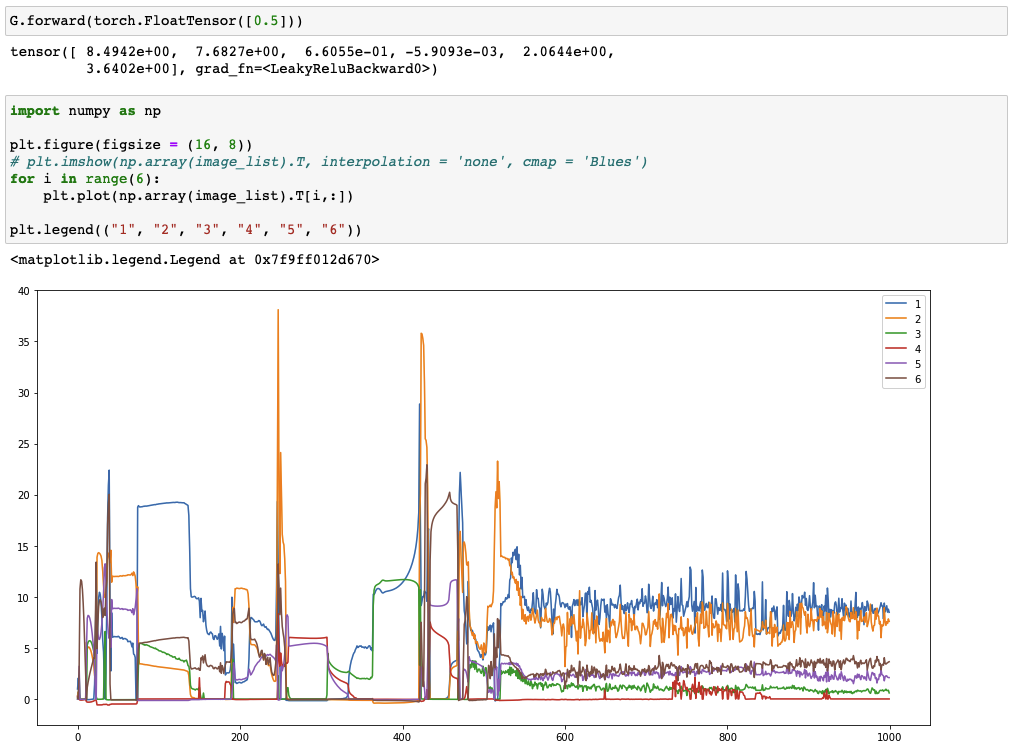
Generative Adversarial Network (2)
GAN (Generative Adversarial Network)
Image Generation
- Traditional neural network: 정보를 감소, 정제, 축약
- Ex) $28\times28\rightarrow784\ (input)\rightarrow10\rightarrow1\ (output)$
- Backquery: 기존의 신경망을 반대로 뒤집어 레이블을 통해 이미지 생성 (원핫 인코딩 벡터를 훈련된 네트워크에 넣어 레이블에 맞는 이상적 이미지 생성)
- Ex) $1\ (input)\rightarrow10\rightarrow784\ (output)\rightarrow28\times28$
- 같은 원핫 인코딩 벡터인 경우 같은 결과 출력
- 각 레이블을 나타내는 모든 훈련 데이터의 평균적 이미지 도출 $\rightarrow$ 한계점 (훈련 샘플로 사용 불가)
Adversarial Training
생산적 적대 신경망 (Generative Adversarial Network, GAN)의 기본 개념
- Generator (생성기): 허구의 이미지를 생성하는 신경망
- 판별기를 속이는 경우 보상
- 판별기에게 적발될 경우 벌
- Discriminator (판별기): 실제 이미지와 허구 이미지를 분류하는 신경망
- 생성기를 통해 생성된 이미지를 허구 이미지로 분류한 경우 보상
- 생성기를 통해 생성된 이미지를 실제 이미지로 분류한 경우 벌
GAN Training
- 실제 데이터를 판별기가
1로 분류할 수 있도록 판별기 업데이트 - 생성기를 통해 생성된 데이터를
0으로 분류할 수 있도록 판별기만을 업데이트 (생성기 업데이트 X) - 판별기가 생성기를 통해 생성된 데이터를
1로 분류하도록 생성기만을 업데이트 (판별기 업데이트 X)
- 생성기와 판별기가 서로 적대적인 (두 모델의 성능이 비슷) 경우 적절한 훈련 가능
- 생성기 혹은 판별기 중 한 모델만 성능이 개선될 경우 최종 성능의 큰 하락 발생
Simple Pattern
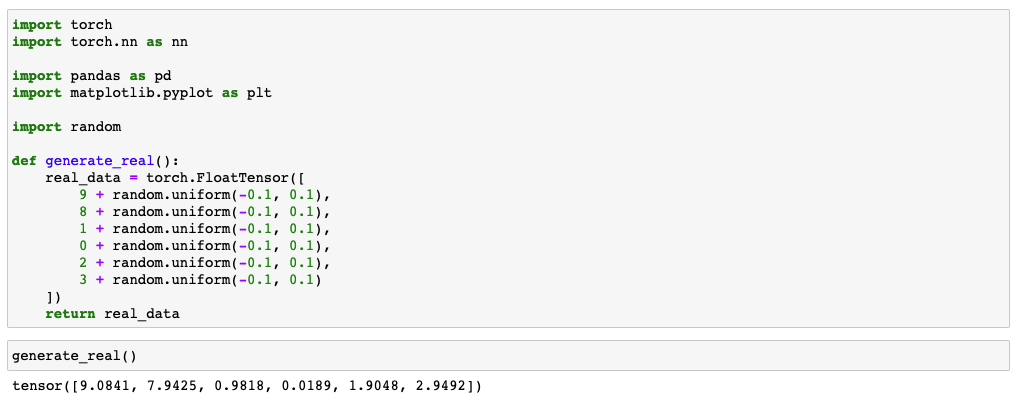
Real Data Source
Real data generation function
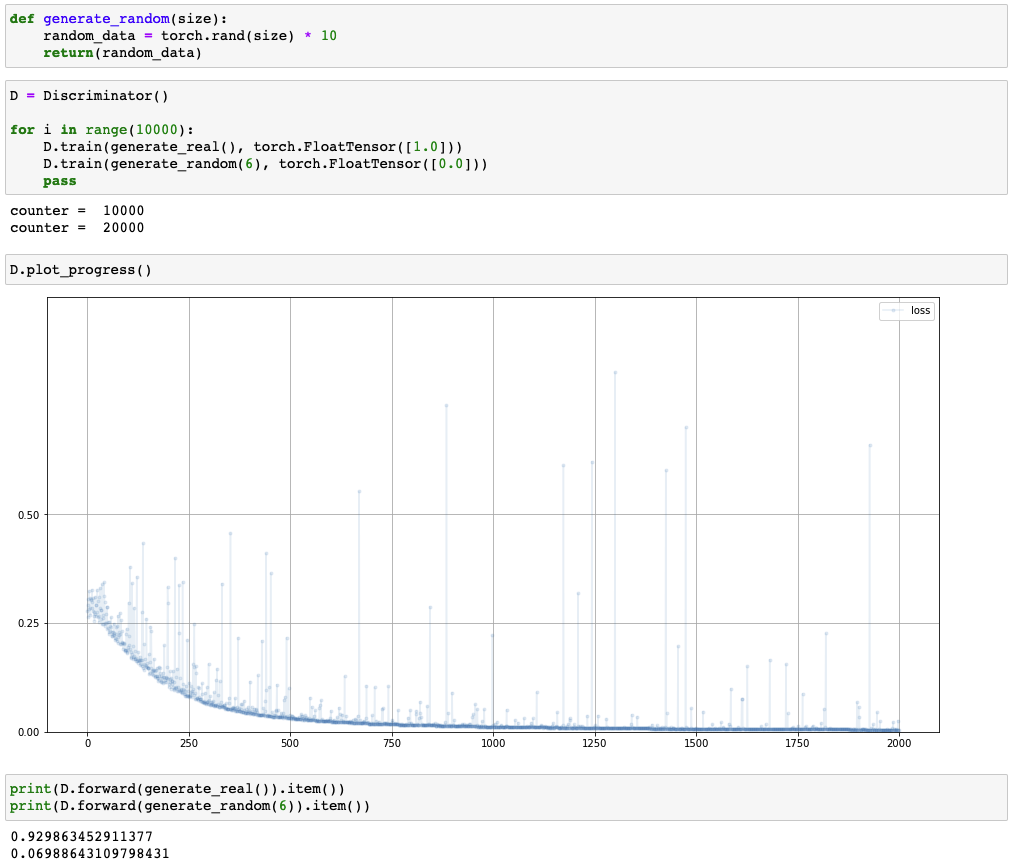
Discriminator
Discriminator
1 | class Discriminator(nn.Module): |
Training discriminator
Generator
Generator
1 | class Generator(nn.Module): |
self.loss: 생성기는 판별기로부터 입력된 기울기 오차를 통해 업데이트되므로 생성기의 손실 함수는 정의되지 않음self.train(): 생성기 훈련 시 판별기의 결과로 계산된 손실의 역전파 값 필요- 입력값 $\rightarrow$
self.forward(inputs)$\rightarrow$g_output D.forward(g_output)$\rightarrow$d_output
- 손실은
d_output과 목푯값 간의 차이로 산출 - 손실로부터 오차 역전파 $\rightarrow$
self.optimiser(D.optimiserX)
- 입력값 $\rightarrow$
GAN Training
GAN Training
1 | D = Discriminator() |
- 판별기 및 생성기의 객체 생성
- 실제 데이터에 대해 판별기 훈련
- 생성기에서 생성된 데이터를 판별기에 훈련
detach(): 생성기의 출력에 적용되어 계산에서 생성기 분리- 생성기의 출력에 적용
- 효율적이고 빠른 결과 도출을 위해 사용
backwards(): 판별기의 손실에서 기울기 오차를 계산의 전 과정에 걸쳐 계산- 판별기의 손실, 판별기, 생성기까지 모두 전해짐
- 이 단계에서는 판별기를 훈련하는 것이므로 생성기의 기울기를 계산할 필요 X
- 생성기 훈련 및 입력값을 0.5로 설정하여 판별기 객체에 전달
detach()X: 오차가 판별기로부터 생성기까지 전달돼야함
Loss of discriminator and generator
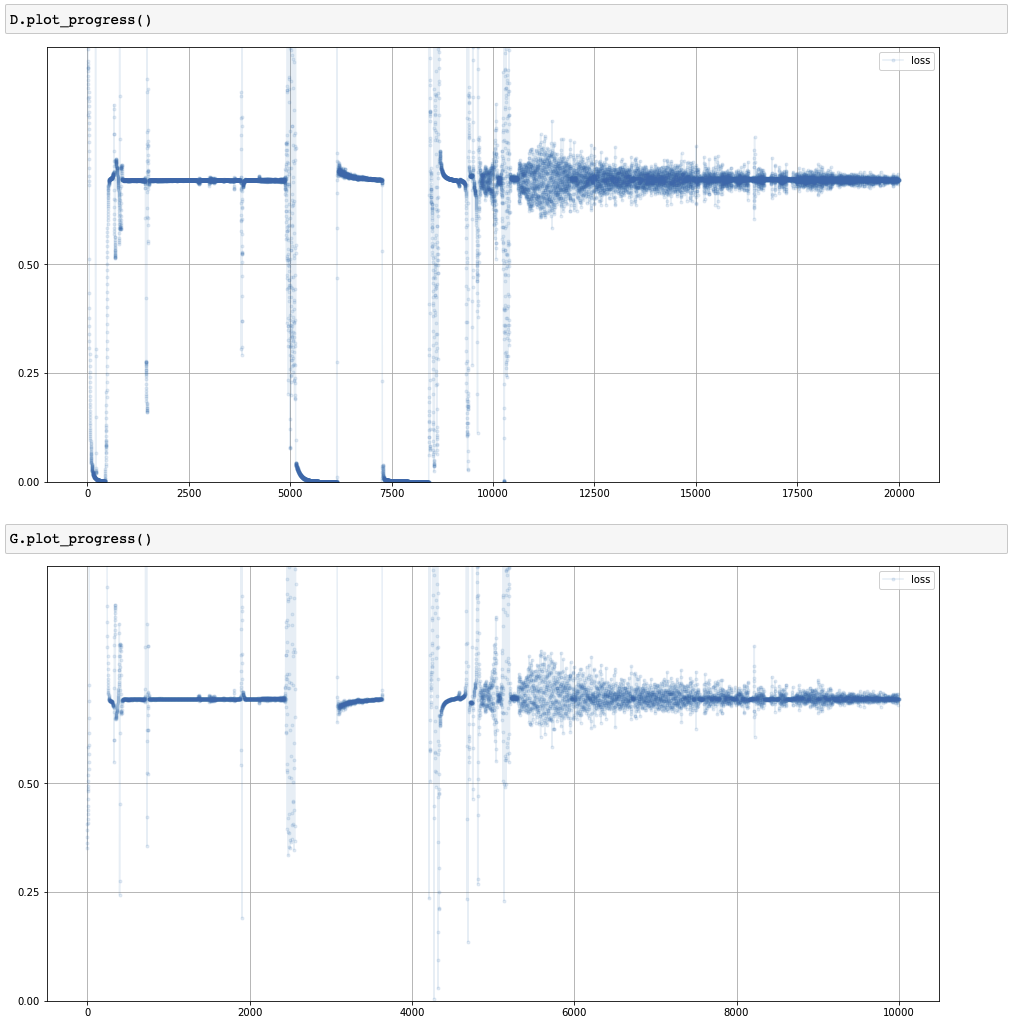
- 판별기와 생성기의 손실: 0.69에 수렴
- 이진 교차 엔트로피 (
BCELoss())에서의 $ln(2)$- 판별기가 실제 데이터와 생성된 데이터를 잘 판별하지 못함
- 생성기가 판별기를 속일 수 있는 성능
- 평균제곱오차 (
MSELoss()): 0.25- 판별기가 실제 이미지와 생성 이미지를 잘 판별하지 못한 경우 $\rightarrow$ 출력:
0.5 - $0.5^2 = 0.25$
- 판별기가 실제 이미지와 생성 이미지를 잘 판별하지 못한 경우 $\rightarrow$ 출력:
- 이진 교차 엔트로피 (
Pattern of generator as training progresses