_]$, residual connection $_[$$_{22}$$_]$, output logit computation 및 Eq. 2의 query, key, value 변환을 포함한 Transformer model의 다른 모든 구성 요소는 모두 $y_i=f(x_i)$의 형태로 표현이 가능하며, 위치별로 독립적이게 적용된다.
LLM Service & Autoregressive Generation
LLM은 학습 후 conditional generation service (e.g., completion API $_[$$_{34}$$_]$, chatbot $_[$$_{19}$$_,$$_{35}$$_]$)로 배포되는 경우가 많다.
LLM service에 대한 요청은 input prompt tokens ($x_1,…,x_n$)을 제공하고, LLM service는 Eq. 1에 따라 list of output tokens ($x_{n+1},…,x_{n+T}$)를 생성한다.
Prompt list와 output list를 연결한 것을 sequence라고 한다.
Eq. 1의 decomposition으로 인해 LLM은 새로운 token을 하나씩만 sampling하고 생성할 수 있으며, 각 새 token의 generation process는 해당 sequence의 모든 precvious tokens, 특히 key vector와 value vector에 따라 달라진다.
이러한 순차적 generation process에서 기존 token의 key vector와 value vector는 향후 token 생성을 위해 cache되는 경우가 많으며, 이를 KV cache라고 한다.
한 token의 KV cache는 이전 token의 KV cache에 따라 달라진다.
즉, sequence의 다른 위치에 나타나는 동일한 token의 KV cache는 서로 다르다.
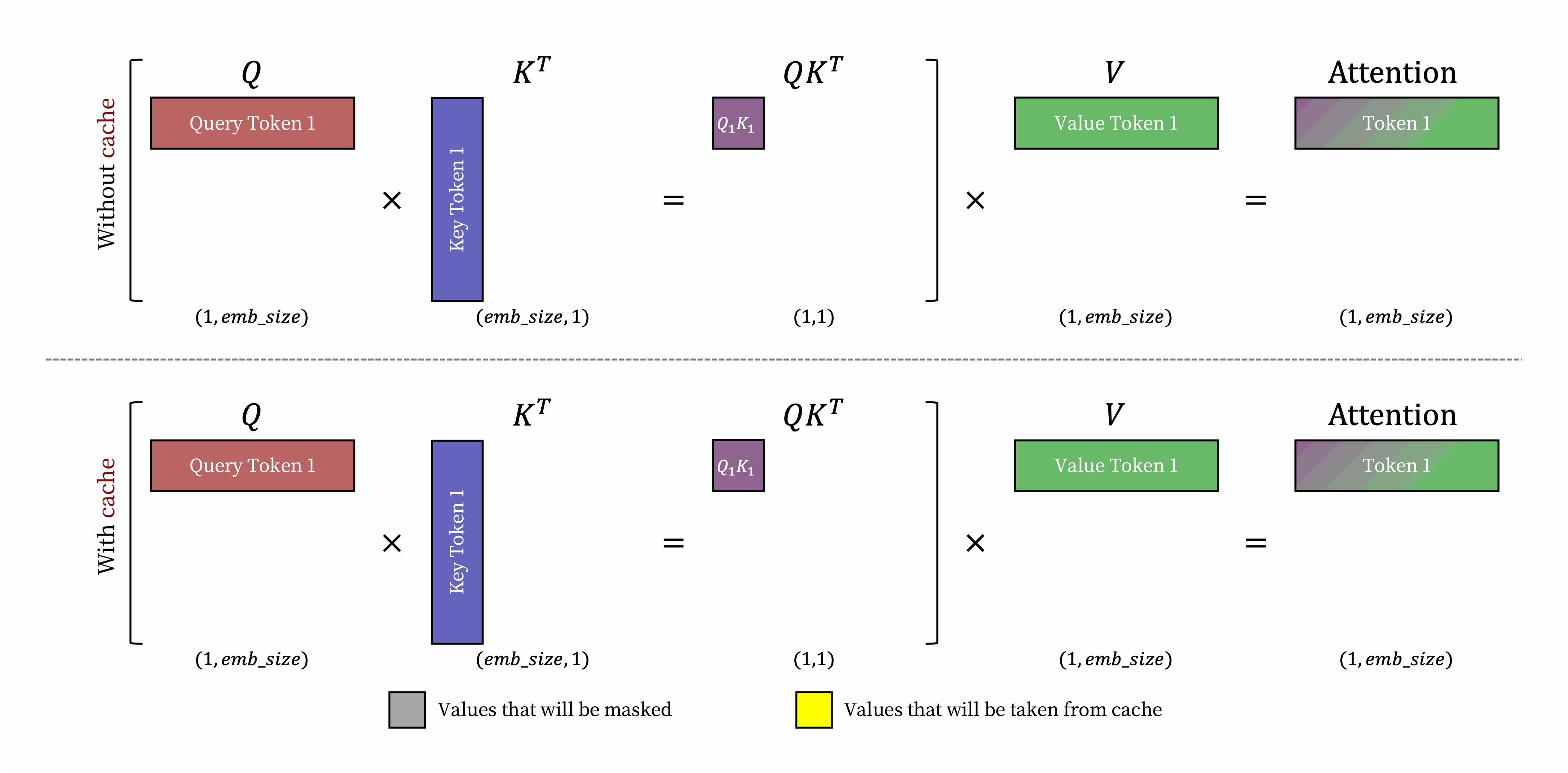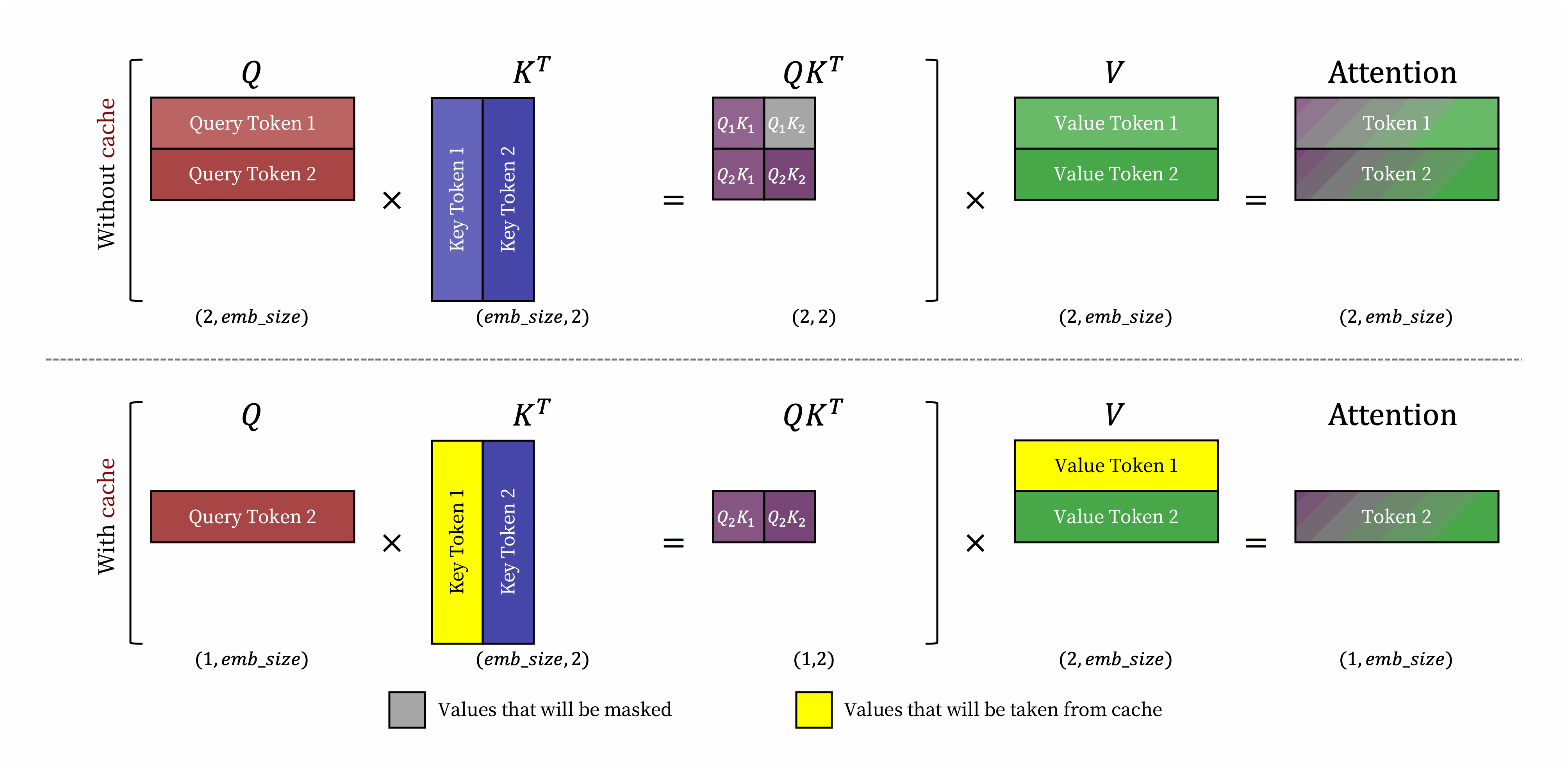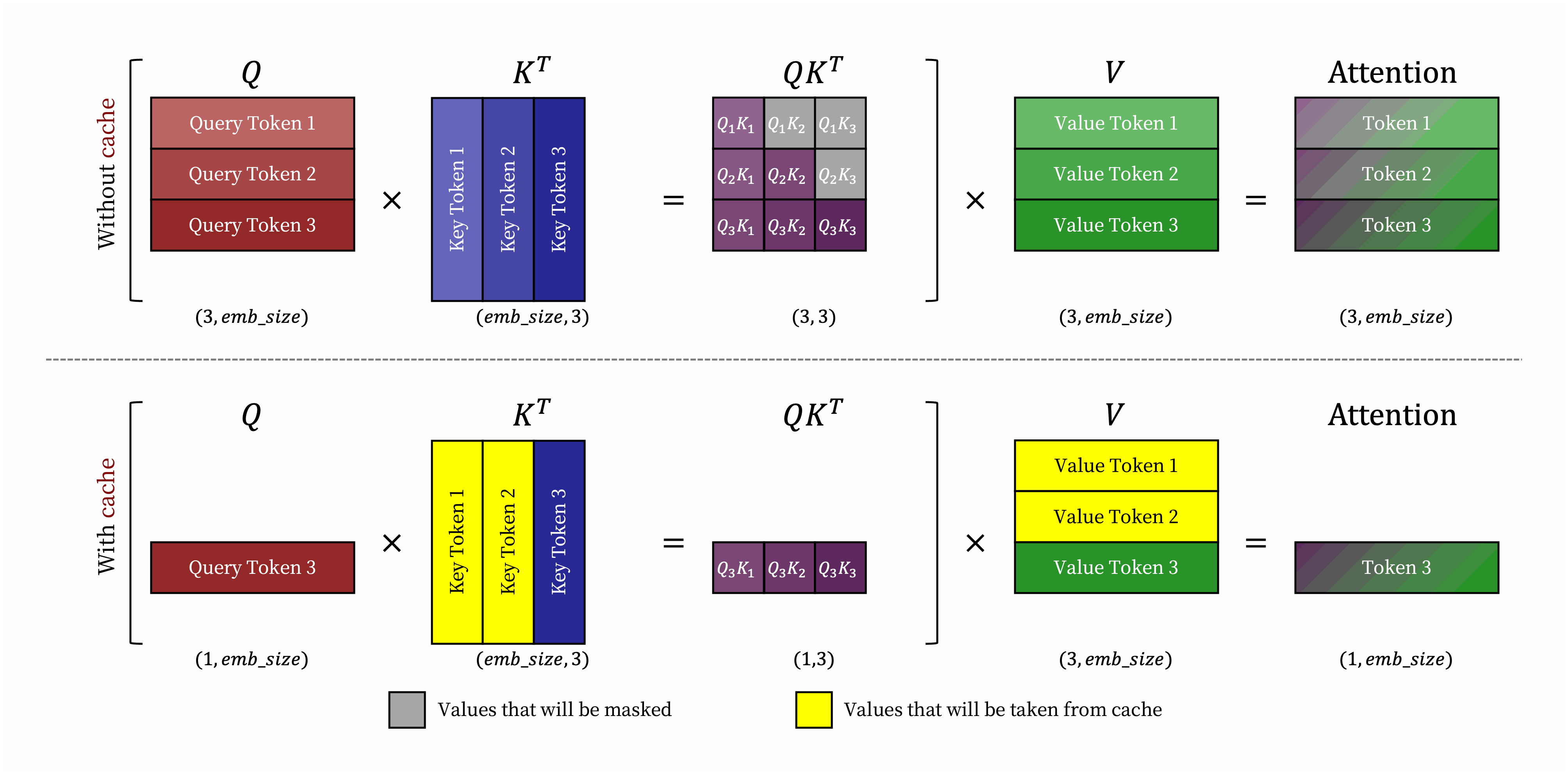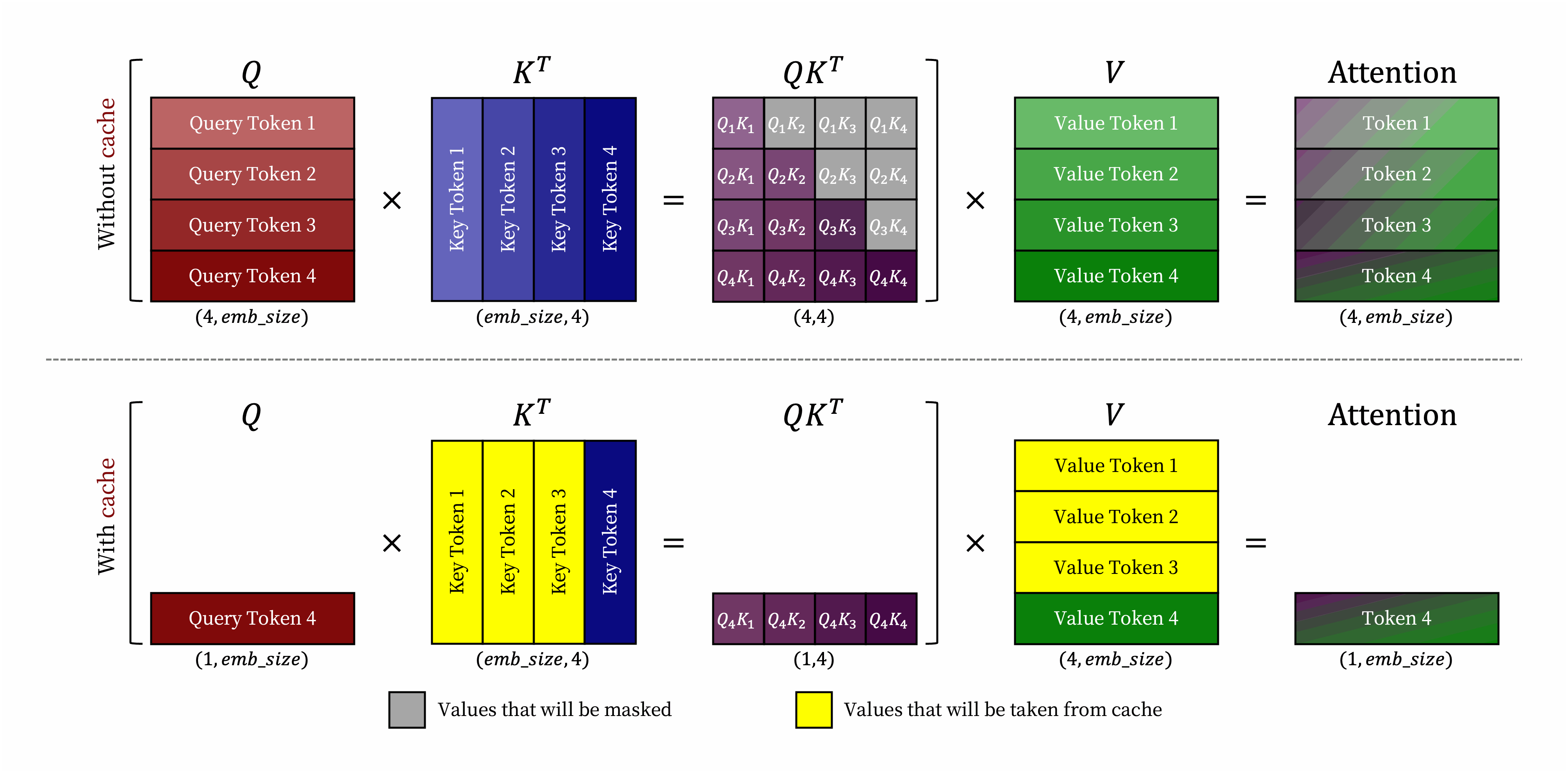
Request prompt가 주어지면, LLM service의 generation computation은 두 단계로 나눌 수 있다.
The prompt phase
사용자 prompt 전체 ($x_1,…,x_n$)를 입력으로 받아 첫 번째 새 token의 확률을 계산한다 ($P(x_{n+1}|x_1,…,x_n)$).
이 과정에서 key vector $k_1,…,k_n$와 value vector $v_1,…,v_n$도 생성한다.
Prompt token $x_1,…,x_n$은 모두 알려져 있으므로, prompt phase의 계산은 matrix-matrix multiplication 연산을 사용하여 병렬화될 수 있다.
따라서 이 단계는 GPU에 내재된 병렬성을 효율적으로 활용할 수 있다.
The autoregressive generation phase
Autoregressive generation phase에선 나머지 새 token을 순차적으로 생성한다.
Iteration $t$에서 model은 하나의 token $x_{n+t}$를 입력으로 받고 key vector $k_1,…,k_{n+t}$와 value vector $v_1,…,v_{n+t}$를 사용하여 확률 $P(x_{n+t+1}|x_1,…,x_{n+t})$를 계산한다.
위치 $1$에서 $n+t-1$까지의 key vector와 value vector는 previous iteration에서 cache되며, 이번 iteration에서는 새로운 key vector $k_{n+t}$와 value vector $v_{n+t}$만 계산된다.
이 단계는 sequence가 최대 길이 (사용자가 지정하거나 LLM에 의해 제한됨)에 도달하거나 end-of-sequence (<eos>) token이 생성될 때 완료된다.
여러 iteration에서의 계산은 data dependency로 인해 병렬화될 수 없으며, 종종 matrix-vector multiplication을 사용하는데, 이는 효율성이 떨어진다.
결과적으로 이 단계는 GPU 계산을 심각하게 저활용하고 memory에 의존하게 되며, 단일 요청 지연 시간의 대부분을 차지한다.
Batching Techniques for LLMs
LLM serving 시 computing 활용도는 여러 요청을 일괄 처리함으로써 개선할 수 있다.
요청들이 동일한 model weight를 공유하기 때문에 가중치 이동 overhead가 batch 내 request 전체에 분산되며, batch size가 충분히 클 경우 computational overhead가 이를 압도할 수 있다.
그러나 LLM service에 대한 요청을 batch 처리하는 것은 두 가지 이유로 간단하지 않다.
첫째, 요청이 서로 다른 시간에 도착할 수 있다.
Naive batching 전략은 이전 요청이 이후 요청을 기다리게 하거나, 이전 요청이 완료될 때까지 수신 요청을 지연시켜 상당한 queueing delay를 초래할 수 있다.
둘째, 요청의 입력 및 출력 길이가 매우 다를 수 있다.
단순한 batching 전략은 요청의 입력과 출력을 padding하여 길이를 같게 만들어 GPU 계산과 memory를 낭비하게 된다.
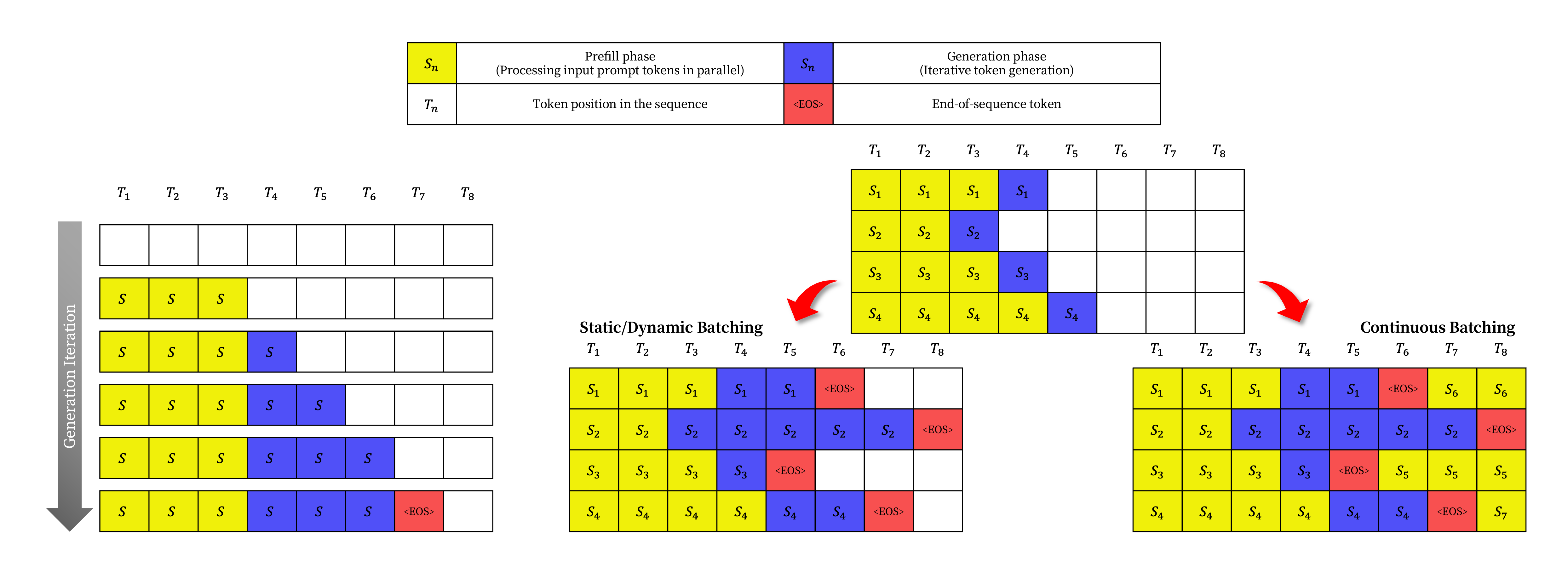
이 문제를 해결하기 위해 cellular batching $_[$$_{16}$$_]$ 및 iteration-level scheduling $_[$$_{60}$$_]$과 같은 세분화된 batching mechanism이 제안되었다.
요청 수준에서 작동하는 기존 방식과 달리 이러한 기술들은 iteration 수준에서 작동한다.
각 iteration 후, 완료된 요청은 batch에서 제거되고 새로운 요청이 추가된다.
따라서 전체 batch가 완료될 때까지 기다릴 필요 없이 단일 iteration을 기다린 후 새 요청을 처리할 수 있다.
또한, 특수 GPU kernel을 사용하면 이러한 기술은 입력과 출력에 대해 padding할 필요성을 제거한다.
Padding으로 인한 queueing delay와 비효율성을 줄임으로써 세분화된 batching mechanism은 LLM serving의 throughput을 크게 증가시킨다.
Memory Challenges in LLM Serving
세분화된 batching은 computing 낭비를 줄이고 요청을 더욱 유연하게 batching할 수 있도록 하지만, batching이 가능한 요청 수는 여전히 GPU memory 용량, 특히 KV cache 저장에 할당된 공간에 의해 제한된다.
즉, serving system의 throughput은 memory에 따라 결정된다.
이러한 memory 제한을 극복하려면 memory 관리에서 아래와 같은 과제들을 해결해야한다.
Large KV cache
KV cache 크기는 요청 수에 따라 빠르게 증가한다.
예를 들어, 13B parameter를 가지는 OPT model $_[$$_{62}$$_]$의 경우, 단일 token의 KV cache는 800KB의 공간을 필요로 하며, 이는 $2$ (key vectors, value vectors) $\times$ $40$ (number of layers) $\times$ $2$ (bytes per FP16)로 계산된다.
OPT는 최대 2048개의 token sequence를 생성할 수 있으므로, 한 요청의 KV cache를 저장하는 데 필요한 memory는 최대 1.6GB가 될 수 있다.
Concurrent GPU의 memory 용량은 수십 GB에 달한다.
사용 가능한 모든 memory를 KV cache에 할당하더라도 수십 개의 요청만 수용할 수 있으며 비효율적인 memory 관리로 인해 batch 크기가 더욱 감소할 수 있다 $_[$$_{17}$$_]$.
예를 들어, NVIDIA A100에서 H100으로 upgrade하면 FLOPS는 2배 이상 증가하지만, GPU memory는 최대 80GB로 유지된다.
따라서 memory 병목 현상이 점점 더 심각해질 것으로 예상된다.
Complex decoding algorithms
LLM service는 사용자가 선택할 수 있는 다양한 decoding algorithm을 제공하며, 각 algorithm은 memory 관리 복잡성에 미치는 영향이 다르다.
예를 들어, program suggestion $_[$$_{18}$$_]$의 일반적인 사용 사례인 단일 input prompt에서 여러 개의 무작위 sample을 요청할 때, 전체 KV cache memory의 12%를 차지하는 prompt 부분의 KV cache를 공유하여 memory 사용량을 최소화 할 수 있다.
반면, autoregressive generation phase에서는 sample 결과가 다르고 context 및 위치에 따라 달라지기 때문에 KV cache를 공유하지 않아야 한다.
KV cache 공유 범위는 사용되는 특정 decoding algotihm에 따라 달라진다.
Beam search $_[$$_{49}$$_]$와 같은 보다 정교한 algorithm에서는 서로 다른 request beam이 KV cache의 더 큰 부분 (최대 55% memory 절약)을 공유할 수 있으며, sharing pattern은 decoding process가 진행됨에 따라 변화한다.
Scheduling for unknown input & output lengths
LLM service에 대한 요청은 입력 및 출력 길이가 가변적이다.
따라서 memory management system은 다양한 prompt 길이를 수용해야 한다.
또한, decoding 시 요청의 출력 길이가 증가함에 따라 KV cache에 필요한 memory도 확장되어 새로운 요청이나 기존 prompt에 대한 진행되고 있는 생성에 의해 지속적인 생성에 필요한 memory가 고갈될 수 있다.
System은 GPU memory에서 일부 요청의 KV cache를 삭제하거나 교체하는 등의 scheduling 결정을 내려야한다.
Memory Management in Existing Systems
현재 deep learning framework $_[$$_{33}$$_,$$_{39}$$_]$의 대부분 연산자는 tensor가 contiguous memory에 저장되어야 하므로, 기존 LLM serving system $_[$$_{31}$$_,$$_{60}$$_]$ 역시 한 요청의 KV cache를 서로 다른 위치에 걸쳐 contiguous tensor로 저장한다.
LLM의 예측 불가능한 출력 길이로 인해, 요청의 실제 입력 길이 또는 최종 출력 길이와 관계없이 요청의 최대 가능 sequence 길이를 기준으로 요청에 대한 memory chunk를 정적으로 할당한다.

Figure 3. KV cache memory management in existing systems. Three types of memory wastes – reserved, internal fragmentation, and external fragmentation – exist that prevent other requests from fitting into the memory. The token in each memory slot represents its KV cache. Note the same tokens can have different KV cache when at different positions.
Fig. 3은 2가지 요청을 나타낸다.
- Request A: 최대 2048개의 sequence 길이
- Request B: 최대 512개의 sequence 길이
기존의 KV cache memory management 방식을 나타내며, 각 memory slot의 token은 해당 KV cache를 나타내며 동일한 token이라도 위치에 따라 다른 KV cache를 가질 수 있다.
기존 system의 chunk pre-allocation 방식은 3가지 주요 memory 낭비 원인을 가지고 있다.
- 미래 token을 위한 reserved slots
- 잠재적인 최대 sequence 길이에 대한 과도한 provisioning으로 인한 internal fragmentation
- Buddy allocator와 같은 memory 할당자의 external fragmentation
External fragmentation은 생성된 token에 사용되지 않으며, 이는 요청을 처리하기 전에 알 수 있다.
Internal fragmentation도 사용되지 않지만, 이는 요청 sampling이 완료된 후에야 나타난다.
예약된 memory는 결국 사용되지만, 특히 예약된 공간이 큰 경우 요청이 진행되는 동안 이 공간을 예약하면 다른 요청을 처리하는 데 사용할 수 있는 공간을 차지하게 되어 두 가지 모두 순수한 memory 낭비다.
Fragmentation에 대한 잠재적 해결책으로 compaction $_[$$_{54}$$_]$이 제안되었지만, 성능에 민감한 LLM serving system에서는 KV cache가 너무 크기 때문에 compaction을 수행하는 것이 비현실적이다.
Compaction을 사용하더라도 각 요청에 대해 미리 할당된 chunk space 때문에 기존 memory management system의 decoding algorithm에 특화된 memory 공유가 불가능하다.
Method
본 연구에서는 새로운 attention algorithm인 PagedAttention을 개발하고, LLM serving engine인 vLLM을 구축하여 $\S3$의 문제들을 해결한다.
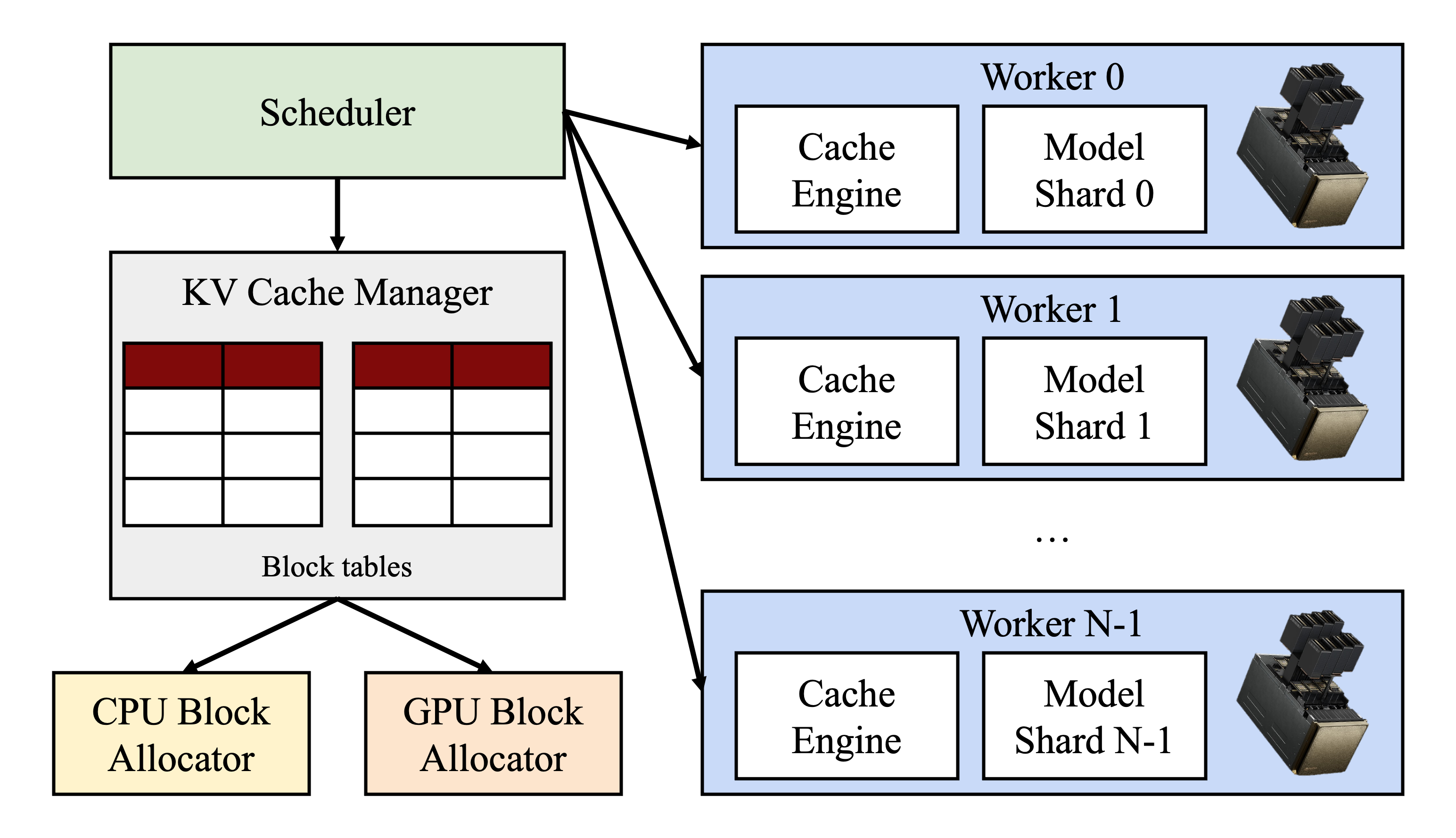
Figure 4. vLLM system overview.
Fig. 4는 vLLM의 architecture이다.
vLLM은 분산된 GPU worker의 실행을 조정하기 위해 centralized scheduler를 채택했다.
KV cache manager는 PagedAttention을 통해 활성화된 paged 방식으로 KV cache를 효과적으로 관리한다.
구체적으로, KV cache manager는 centralized scheduler에서 전송된 명령을 통해 GPU worker의 physical KV cache memory를 관리한다.
PagedAttention
$\S3$의 memory 문제들을 해결하기 위해 운영 체제의 고전적인 paging $_[$$_{25}$$_]$ idea에서 영감을 받은 attention algorithm인 PagedAttention은 기존의 attention algorithm과 달리 non-contiguous memory space에 연속적인 key와 value를 저장할 수 있다.
구체적으로 PagedAttention은 각 sequence의 KV cache를 KV block으로 분할한다.
각 block들은 고정된 수의 token에 대한 key 및 value vector를 포함하며, 이를 KV block size ($B$)라고 한다.
Key block은 $K_j=(k_{(j-1)B+1},…,k_{jB})$, value block은 $V_j=(v_{(j-1)B+1},…,v_jB)$로 표시한다.
Eq. 4의 attention 계산은 다음과 같은 block-wise computation으로 변환될 수 있다.
$$
A_{ij}=\frac{\exp(q_i^\top K_j/\sqrt{d})}{\Sigma_{t=1}^{\lceil i/B\rceil}\exp(q_i^\top K_t/\sqrt{d})},\ o_i=\sum_{j=1}^{\lceil i/B\rceil}V_jA_{ij}^\top
$$
여기서 $A_{ij}=(a_{i,(j-1)B+1},…,a_{i,jB})$는 $j$번째 KV block의 row vector of attention score이다.
Attention 계산 중 PagedAttention kernel은 서로 다른 KV block을 개별적으로 식별하고 가져온다.
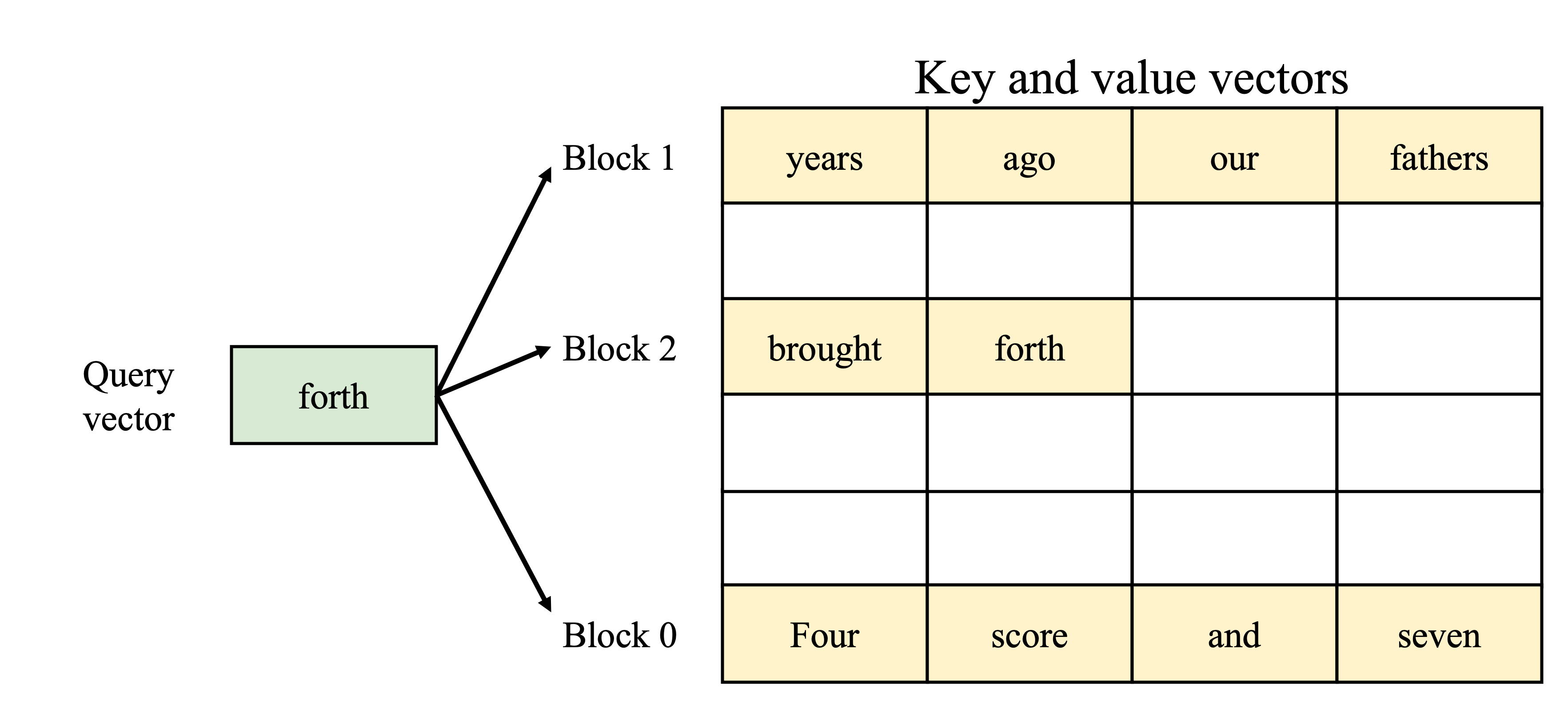
Figure 5. Illustration of the PagedAttention algorithm, where the attention key and values vectors are stored as non-contiguous blocks in the memory.
Fig. 5는 PagedAttention의 예시를 보여준다.
Key vector와 value vector는 세 block에 분산되어 있고, physical memory에서 contiguous하지 않다.
각 시점에서 kernel은 query token (“forth”)의 query vector $q_i$와 block의 key vector $K_j$ (e.g., block 0의 “Four score and seven”의 key vector)를 곱하여 attention score $A_{ij}$를 계산하고, 나중에 $A_{ij}$와 block의 value vector $V_j$를 곱하여 최종 attention output $o_i$를 도출한다.
요약하자면, PagedAttention algorithm을 사용하면 KV block을 non-contiguous한 physical memory에 저장할 수 있으므로 vLLM에서 더욱 유연한 paged memory management가 가능하다.
KV Cache Manager
vLLM memory manager의 key idea는 운영 체제의 virtual memory $_[$$_{25}$$_]$와 유사하다.
OS는 memory를 fixed-sized pages로 분할하고 사용자 program의 logical page에 mapping한다.
Contiguous logical page는 non-contiguous physical memory page에 대응할 수 있으므로 사용자 program은 마치 연속된 것처럼 memory에 access 할 수 있다.
또한, physical memory space를 미리 완전히 예약할 필요가 없기 때문에 OS는 필요에 따라 physical page를 동적으로 할당할 수 있다.
vLLM은 virtual memory의 기본 개념을 활용하여 LLM service의 KV cache를 관리한다.
PagedAttention을 통해 KV cache를 virtual memory의 page와 같이 fixed-size KV block으로 구성한다
요청의 KV cache는 일련의 logical KV block으로 표현되며, 새로운 token과 해당 token의 KV cache가 생성됨에 따라 왼쪽에서 오른쪽으로 채워진다.
GPU worker에서 block engine은 GPU DRAM의 contiguous chunk를 할당하고 이를 physical KV block으로 나눈다 (이는 CPU RAM에서도 swapping을 위해 수행된다. $\S4.5$).
KV block manager는 각 요청의 logical KV block과 physical KV block 간의 mapping인 block table도 관리한다.
각 block table 항목은 logical block에 해당하는 physical block과 채워진 위치의 개수를 기록한다.
Logical KV block과 physical KV block을 분리하면 vLLM이 모든 위치에 미리 예약하지 않고도 KV cache memory를 동적으로 확장할 수 있으므로 기존 system의 대부분 memory 낭비를 제거할 수 있다.
Decoding with PagedAttention and vLLM
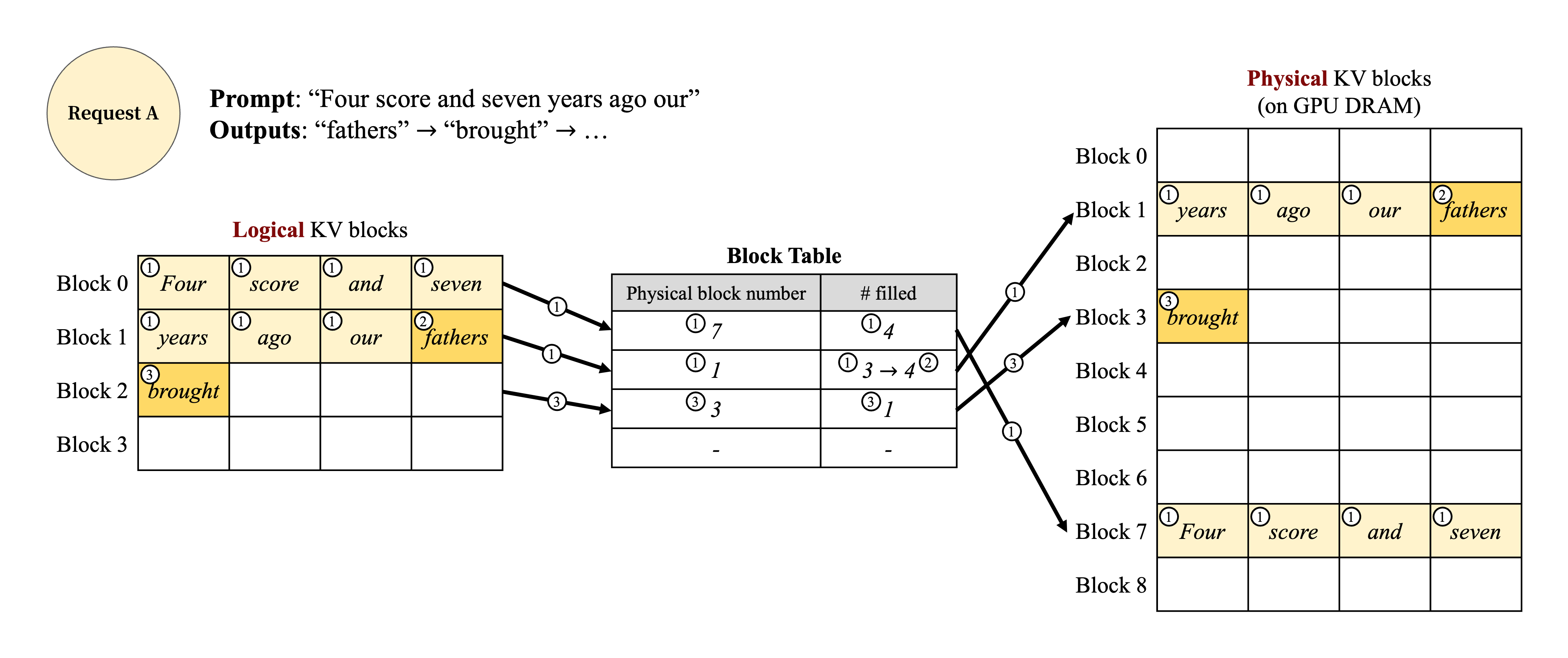
Figure 6. Block table translation in vLLM.
다음으로, Fig. 6과 같은 예시를 통해 vLLM이 단일 input sequence의 decoding 과정에서 PagedAttention을 실행하고 memory를 관리하는 방식을 알아보겠다.
① OS의 virtual memory와 마찬가지로 vLLM은 생성된 sequence의 최대 길이에 대한 memory를 처음에 예약할 필요가 없다.
대신, prompt 계산 중 생성된 KV cache를 수용하기 위해 필요한 KV block만 예약한다.
이러한 경우, prompt에는 7개의 token이 있으므로 vLLM은 처음 2개의 logical KV blocks (0과 1)을 2개의 physical KV block (각각 7과 1)에 mapping한다.
Prefill step에서 vLLM은 기존의 self attention algorithm (e.g., $[$${13}$$]$)을 사용하여 prompt의 KV cache와 첫 번째 output token을 생성한다.
그런 다음 vLLM은 처음 4개 token의 KV cache를 logical block 0에 저장하고, 그 다음 3개 token을 logical block 1에 저장한다.
남은 slot은 후속 autoregressive generation phase를 위해 예약된다.
② 첫 번째 autoregressive decoding step에서 vLLM은 physical block 7과 1에 PagedAttention algorithm을 사용하여 새로운 token을 생성한다.
마지막 logical block에 사용 가능한 slot이 하나 남아 있으므로 새로 생성된 KV cache가 해당 위치에 저장되고 block table의 #filled record가 update된다.
③ 두 번째 decoding step에서 마지막 logical block이 가득 차면 vLLM은 새로 생성된 KV cache를 새 logical block에 저장합니다.
vLLM은 해당 block에 새 physical block (physical block 3)을 할당하고 이 mapping을 block table에 저장한다.
전역적으로, 각 decoding iteration마다 vLLM은 먼저 batching할 후보 sequence 집합을 선택하고 ($\S4.5$), 새로 필요한 logical block에 physical block을 할당한다.
그 이후, vLLM은 현재 iteration의 모든 input token (i.e., prompt phase 요청에 대한 모든 token과 생성 단계 요청에 대한 최신 token)을 하나의 sequence로 연결하여 LLM에 제공한다.
LLM의 계산 과정에서 vLLM은 PagedAttention kernel을 사용하여 logical KV block로 저장된 이전 KV cache에 접근하고 새로 생성된 KV cache를 physical KV block에 저장한다.
KV block (block size > 1) 내에 여러 token을 저장하면 PagedAttention kernel이 더 많은 위치에서 KV cache를 병렬로 처리할 수 있어 hardware 사용률이 증가하고 latency가 단축된다.
그러나 block 크기가 커지면 memory fragmentation도 증가한다. ($\S7.2$)
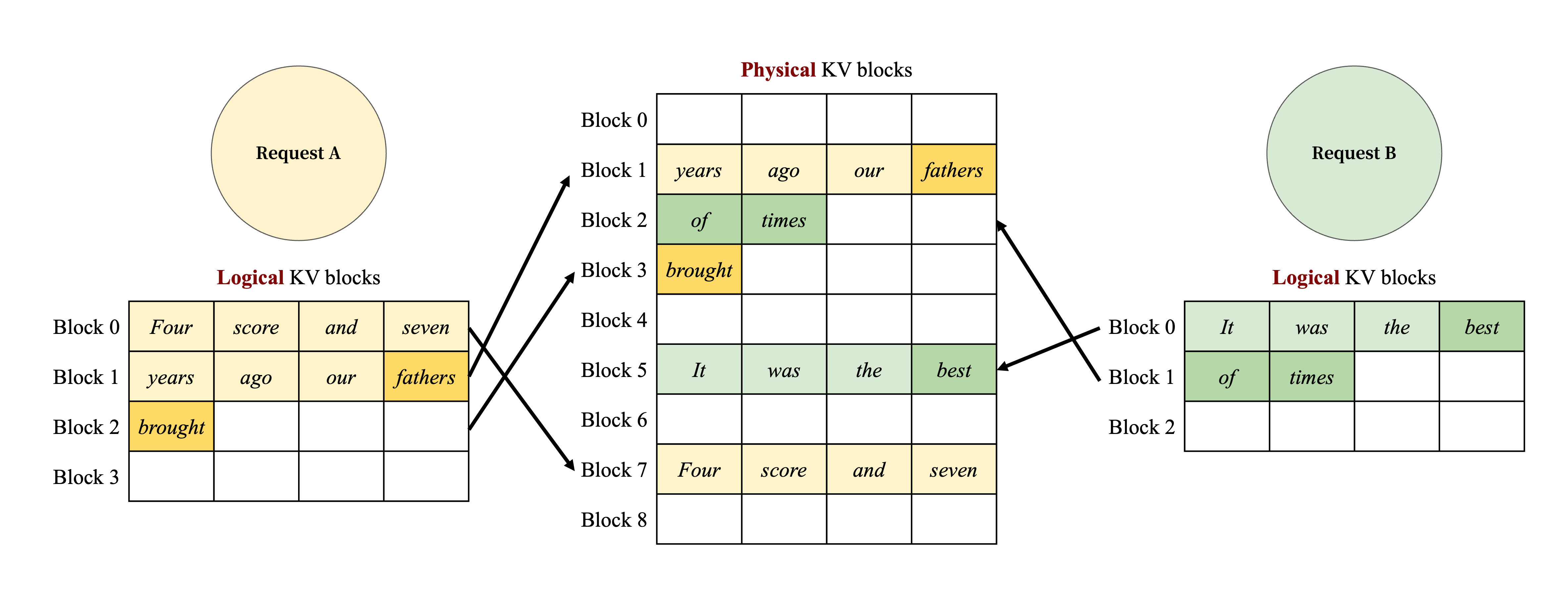
Figure 7. Storing the KV cache of two requests at the same time in vLLM.
vLLM은 token과 KV cache가 더 많이 생성됨에 따라 새로운 physical block을 logical block에 동적으로 할당한다.
모든 block은 왼쪽에서 오른쪽으로 채워지고 이전 block이 모두 가득 찰 때만 새로운 physical block이 할당되므로, vLLM은 한 block 내에서 요청에 대한 모든 memory 낭비를 제한하여 모든 memory를 효과적으로 활용할 수 있다.
이로 인해 batching을 위한 더 많은 요청을 memory에 저장할 수 있으므로 throughput이 향상된다.
요청 생성이 완료되면 해당 KV block을 해제하여 다른 요청의 KV cache를 저장할 수 있다.
Fig. 7은 vLLM이 두 sequence를 관리하는 예시를 보여준다.
두 sequence의 logical block은 GPU worker의 block engine이 예약한 공간 내에서 서로 다른 physical block에 mapping된다.
두 sequence의 인접한 logical block은 physical GPU memory에서 연속적일 필요가 없으며, physical block의 공간은 두 sequence 모두에서 효과적으로 활용할 수 있다.
Application to Other Decoding Scenarios
$\S4.3$은 PagedAttention과 vLLM이 하나의 사용자 prompt를 입력으로 받아 단일 output sequence를 생성하는 greedy decoding 및 sampling과 같은 기본적인 decoding algorithm을 처리하는 방법을 보여준다.
많은 성공적인 LLM application $_[$$_{18}$$_,$$_{34}$$_]$에서 LLM service는 복잡한 접근 pattern과 더 많은 memory 공유 기회를 보이는 더욱 복잡한 decoding scenario를 제공해야 한다.
이 section에서는 이러한 scenario에 대한 vLLM의 일반적인 적용 가능성을 보여준다.
Parallel sampling
LLM 기반 program assistant $_[$$_{6}$$_,$$_{18}$$_]$에서 LLM은 단일 input prompt에 대해 여러 개의 sampling된 출력을 생성한다.
지금까지는 요청이 단일 sequence를 생성한다고 암묵적으로 가정했다.
본 연구의 나머지 부분에서는 요청이 여러 sequence를 생성하는 보다 일반적인 경우를 가정한다.
Prallel samling에서 하나의 요청은 동일한 input prompt를 공유하는 여러 sample을 포함하므로 prompt의 KV cache도 공유할 수 있다.
vLLM은 PagedAttention 및 page memory management를 통해 이러한 공유를 쉽게 구현하고 memory를 절약할 수 있다.
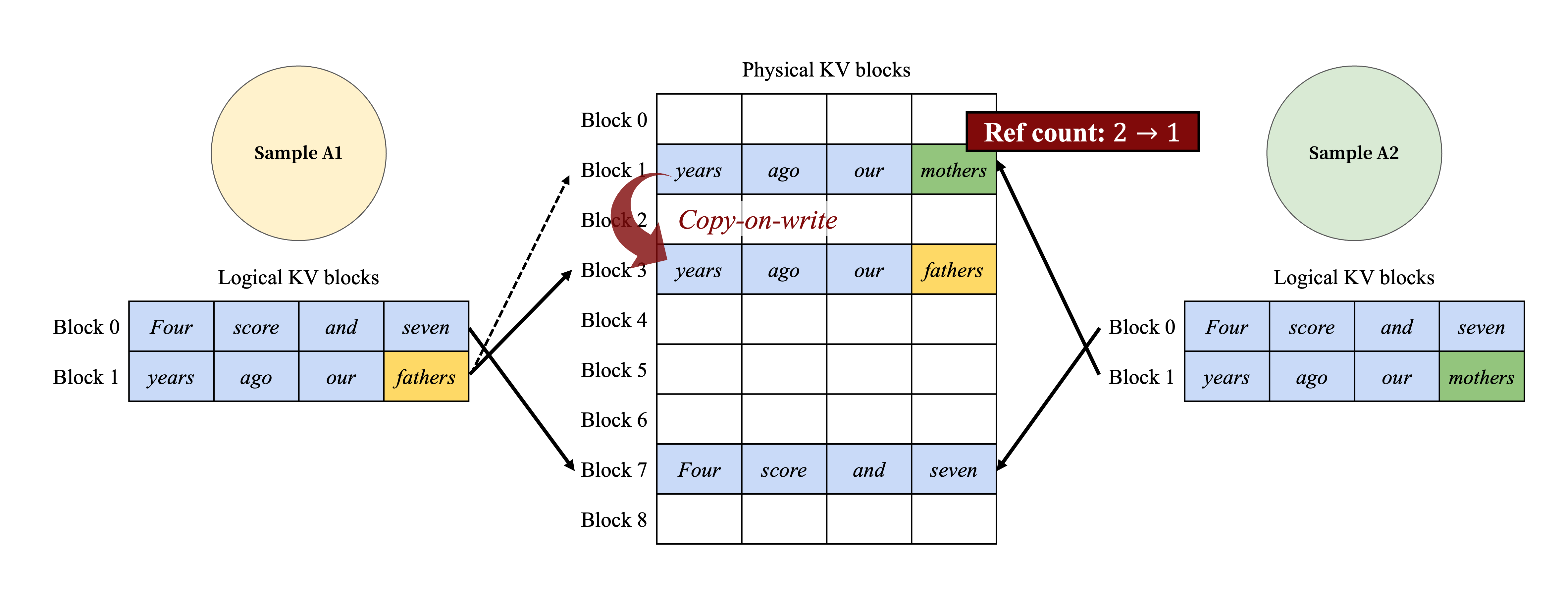
Figure 8. Parallel sampling example.
Fig. 8은 두 출력에 대한 parallel decoding의 예를 보여준다.
두 출력 모두 동일한 prompt를 공유하므로, prompt phase에서는 prompt 상태의 복사본 하나만을 위해 space를 예약한다.
두 sequence의 prompt에 대한 logical block은 동일한 physical block에 mapping된다.
두 sequence의 logical block 0과 1은 각각 physical block 7과 1에 mapping된다.
하나의 physical block이 여러 logical block에 mapping될 수 있으므로, 각 physical block에 대한 reference count를 도입한다.
이 경우, physical block 7과 1의 reference count는 모두 2이다.
Generation phase에서 두 출력은 서로 다른 output token을 sampling하며, KV cache를 위한 별도의 저장소가 필요하다.
vLLM은 여러 sequence에 의해 수정되어야 하는 physical block에 대해 block 단위에서 copy-on-write mechanism을 구현한다.
이는 OS virtual memory의 copy-on-write technique와 유사하다 (e.g., when forking a process).
구체적으로, Fig. 8에서 sample A1이 마지막 physical block (logical block 1)에 써야 할 때, vLLM은 해당 physical block (physical block 1)의 reference count가 1보다 크다는 것을 인식한다.
vLLM은 새로운 physical block (physical block 3)을 할당하고, block engine에 physical block 1의 정보를 복사하도록 지시한 후, reference count를 1로 감소시킨다.
다음으로, sample A2가 physical block 1에 쓸 때, reference count는 이미 1로 감소되어 있다.
따라서 A2는 새로 생성된 KV cache를 physical block 1에 직접 쓴다.
요약하자면, vLLM은 prompt의 KV cache를 저장하는 데 사용되는 대부분의 space를 여러 출력 sample에서 공유할 수 있도록 한다.
단, 최종 logical block은 copy-on-write mechanism으로 관리된다.
여러 sample에 physical block을 공유함으로써 특히 long input prompt에서 memory 사용량을 크게 줄일 수 있다.
Beam search
Machine translation $_[$$_{59}$$_]$과 같은 작업에서 사용자는 LLM에서 출력된 가장 적절한 번역의 top-$k$를 기대한다.
Beam search $_[$$_{49}$$_]$는 sample space를 완전히 탐색하는 computational complexity를 완화하기 때문에 LLM에서 가장 가능성 있는 output sequence를 decoding하는 데 널리 사용된다.
이 algorithm은 모든 단계에서 유지되는 최상위 후보의 수를 결정하는 beam width parameter $k$에 의존한다.
Decoding 하는 동안 beam search는 가능한 모든 token을 고려하여 beam의 각 후보 sequence를 확장하고 LLM을 사용하여 각각의 확률을 계산하며 $k\cdot|V|$ 후보 중 가장 가능성 있는 top-$k$ sequence를 유지한다.
여기서 $|V|$는 vocabulary size다.
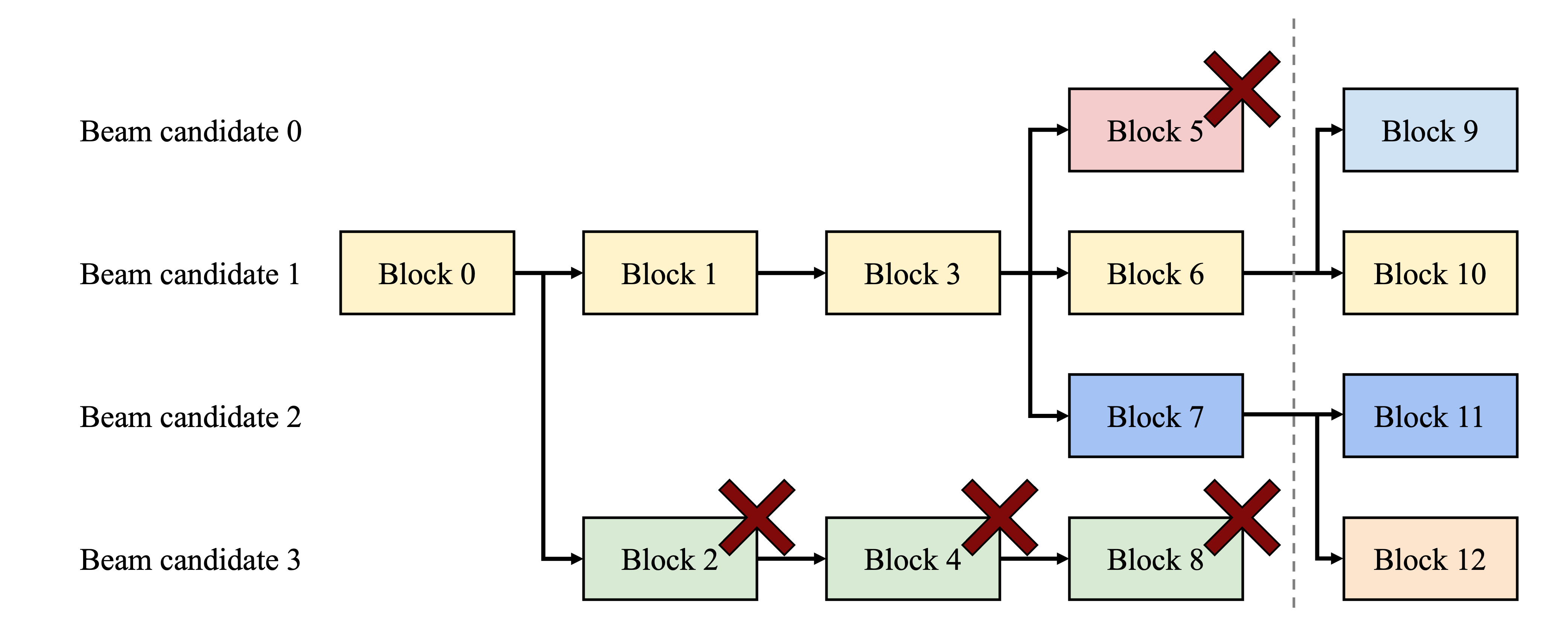
Figure 9. Beam search example.
Parallel decoding과 다르게, beam search는 initial prompt blocks 뿐만 아니라 여러 후보 block을 공유하며, 공유 pattern은 decoding process가 진행됨에 따라 동적으로 변경된다.
이는 OS에서 compound fork로 생성된 process tree와 유사하다.
Fig. 9는 vLLM이 $k=4$인 beam search 예제에서 KV block을 관리하는 방식을 보여준다.
점선으로 표시된 iteration 이전에 각 후보 sequence는 4개의 전체 logical block을 사용했다.
모든 beam 후보는 첫 번째 block 0 (i.e. prompt)을 공유한다.
후보 3은 두 번째 block에서 다른 후보들과 분리된다.
후보 0-2는 처음 3개의 block을 공유하고 네 번째 block에서 분기한다.
이후 iteration에서 상위 4개의 유력 후보는 모두 후보 1과 2에서 시작된다.
원래 후보 0과 3은 더 이상 상위 후보에 속하지 않으므로 logical block이 해제되고 해당 physical block의 reference count가 줄어든다.
vLLM은 reference count가 0에 도달한 모든 physical block (block 2, 4, 5, 8)을 해제한다.
그 이후, vLLM은 새 후보들의 새로운 KV cache를 저장하기 위해 새로운 physical block (block 9-12)을 할당한다.
이제 모든 후보는 block 0, 1, 3을 공유하고, 후보 0과 1은 block 6을 공유하며, 후보 2와 3은 block 7을 공유한다.
이전 LLM serving system은 beam 후보 간에 KV cache를 빈번하게 memory에 복사해야 했다.
예를 들어, Fig. 9의 점선 이후의 경우, 후보 3은 생성을 계속하기 위해 후보 2의 KV cache의 상당 부분을 복사해야 했다.
이러한 빈번한 memory copy overhead는 vLLM의 physical block 공유를 통해 크게 감소한다.
vLLM에서는 서로 다른 beam 후보의 대부분 block을 공유할 수 있다.
Copy-on-write mechanism은 parallel decoding처럼 새로 생성된 token이 이전 공유 block 내에 있을 때만 적용된다.
이는 data block 하나만 복사하는 것을 포함한다.
Shared prefix
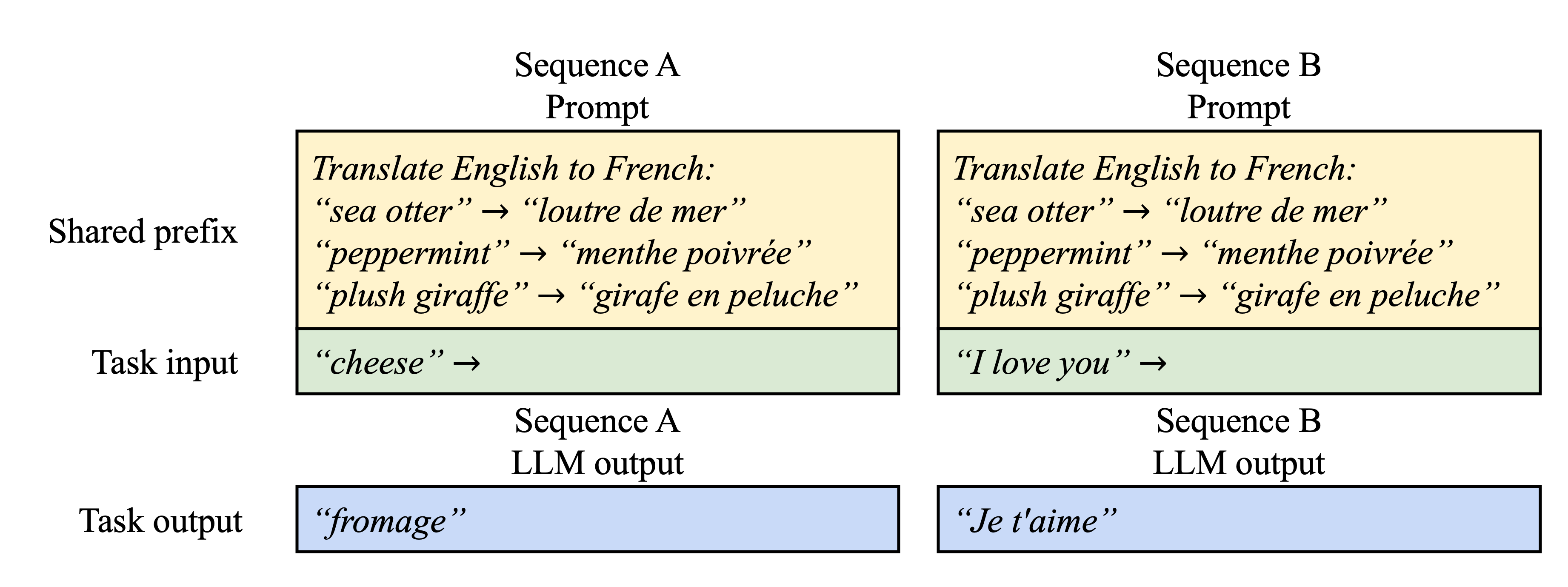
Figure 10. Shared prompt example for machine translation. The examples are adopted from $[$$5$$]$.
일반적으로 LLM 사용자는 instruction과 example input and output을 포함하는 작업에 대한 (긴) description을 제공하며, 이를 system prompt $_[$$_{36}$$_]$라고도 한다.
이 description은 actual task input과 연결되어 request prompt를 형성하며, LLM은 full prompt를 기반으로 출력을 생성한다.
Fig. 10은 이에 대한 예시를 보여주며 prompt engineering을 통해 shared prefix를 추가로 조정하여 downstream task의 정확도를 향상시킬 수 있다 $_[$$_{26}$$_,$$_{27}$$_]$.
이러한 유형의 application에서는 많은 사용자 prompt가 prefix를 공유하므로, LLM service provider는 prefix의 KV cache를 미리 저장하여 prefix에 소모되는 중복 계산을 줄일 수 있다.
vLLM에서는 OS가 process 간에 shared library를 처리하는 방식과 마찬가지로, LLM service provider가 미리 정의된 shared prefix 집합을 예약함으로써 이를 편리하게 구현할 수 있다.
Shared prefix가 있는 사용자 input prompt는 logical block을 cached physical prompt에 mapping할 수 있으며, 마지막 block은 copy-on-write로 표시된다.
Prompt phase의 계산은 사용자의 task input에 대해서만 실행되면 된다.
Mixed decoding methods
앞서 논의된 decoding 방법들이 다양한 memory sharing 및 accessing pattern을 보인다.
그럼에도 불구하고, vLLM은 기존 system에서는 효율적으로 처리할 수 없는, 서로 다른 decoding 선호도를 가진 요청의 동시 처리를 용이하게 한다.
이는 vLLM이 logical block을 physical block으로 변환하는 common mapping layer를 통해 서로 다른 sequence 간의 복잡한 memory sharing를 숨기기 때문이다.
LLM과 execution kernel은 각 sequence의 physical block ID 목록만 확인하며, sequence 간 sharing pattern을 처리할 필요가 없다.
기존 system과 비교했을 때, 이러한 접근 방식은 서로 다른 sampling 요구 사항을 가진 요청에 대한 batching 가능성을 넓혀 궁극적으로 system의 전체 throughput을 증가시킨다.
Scheduling and Preemption
Request traffic이 system의 capacity를 초과하면 vLLM은 일부 요청에 우선순위를 부여해야 한다.
vLLM에서는 모든 요청에 대해 first-come-first-serve (FCFS) scheduling policy를 적용하여 공정성을 보장하고 자원 고갈을 방지한다.
vLLM이 요청을 선점해야 하는 경우, 가장 먼저 도착한 요청부터 먼저 처리하고 가장 늦게 도착한 요청부터 먼저 처리하도록 한다.
LLM service는 고유한 과제에 직면한다: LLM의 input prompt는 길이가 상당히 다양할 수 있으며, 결과 출력 길이는 input prompt와 model 모두에 따라 사전에 알 수 없다.
요청 수와 출력 수가 증가함에 따라 vLLM은 새로 생성된 KV cache를 저장할 GPU의 physical block이 부족해질 수 있다.
이러한 context에서 vLLM은 두 가지 고전적 질문에 답해야 한다:
(1) 어떤 block을 evict해야 하는가?
(2) 필요한 경우 evicted block을 어떻게 복구할 수 있을까?
일반적으로 제거 정책은 heuristic을 사용하여 미래에 가장 먼저 access될 block을 예측하고 해당 block을 제거한다.
본 논문에서는 sequence의 모든 block이 함께 access된다는 것을 알고 있으므로, sequence의 모든 block을 제거하거나 전혀 제거하지 않는 all-or-nothing eviction policy를 구현한다.
또한, 한 요청 내에 여러 sequence (e.g., 하나의 beam search request 내의 beam 후보)는 sequence group으로 gang-scheduling된다.
한 sequence group 내의 sequence는 해당 sequence 간의 잠재적인 memory sharing으로 인해 항상 선점되거나 함께 rescheduling된다.
제거된 block을 복구하는 방법에 대한 두 번째 질문에 답하기 위해 두 가지 기술을 고려한다.
Swapping
이는 대부분의 virtual memory 구현에서 사용되는 고전적인 기술로, evicted page를 disk의 swap space에 복사한다.
본 논문에서는 evited block을 CPU memory에 복사한다.
Fig. 4에서 볼 수 있듯, vLLM은 GPU block allocator 외에도 CPU RAM으로 swap된 physical block을 관리하는 CPU block allocator를 포함한다.
vLLM이 새 token을 위해 사용 가능한 physical block을 모두 소진하면, 제거할 sequence set를 선택하고 해당 KV cache를 CPU로 전송한다.
Sequence를 선점하고 해당 block을 제거하면, vLLM은 선점된 모든 sequence가 완료될 때까지 새로운 요청 수신을 중단한다.
요청이 완료되면 해당 block은 memory에서 해제되고, 선점된 sequence의 block은 다시 memory에 돌아와 해당 sequence의 처리를 계속한다.
이 설계에서는 CPU RAM으로 swap된 block 수가 GPU RAM의 총 physical block 수를 초과하지 않으므로 CPU RAM의 swap space는 KV cache에 할당된 GPU memory에 의해 제한된다.
Recomputation
선점된 sequence가 rescheduling될 때 KV cache를 간단히 재계산한다.
Decoding 시 생성된 token을 원래 사용자 prompt에 새로운 prompt로 연결할 수 있으므로 recomputation latency 보다 훨씬 짧을 수 있다.
모든 위치의 KV cache는 한 번의 prompt phase iteration으로 생성될 수 있다.
Swapping 및 recomputation 성능은 CPU RAM과 GPU memory 간의 bandwidth과 GPU의 computation power에 따라 달라진다.
$\S7.3$에서 swapping 및 recomputation 속도를 살펴본다.
Distributed Execution
많은 LLM은 단일 GPU의 capacity를 초과하는 parameter size를 가진다 $_[$$_{5}$$_,$$_{9}$$_]$.
따라서 distributed GPU에 걸쳐 분할하고 model parallel 방식으로 실행해야 한다 $_[$$_{28}$$_,$$_{63}$$_]$.
이를 위해서는 distributed memory를 처리할 수 있는 memory manager가 필요하다.
vLLM은 Transformers에서 널리 사용되는 Megatron-LM style tensor model parallelism 전략을 지원하여 distributed 설정에 효과적이다 $_[$$_{47}$$_]$.
이 전략은 SPMD (Single Program Multiple Data) execution schedule을 따르며, 여기서 linear layer는 block 단위 matrix multiplication을 수행하도록 분할되고 GPU는 all-reduce 연산을 통해 중간 결과를 지속적으로 동기화한다.
구체적으로, attention operator는 attention head dimension에서 분할되고, 각 SPMD process는 multi-head attention에서 attention head의 하위 집합을 처리한다.
Model parallel execution을 사용하더라도 각 model shard는 여전히 동일한 input token set를 처리하므로 동일한 위치에 대한 KV cache가 필요하다.
따라서 vLLM은 Fig. 4와 같이 centralized scheduler 내에 단일 KV cache manager를 사용한다.
여러 GPU worker가 관리자를 공유하고 logical block에서 physical block으로의 mapping도 공유한다.
이러한 common mapping을 통해 GPU worker는 각 입력 요청에 대해 scheduler가 제공한 physical block을 사용하여 model을 실행할 수 있다.
각 GPU worker는 동일한 physical block ID를 가지지만, 각 worker는 해당 attention head에 대한 KV cache의 일부만 저장한다.
각 단계에서 scheduler는 먼저 batch의 각 요청에 대한 input token ID와 각 요청에 대한 block table이 포함된 message를 준비한다.
다음으로, scheduler는 이 control message를 GPU worker에게 broadcast한다.
그런 다음 GPU worker는 input token ID를 사용하여 model execution을 시작한다.
Attention layer에서 GPU worker는 control message의 blcok table에 따라 KV cache를 읽는다.
Execution 중에 GPU worker는 $_[$$_{47}$$_]$와 같이 scheduler의 조정 없이 중간 결과를 all-reduce communication primitive로 동기화한다.
마지막으로 GPU worker는 이 iteration의 sampled token을 scheduler로 다시 전송한다.
요약하면, GPU worker는 memory 관리에 대해 동기화할 필요가 없다.
각 decoding iteration의 시작 부분에서 step input과 함께 모든 memory 관리 정보만 받으면 되기 때문이다.
Implementation
vLLM은 FastAPI $_[$$_{15}$$_]$ frontend와 GPU 기반 inference engine을 갖춘 end-to-end serving system이다.
Frontend는 OpenAI API $_[$$_{34}$$_]$ interface를 확장하여 사용자가 최대 sequence 길이 및 beam width $k$와 같은 각 요청에 대한 sampling parameter를 사용자 정의할 수 있도록 한다.
vLLM engine은 8.5K 줄의 Python code와 2K 줄의 C++/CUDA code로 작성되었다.
PagedAttention과 같은 주요 작업을 위한 사용자 정의 CUDA kernel을 개발하는 동시에 Python에서 scheduler 및 block manager를 포함한 제어 관련 component를 개발했다.
Model executor의 경우 PyTorch $_[$$_{39}$$_]$와 Transformers $_[$$_{58}$$_]$를 사용하여 GPT $_[$$_{5}$$_]$, OPT $_[$$_{62}$$_]$ 및 LLaMA $_[$$_{52}$$_]$와 같은 인기 있는 LLM을 구현한다.
Distributed GPU worker 간 tensor communication을 위해 NCCL $_[$$_{32}$$_]$을 사용한다.
Kernel-level Optimization
PagedAttention은 기존 system에서 효율적으로 지원하지 않는 memory access pattern을 도입하기 때문에 최적화를 위해 여러 GPU kernel을 개발했다.
(1) Fused reshape and block write
모든 Transformer layer에서 새로운 KV cache는 block으로 분할되고, block 읽기에 최적화된 memory layout으로 재구성된 다음 block table에 지정된 위치에 저장된다.
Kernel launch overhead를 최소화하기 위해 이를 단일 kernel로 융합한다.
(2) Fusing block read and attention
FasterTransformer $_[$$_{31}$$_]$의 attention kernel을 block table에 따라 KV cache를 읽고 실시간으로 attention operation을 수행하도록 조정한다.
통합된 memory access를 보장하기 위해 각 block을 읽기 위한 GPU warp를 할당한다.
또한 request batch 내에서 가변 sequence 길이에 대한 지원을 추가한다.
(3) Fused block copy
Copy-on-write mechanism에 의해 발생하는 block copy operation은 discontinuous block에서 작동할 수 있다.cudaMemcpyAsync API를 사용하는 경우, 이로 인해 작은 data 이동이 여러번 호출될 수 있다.
Overhead를 완화하기 위해, 저자들은 서로 다른 block에 대한 복사 작업을 단일 kernel 실행으로 batch 처리하는 kernel을 구현한다.
Supporting Various Decoding Algorithms
vLLM은 fork, append, free라는 세 가지 주요 method를 사용하여 다양한 decoding algorithm을 구현한다.fork method는 기존 sequence에서 새 sequence를 생성한다.append method는 sequence에 새 token을 추가한다.free method는 sequence를 삭제한다.
예를 들어, parallel sampling에서 vLLM은 fork method를 사용하여 단일 input sequence에서 여러 개의 output sequence를 생성한다.
그 이후 append method를 사용하여 모든 iteration에서 이러한 sequence에 새 token을 추가하고, free method를 사용하여 중지 조건을 충족하는 sequence를 삭제한다.
vLLM의 beam search 및 prefix sharing에도 동일한 전략이 적용된다.
이러한 방식을 결합하여 향후 decoding algorithm을 지원할 수 있을 것으로 예상한다.
Evaluation
이 section에서는 다양한 workload에서 vLLM의 성능을 평가한다.
Experimental Setup
Model and server configurations
저자들은 평가를 위해 13B, 66B, 175B parameter를 가지는 OPT $_[$$_{62}$$_]$ model과 13B parameter를 가지는 LLaMA $_[$$_{52}$$_]$를 사용한다.
13B와 66B는 LLM leaderboard $_[$$_{38}$$_]$에서 확인할 수 있듯 LLM의 인기 있는 크기이고, 175B는 유명한 GPT-3 $_[$$_{5}$$_]$의 크기다.
모든 실험에서 Google Cloud Platform의 NVIDIA A100 GPU가 있는 A2 instance를 사용한다.
자세한 model의 크기와 server configuration은 Table 1과 같다.
Table 1. Model sizes and server configurations.
Model size 13B 66B 175B GPUs A100 4$\times$A100 8$\times$A100-80GB Total GPU memory 40 GB 160 GB 640 GB Parameter size 26 GB 132 GB 346 GB Memory for KV cache 12 GB 21 GB 264 GB Max. # KV cache slots 15.7K 9.7K 60.1K
Workloads
실제 LLM service의 입력 및 출력 text를 포함하는 ShareGPT $_[$$_{51}$$_]$ 및 Alpaca $_[$$_{50}$$_]$ dataset를 기반으로 workload를 합성한다.
ShareGPT dataset은 ChatGPT $_[$$_{35}$$_]$를 통해 사용자가 공유한 대화 모음이다.
Alpaca dataset는 GPT-3.5에서 self-instruct $_[$$_{57}$$_]$를 사용하여 생성한 명령어 dataset다.
Dataset를 token화하고 입력 및 출력 길이를 사용하여 client 요청을 합성한다.
ShareGPT dataset는 Alpaca dataset보다 평균 8.4배 더 긴 input prompt와 5.8배 더 긴 ouput을 가지며 분산이 더 높다.
이러한 dataset에는 timestamp가 포함되지 않으므로 다양한 요청률을 가지는 Poisson distribution을 사용하여 요청 도착 시간을 생성한다.
Baseline 1: FasterTransformer
FasterTransformer $_[$$_{31}$$_]$는 latency에 고도로 최적화된 distributed inference engine이다.
FasterTransformer는 자체 scheduler가 없으므로, Triton Inference Server $_[$$_{30}$$_]$와 같은 기존 serving system과 유사한 dynamic batching mechanism을 갖춘 custom scheduler를 구현한다.
구체적으로, GPU memory 용량에 따라 각 실험에 대해 가능한 큰 최대 batch size $B$를 설정한다.
Scheduler는 가장 먼저 도착한 요청 중 최대 $B$개의 요청을 처리하기 위해 batch를 FasterTransformer로 전송한다.
Baseline 2: Orca
Orca $_[$$_{60}$$_]$는 throughput에 최적화된 state-of-the-art LLM serving system이다.
Orca는 공개적으로 사용할 수 없으므로 자체 Orca version을 구현한다.
Orca는 buddy allocation algorithm을 사용하여 KV cache를 저장할 memory 주소를 결정한다고 가정한다.
요청 출력을 위해 space를 얼마나 초과 예약하는지에 따라 세 가지 Orca version을 구현한다.
- Orca (Oracle): System이 요청에 대해 실제로 생성될 출력의 길이를 알고 있다고 가정한다. 이는 Orca의 상한 성능을 보여주지만, 실제로는 달성하기 어렵다.
- Orca (Pow2): System이 출력 space를 최대 2배까지 초과 예약한다고 가정한다. 예를 들어, 실제 출력 길이가 25인 경우 출력용으로 32개의 위치를 예약한다.
- Orca (Max): System은 항상 model의 최대 sequence 길이, 즉 2048개 token까지 space를 예약한다고 가정한다.
Key metrics
본 논문에서는 serving throughput에 중점을 둔다.
특히, 다양한 request rate를 가진 workload를 사용하여 Orca $_[$$_{60}$$_]$와 같이 system의 normalized latency를 측정한다.
Normalized latency는 각 요청의 end-to-end latency의 평균을 출력 길이로 나눈 값이다.
High-throughput serving system은 높은 request rate에 대해 낮은 normalized latency를 유지해야 한다.
대부분의 실험에서 1시간 trace를 사용하여 system을 평가한다.
예외적으로, 비용 제한으로 인해 OPT-175B model에는 15분 trace를 사용한다.
Basic Sampling
세 가지 model과 두 가지 dataset에 대해 basic sampling (request 당 하나의 sample)을 사용하여 vLLM의 성능을 평가했다.
ShareGPT dataset에 대해 request rate가 증가함에 따라 latency가 처음에는 점진적으로 증가하다가 갑자기 폭발적으로 증가한다.
이는 request rate가 serving system의 capacity를 초과할 때 queue length가 무한히 증가하고 request latency도 증가하기 때문이다.
ShareGPT dataset에서 vLLM은 Orca (Oracle) 대비 1.7$\times$-2.7$\times$, Orca (Max) 대비 2.7$\times$-8$\times$ 더 높은 request rate를 유지하면서도 유사한 latency를 유지할 수 있다.
이는 vLLM의 PagedAttention이 memory usage를 효율적으로 관리하여 Orca보다 더 많은 요청을 batching할 수 있기 떄문이다.
예를 들어, OPT-13B의 경우 vLLM은 Orca (Oracle) 대비 2.2$\times$, Orca (Max) 대비 $\times$ 더 많은 요청을 동시에 처리한다.
FasterTransformer와 비교했을 때, vLLM은 최대 22$\times$ 더 높은 요청률을 감당할 수 있는데, FasterTransformer는 세분화된 scheduling mechanism을 사용하지 않고 Orca (Max)처럼 memory를 비효율적으로 관리하기 때문이다.
Alpaca dataset도 ShareGPT dataset와 유사한 추세를 보이지만, OPT-175B에 대해 vLLM이 Orca (Oracle) 및 Orca (Pow2)에 비해 우위를 점하는 정도가 덜 두드러지는 예외가 존재한다.
이는 OPT-175B (Table 1)의 model 및 server configuration이 KV cache를 저장하는 데 사용할 수 있는 대용량 GPU memory space를 허용하는 반면, Alpaca dataset는 sequence가 짧기 때문이다.
이 설정에서 Orca (Oracle) 및 Orca (Pow2)는 memory management의 비효율성에도 불구하고 많은 수의 요청을 일괄 처리할 수 있다.
결과적으로 system의 performance는 memory-bound가 아닌 compute-bound가 된다.
Parallel Sampling and Beam Search
PagedAttention에서 memory sharing의 효율성을 두 가지 널리 사용되는 sampling 방법인 parallel sampling과 beam search를 통해 평가한다.
Parallel sampling에서는 요청의 모든 parallel sequence가 prompt에 대한 KV cache를 공유할 수 있다.
Sampling할 sequence 수가 많을수록 vLLM은 Orca baseline보다 더 큰 성능 향상을 가져온다.
마찬가지로, 다양한 beam width를 사용한 beam search는 공유를 더 허용하기 때문에 vLLM은 더 큰 성능 이점을 보여준다.
OPT-13B와 Alpaca dataset 환경에서, vLLM은 Orca (Oracle)에 비해 basic sampling 방식에서는 1.3$\times$, width가 6인 beam search에서는 2.3$\times$ 더 높은 성능을 보였다.
공유를 통해 절약된 block 수를 공유하지 않은 전체 block 수로 나누어 memory 절약량을 계산했을 때, parallel sampling에서는 6.1% - 9.8%, beam search에서는 37.6% - 55.2%의 memory 절약 효과를 보였다.
ShareGPT dataset을 사용한 동일한 실험에서는 parallel sampling에서 16.2% - 30.5%, beam search에서 44.3% - 66.3%의 memory 절약 효과를 확인했다.
Shared prefix
Fig. 10과 같이 prefix가 여러 input prompt에서 공유되는 경우 vLLM의 효과를 탐구한다.
Model의 경우 다국어를 지원하는 LLaMA-13B $_[$$_{52}$$_]$를 사용한다.
Workload의 경우 WMT16 $_[$$_{4}$$_]$ English-to-German translation dataset를 사용하고 instruction과 몇 가지 translation example을 포함하는 두 개의 prefix를 합성한다.
첫 번째 prefix에는 단일 예제 (i.e., one-shot)가 포함되는 반면 다른 prefix에는 5개의 예제 (i.e., few-shot)가 포함된다.
One-shot prefix가 공유될 때 vLLM은 Orca (Oracle)보다 1.67$\times$ 더 높은 throughput을 달성한다.
또한 더 많은 예제가 공유될 때, vLLM은 Orca (Oracle)보다 3.58$\times$ 더 높은 throughput을 달성한다.
Chatbot
Chatbot $_[$$_{8}$$_,$$_{19}$$_,$$_{35}$$_]$은 LLM의 가장 중요한 응용 분야 중 하나이다.
Chatbot을 구현하기 위해, model이 chatting history 기록과 마지막 사용자 query를 연결하여 prompt를 생성하도록 했다.
ShareGPT dataset를 사용하여 chatting 기록과 사용자 query를 합성했다.
OPT-13B model의 제한된 context 길이로 인해, prompt를 마지막 1024개 token으로 줄이고 model이 최대 1024개 token을 생성하도록 했다.
서로 다른 conversation round 사이에 KV cache를 저장하지 않는 이유는, 이렇게 하면 conversation round 사이에 다른 요청을 위한 space가 차지되기 때문이다.
vLLM이 세 가지 Orca baseline보다 2배 더 높은 throughput을 유지할 수 있으며, ShareGPT dataset에는 긴 대화가 많이 포함되어 있으므로 대부분의 요청에 대한 input prompt는 1024개의 token을 갖는다.
Buddy allocation algorithm으로 인해 Orca baseline은 출력 길이 예측 방식과 관계없이 요청 출력에 1024개의 token을 위한 space를 예약한다.
이러한 이유로 세 가지 Orca baseline은 유사하게 동작한다.
반면, vLLM은 PagedAttention이 memory fragmentation 및 reservation 문제를 해결하므로 긴 prompt를 효과적으로 처리할 수 있다.
Ablation Studies
이 section에서는 vLLM의 다양한 측면을 연구하고, design choice들을 ablation experiment를 통해 평가한다.
Kernel Microbenchmark
PagedAttention의 dynamic block mapping은 저장된 KV cache와 관련된 GPU operation, 즉 block read/write 및 attention 성능에 영향을 미친다.
기존 system과 비교했을 때, 본 논문의 GPU kernel ($\S5$)은 block table 접근, 추가 branch 실행, 가변 sequence 길이 등 추가적인 overhead를 발생시킨다.
이로 인해 고도로 최적화된 FasterTransformer 구현에 비해 attention kernel latency가 20-26% 더 길어진다.
Attention operator에만 영향을 미치고 Linear와 같은 다른 operator에는 영향을 미치지 않으므로 overhead는 작다고 판단한다.
이러한 overhead에도 불구하고, PagedAttention은 vLLM이 end-to-end performance 측면에서 FasterTransformer보다 훨씬 우수한 성능을 발휘하도록 한다 ($\S6$).
Impact of Block Size
Block size 선택은 vLLM 성능에 상당한 영향을 미칠 수 있다.
Block size가 너무 작으면 vLLM이 KV cache를 읽고 처리하는 데 GPU의 parallelism을 충분히 활용하지 못할 수 있다.
Block size가 너무 크면 internal fragmentation이 증가하고 공유 가능성이 감소한다.
Fixed request rate에서 basic sampling을 적용한 ShareGPT 및 Alpaca trace를 사용하여 다양한 block size에 따른 vLLM의 성능을 평가한다.
ShareGPT trace에서는 block size가 16에서 128까지일 때 가장 좋은 성능을 보인다.
Alpaca trace에서는 block size가 16과 32일 때 잘 작동하지만, block size가 커지면 sequence가 block size보다 짧아지기 때문에 성능이 크게 저하된다.
실제로 block size 16은 GPU를 효율적으로 활용하기에 충분히 크고 대부분의 workload에서 심각한 internal fragmentation을 피할 수 있을 만큼 작다.
따라서 vLLM은 기본 block size를 16으로 설정한다.
Comparing Recomputation and Swapping
vLLM은 recovery mechanism으로 recomputation과 swapping을 모두 지원한다.
두 방법 간의 장단점을 이해하기 위해 end-to-end performance를 평가하고 overhead를 microbenchmark했다.
결과에 따르면 swapping은 작은 block size에서 과도한 overhead를 발생시킨다.
이는 작은 block size가 CPU와 GPU 간에 수많은 소규모 data transfer이 발생하게 되고, 이것이 결국 effective PCIe bandwidth를 제한하기 때문이다.
반면, recomputation overhead는 KV block을 사용하지 않으므로 block size에 관계없이 일정하게 유지된다.
따라서 block size가 작을 때는 recomputation이 더 효율적이고, block size가 클 때는 swapping이 더 효율적이다.
단, recomputation overhead는 swapping latency의 20%를 넘지 않는다.
16에서 64까지의 중간 block size에서는 두 방법이 비슷한 end-to-end performance를 보인다.
Discussion
Applying the virtual memory and paging technique to other GPU workloads
Virtual memory와 paging이라는 개념은 LLM serving에서 KV cache를 관리하는 데 효과적이다.
Workload는 dynamic memory allocation (출력 길이가 사전에 알려지지 않음)을 필요로 하고, performance는 GPU memory capacity에 따라 결정되기 때문이다.
하지만 이는 모든 GPU workload에 적용되는 것은 아니다.
예를 들어, DNN 학습에서 tensor shape는 일반적으로 정적이므로 memory allocation을 미리 최적화할 수 있다.
또 다른 예로, LLM이 아닌 DNN을 serving할 경우, performance는 주로 compute-bound이기 때문에 memory efficiency 증가가 performance 향상으로 이어지지 않을 수 있다.
이러한 상황에서 vLLM technique를 도입하더라도 memory indirection과 non-contiguous block memory로 인한 extra overhead 때문에 오히려 성능을 저하시킬 수 있다.
하지만 LLM serving과 유사한 특성을 가진 다른 workload에도 vLLM technique가 적용되기를 기대한다.
LLM-specific optimizations in applying virtual memory and paging
vLLM은 application-specific semantic를 활용하여 virtual memory와 paging이라는 개념을 재해석하고 확장한다.
한 가지 예로, vLLM의 all-or-nothing swap-out policy는 요청 처리 시 모든 token state가 GPU memory에 저장되어야 한다는 점을 활용한다.
또 다른 예로, OS에서는 구현이 불가능한, evicted block을 복구하는 recomputation method가 있다.
또한, vLLM은 memory access operation을 위한 GPU kernel과 attention과 같은 다른 operation을 위한 kernel을 fusing하여 paging에서 memory indirection으로 인한 overhead를 완화한다.
Related Work
General model serving systems
Model serving은 최근 몇 년 동안 활발한 연구 분야였으며, deep learning model deployment의 다양한 측면을 해결하기 위해 수많은 system이 제안되었다.
Clipper $_[$$_{11}$$_]$, TensorFlow Serving $_[$$_{33}$$_]$, Nexus $_[$$_{45}$$_]$, InferLine $_[$$_{10}$$_]$ 및 Clockwork $_[$$_{20}$$_]$는 일부 초기 general model serving system이다.
이들은 단일 또는 다중 model을serving하기 위한 batching, caching, placement 및 scheduling을 연구한다.
최근에는 DVABatch $_[$$_{12}$$_]$가 multi-entry multi-exit batching을 도입한다.
REEF $_[$$_{21}$$_]$ 및 Shepherd $_[$$_{61}$$_]$는 serving을 위한 선점을 제안한다.
AlpaServe $_[$$_{28}$$_]$는 statistical multiplexing을 위해 model parallelism을활용한다.
그러나 이러한 general system은 LLM inference의 autoregressive 속성 및 token state를 고려하지 못하여 최적화 기회를 놓치게 된다.
Specialized serving systems for transformers
Transformer architecture의 중요성으로 인해, 이를 위한 수많은 전문화된 serving system이 개발되었다.
이러한 system은 효율적인 serving을 위해 GPU kernel 최적화 $_[$$_{1}$$_,$$_{29}$$_,$$_{31}$$_,$$_{56}$$_]$, advanced batching mechanism $_[$$_{14}$$_,$$_{60}$$_]$, model parallelism $_[$$_{1}$$_,$$_{41}$$_,$$_{60}$$_]$, 그리고 parameter sharing $_[$$_{64}$$_]$를 활용한다.
그중에서도 Orca $_[$$_{60}$$_]$가 본 논문의 접근 방식과 가장 관련이 깊다
Comparison to Orca
Orca $_[$$_{60}$$_]$의 iteration-level scheduling과 vLLM의 PagedAttention은 상호 보완적인 기술이다.
두 system 모두 GPU 활용도를 높히고 LLM serving의 throughput을 늘리는 것을 목표로 하지만 Orca는 요청을 scheduling하고 interleaving하여 더 많은 요청을 병렬로 처리할 수 있도록 하는 반면, vLLM은 memory utilization을 높여 더 많은 요청의 working set가 memory에 맞도록 한다.
Memory fragementation을 줄이고 공유를 활성화함으로써 vLLM은 batch에서 더 많은 요청을 병렬로 실행하고 Orca에 비해 2-4$\times$의 속도 향상을 달성한다.
실제로 Orca와 같은 요청의 세분화된 scheduling 및 interleaving은 memory management를 더 어렵게 만들어 vLLM에서 제안된 기술이 더욱 중요해졌다.
Memory optimizations
Accelerator의 compute capability와 memory capacity 간의 격차가 확대됨에 따라 memory는 학습 및 추론 모두에게 bottleneck이 되었다.
Seapping $_[$$_{23}$$_,$$_{42}$$_,$$_{55}$$_]$, recomputation $_[$$_{7}$$_,$$_{24}$$_]$ 및 이들의 조합 $_[$$_{40}$$_]$은 학습의 최대 memory 사용량을 줄이기 위해 활용되어 왔다.
특히 FlexGen $_[$$_{46}$$_]$은 제한된 GPU memory를 사용하여 LLM inference를 위한 weight와 token state를 swap하는 방법을 연구하지만, online serving 설정을 대상으로 하지 않았다.
OLLA $_[$$_{48}$$_]$는 단편화를 줄이기 위해 tensor의 lifetime과 location을 최적화하지만, 세분화된 block 수준 관리나 online serving은 수행하지 않았다.
FlashAttention $_[$$_{13}$$_]$은 tiling 및 kernel 최적화를 적용하여 attention 계산의 최대 memory 사용량을 줄이고 I/O 비용을 줄인다.
본 논문은 online serving context에서 block-level memory management에 대한 새로운 idea를 소개한다.
Conclusion
본 논문은 attention key와 value를 non-contiguous paged memory에 저장할 수 있는 새로운 attention algorithm인 PagedAttention을 제안하고, PagedAttention을 통해 효율적인 memory management가 가능한 high-throughput LLM serving system인 vLLM을 제시한다.
Operating system에서 영감을 받아, virtual memory 및 copy-on-write와 같은 기존 기술을 어떻게 적용하여 KV cache를 효율적으로 관리하고 LLM serving에서 다양한 decoding algorithm을 처리할 수 있는지 보여준다.
실험 결과, vLLM은 state-of-the-art system 대비 throughput이 2-4$\times$ 향상됨을 보여준다.
References
- SC 2022: DeepSpeed Inference: Enabling Efficient Inference of Transformer Models at Unprecedented Scale
- arXiv 2016: Layer Normalization
- NeurIPS 2000: A Neural Probabilistic Language Model
- WMT 2016: Findings of the 2016 Conference on Machine Translation
- NeurIPS 2020: Language Models are Few-Shot Learners
- arXiv 2021: Evaluating Large Language Models Trained on Code
- arXiv 2016: Training Deep Nets with Sublinear Memory Cost
- LMSYS ORG 2023: Vicuna: An Open-Source Chatbot Impressing GPT-4 with 90%* ChatGPT Quality
- JMLR 2022: PaLM: Scaling Language Modeling with Pathways
- SoCC 2020: InferLine: latency-aware provisioning and scaling for prediction serving pipelines
- NSDI 2017: Clipper: A Low-Latency Online Prediction Serving System
- USENIX ATC 2022: DVABatch: Diversity-aware Multi-Entry Multi-Exit Batching for Efficient Processing of DNN Services on GPUs
- NeurIPS 2022: FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness
- PPoPP 2021: TurboTransformers: An Efficient GPU Serving System For Transformer Models
- GitHub 2023: fastapi/fastapi
- EuroSys 2018: Low latency RNN inference with cellular batching
- arXiv 2024: AI and Memory Wall
- GitHub 2022: Copilot
- Google 2023: Bard
- OSDI 2020: Serving DNNs like Clockwork: Performance Predictability from the Bottom Up
- OSDI 2022: Microsecond-scale Preemption for Concurrent GPU-accelerated DNN Inferences
- CVPR 2016: Deep Residual Learning for Image Recognition
- ASPLOS 2020: SwapAdvisor: Pushing Deep Learning Beyond the GPU Memory Limit via Smart Swapping
- MLSys 2020: Checkmate: Breaking the Memory Wall with Optimal Tensor Rematerialization
- IRE Transactions on Electronic Computers 1962: One-Level Storage System
- EMNLP 2021: The Power of Scale for Parameter-Efficient Prompt Tuning
- arXiv 2021: Prefix-Tuning: Optimizing Continuous Prompts for Generation
- OSDI 2023: AlpaServe: Statistical Multiplexing with Model Parallelism for Deep Learning Serving
- OSDI 2020: Rammer: Enabling Holistic Deep Learning Compiler Optimizations with rTasks
- GitHub 2018: triton-inference-server/server
- GitHub 2023: NVIDIA/FasterTransformer
- NVIDIA 2023: NVIDIA Collective Communications Library (NCCL)
- NeurIPS 2017: TensorFlow-Serving: Flexible, High-Performance ML Serving
- OpenAI 2020: OpenAI API
- OpenAI 2022: Introducing ChatGPT
- OpenAI 2023: Custom instructions for ChatGPT
- arXiv 2023: GPT-4 Technical Report
- LMSYS ORG 2023: Chatbot Arena Leaderboard Week 8: Introducing MT-Bench and Vicuna-33B
- NeurIPS 2019: PyTorch: An Imperative Style, High-Performance Deep Learning Library
- ICML 2022: POET: Training Neural Networks on Tiny Devices with Integrated Rematerialization and Paging
- arXiv 2022: Efficiently Scaling Transformer Inference
- USENIX ATC 2021: ZeRO-Offload: Democratizing Billion-Scale Model Training
- Ruters 2023: Focus: For tech giants, AI like Bing and Bard poses billion-dollar search problem
- AWS 2023: Amazon Bedrock
- SOSP 2019: Nexus: a GPU cluster engine for accelerating DNN-based video analysis
- ICML 2023: FlexGen: High-Throughput Generative Inference of Large Language Models with a Single GPU
- arXiv 2019: Megatron-LM: Training Multi-Billion Parameter Language Models Using Model Parallelism
- arXiv 2022: OLLA: Optimizing the Lifetime and Location of Arrays to Reduce the Memory Usage of Neural Networks
- NeurIPS 2014: Sequence to Sequence Learning with Neural Networks
- GitHub 2023: tatsu-lab/stanford_alpaca
- ShareGPT 2023
- arXiv 2023: LLaMA: Open and Efficient Foundation Language Models
- NeurIPS 2017: Attention Is All You Need
- USENIX ATC 2022: Pacman: An Efficient Compaction Approach for Log-Structured Key-Value Store on Persistent Memory
- PPoPP 2018: SuperNeurons: Dynamic GPU Memory Management for Training Deep Neural Networks
- NAACL 2021: LightSeq: A High Performance Inference Library for Transformers
- ACL 2023: Self-Instruct: Aligning Language Models with Self-Generated Instructions
- EMNLP 2020: Transformers: State-of-the-art Natural Language Processing
- arXiv 2016: Google’s Neural Machine Translation System: Bridging the Gap between Human and Machine Translation
- OSDI 2022: Orca: A Distributed Serving System for Transformer-Based Generative Models
- NSDI 2023: SHEPHERD: Serving DNNs in the Wild
- arXiv 2022: OPT: Open Pre-trained Transformer Language Models
- OSDI 2022: Alpa: Automating Inter- and Intra-Operator Parallelism for Distributed Deep Learning
- USENIX ATC 2022: PetS: A Unified Framework for Parameter-Efficient Transformers Serving