
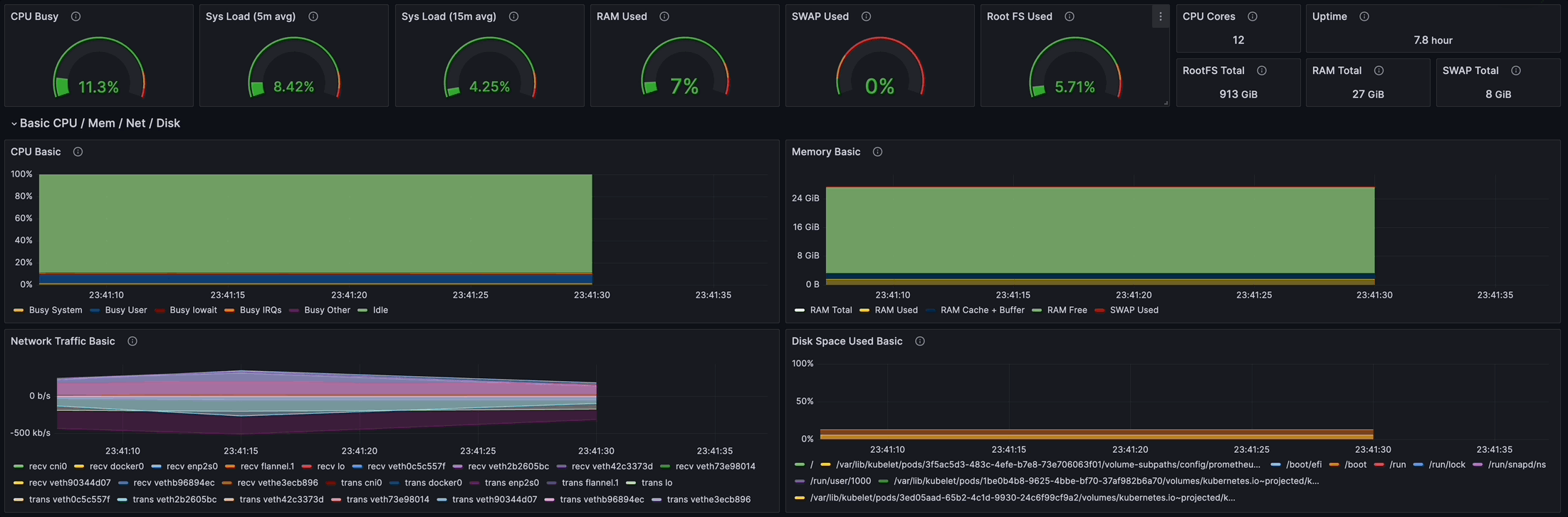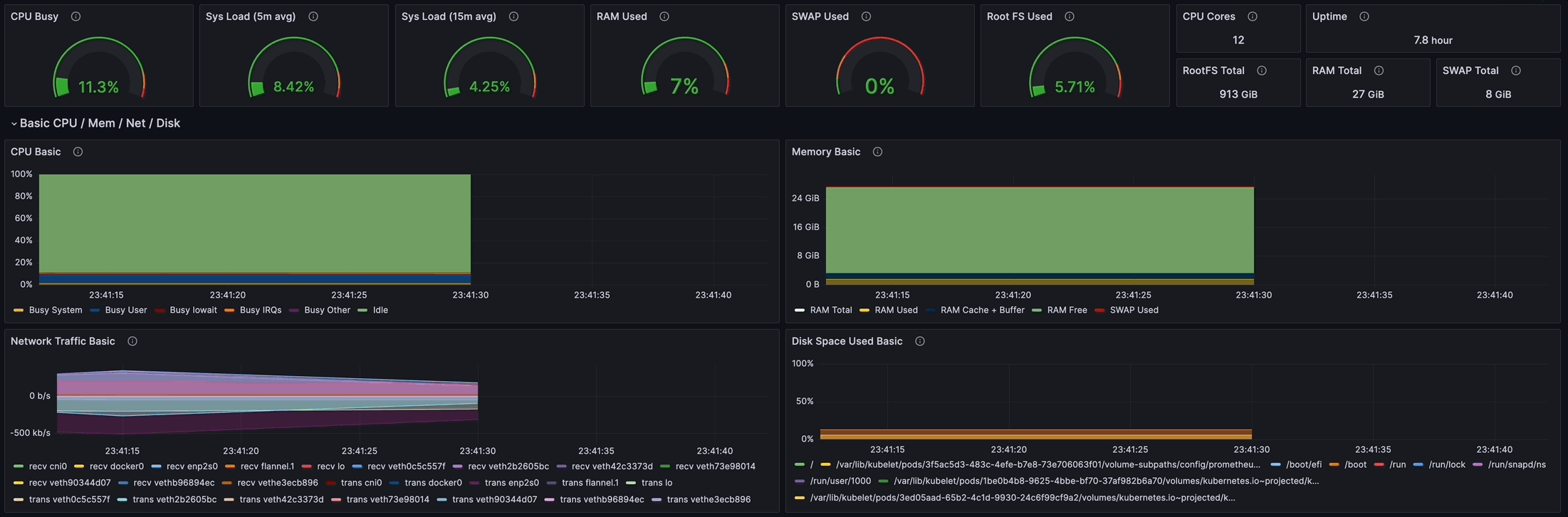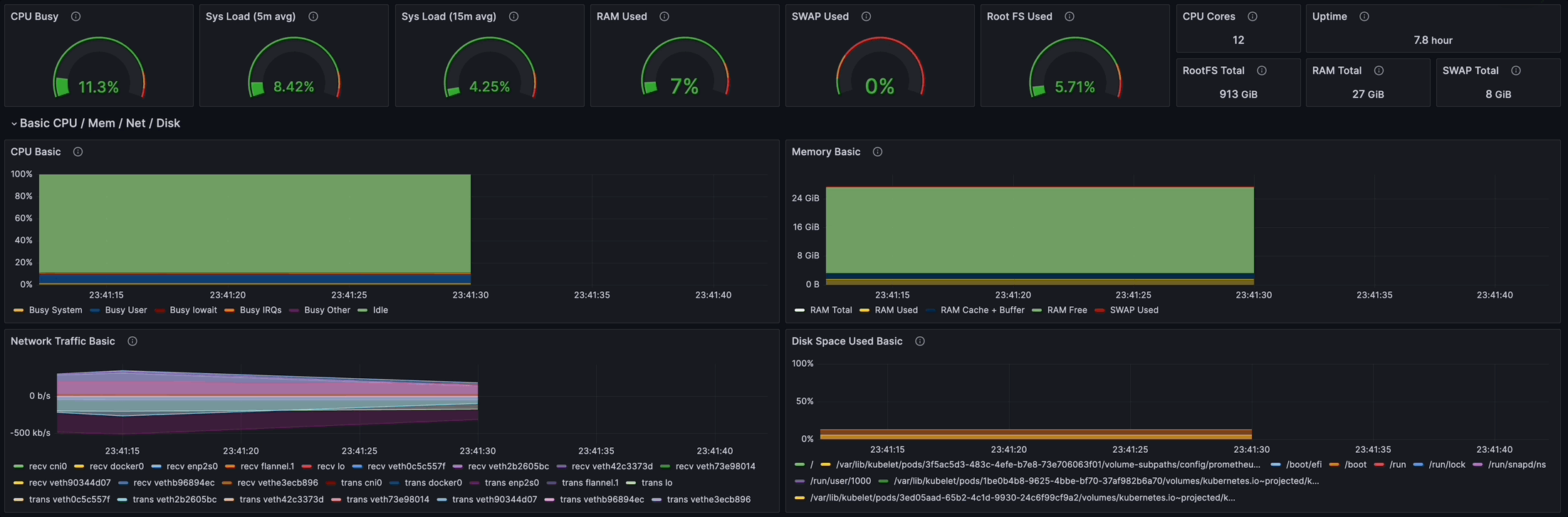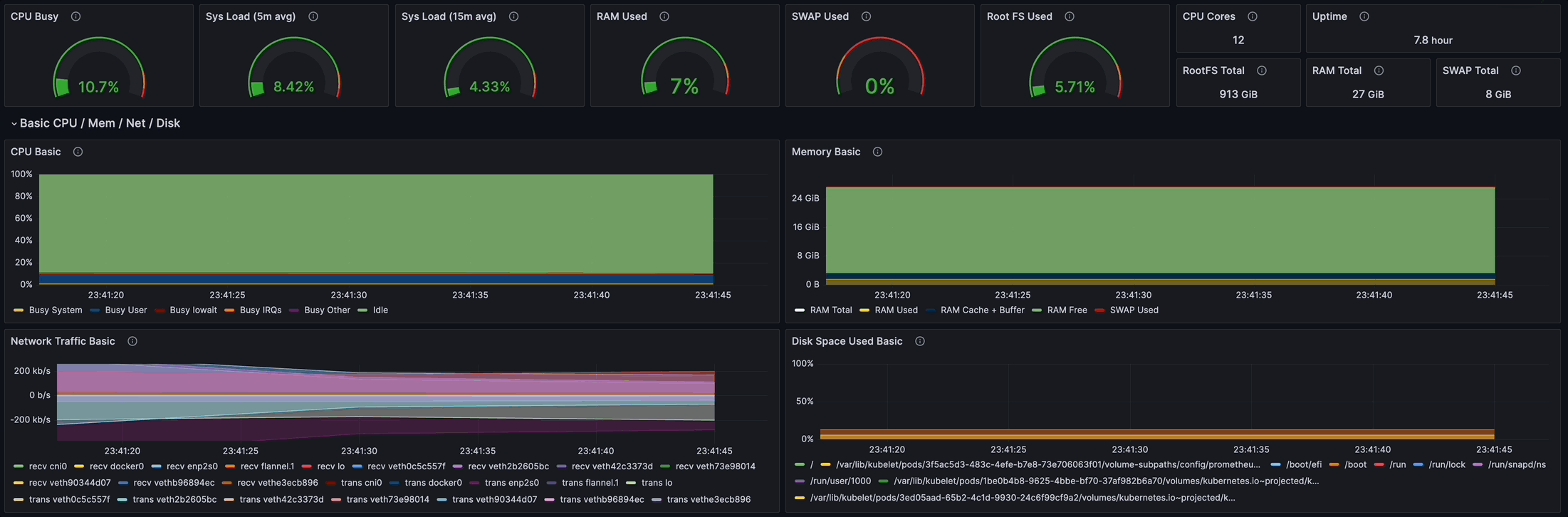
Kubeflow
Introduction
Kubeflow: Machine learning 및 Deep learning workload를 위한 오픈 소스 플랫폼으로, Kubernetes 위에서 실행되며 ML workload의 배포, 관리 및 확장을 용이하게 해줍니다. Kubeflow는 Kubernetes의 높은 가용성, 확장성 및 관리성과 machine learning 작업에 필요한 도구와 라이브러리를 통합하여 종합적인 ML 작업 플로우를 제공합니다.

Why Kubeflow?
- Scalable ML Workload Management
- Kubernetes의 강력한 scaling 및 관리 기능을 활용하여 ML workload를 효율적으로 배포하고 관리
- 자동화된 scaling과 resource 관리는 복잡한 ML 작업에서 유용
- Portable Environments
- 인프라 구성을 추상화하고 portable한 ML 작업 환경을 제공하여 로컬 머신에서 클라우드까지 다양한 환경에서 일관된 방식으로 작업할 수 있는 환경 구축
- Integrated Components
- Machine learning 작업을 위한 다양한 컴포넌트를 통합하여 제공
- Jupyter Notebook, TensorBoard, TensorFlow Serving, …
- Designed Pipelines
- Kubeflow Pipelines를 통해 End-to-End machine learning workflow를 시각적으로 디자인 및 실행 가능
- 반복적인 작업을 자동화하고 재현 가능한 실험 수행
Home Server 구축기
Introduction
이 영상을 보며 뽐뿌가 온 나머지,,, 홈 서버로 사용하기 위해 아래와 같은 스펙으로 주문했다!!!
| Type | Link | Price |
|---|---|---|
| Case | ASRock DeskMini X300 120W | 215,000원 |
| CPU | AMD Ryzen 5 5600G + Thermal grease | 166,500원 |
| Fan | Noctua NH-L9a-AM4 | 75,990원 |
| RAM | SAMSUNG Notebook DDR4 16GB PC4-25600 $\times$ 2 | 77,860원 |
| SSD | SK Hynix GOLD P31 NVMe SSD M.2 NVMe 1TB | 87,500원 |
총 622,850원으로 구성할 수 있었다.
Python의 빠른 연산을 위한 Process 기반 병렬 처리
Introduction
회사에서 약 17,000장 가량의 고화질 이미지 데이터를 처리해야하는 일이 생겼는데 총 처리 시간이 약 10시간 가량 소요됐다.
너무 오랜 시간이 소요되기 때문에 이를 빠르게 바꿔보고자 병렬 처리를 해보려고 했다.
먼저 생각난 키워드는 multithreading이여서 threading 라이브러리에 대해 찾아보게 되었다.
하지만 python은 한 thread가 python 객체에 대한 접근을 제어하는 mutex인 GIL (Global Interpreter Lock)이 존재하여 CPU 작업이 적고 I/O 작업이 많은 처리에서 효과를 볼 수 있다. (더 이상은 너무 어려워요,,,)
Cython에서는 이렇게 nogil=True로 정의해 GIL를 해제하고 병렬 처리를 할 수 있다.
그렇다면 현재 문제인 대량의 고화질 이미지 데이터를 최대한 빠르게 처리하려면 어떻게 해야할까?
이 경우에는 process 기반의 병렬 처리를 지원하는 multiprocessing 라이브러리를 사용하면 된다.