Introduction YOLOv5 모델을 ONNX로 변환하여 Triton Inference Server로 배포 한 경험은 있지만, Amazon EC2 Inf1 을 통해 모델을 배포하고 REST API를 직접 구성해본 경험은 없어 직접 inference server와 API server를 구성해보려고한다.공식 문서 와 참고 자료 들도 존재하지만 실질적 개발을 하는데 있어 막히는 부분이 꽤 많아 기록으로 남긴다.
Local 내 구현
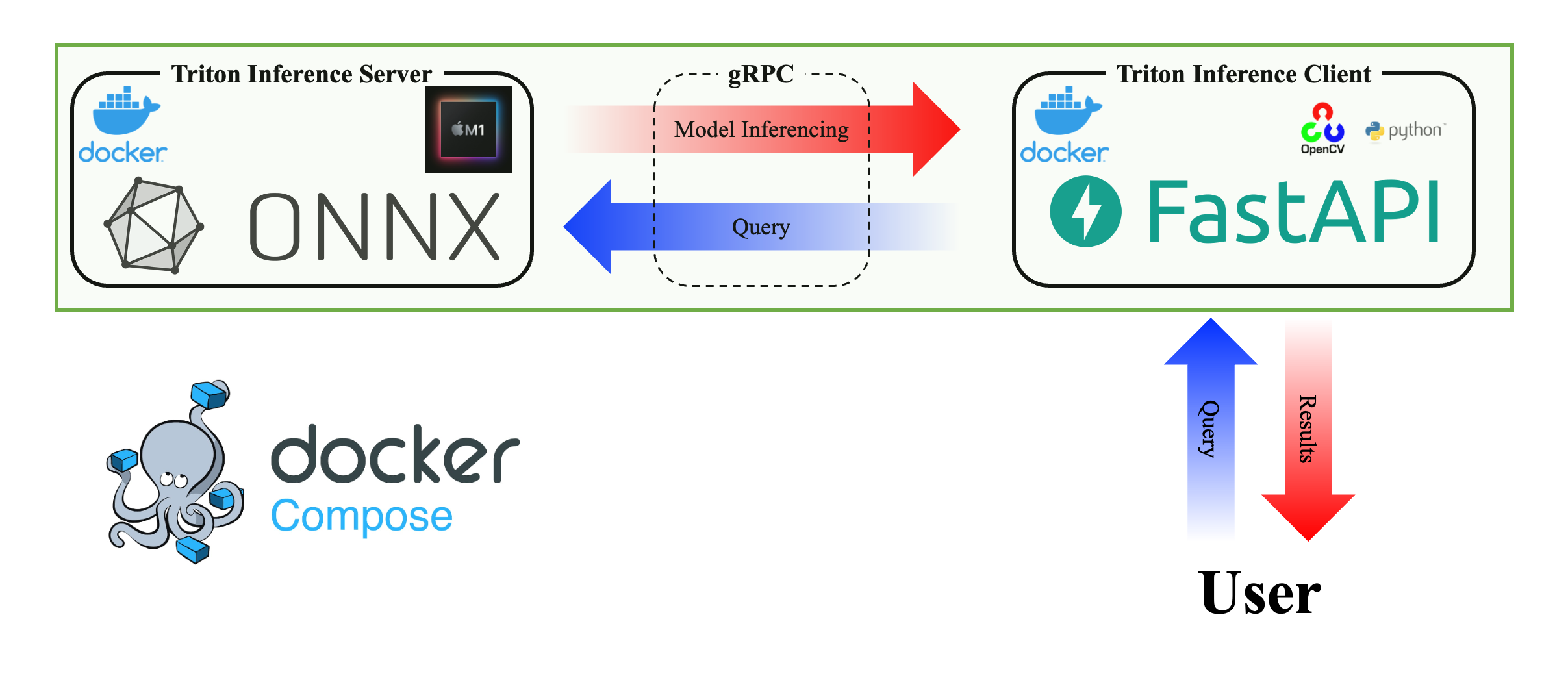
Local 환경이 Apple Silicon이다보니 GPU를 통한 inference는 불가하지만 연습을 위해 local 내에서 Triton Inference Server를 구축하고, 손쉬운 입출력을 위해 FastAPI도 함께 개발했다.
Triton Inference Server Triton Inference Server를 구축하기 위해서 아래와 같이 directory 구성을 했다.
Server 1 2 3 4 5 6 7 └── server ├── Dockerfile └── model-repository └── BoonMoSa ├── 1 │ └── model.onnx └── config.pbtxt
간편한 모델 서빙을 위해 PyTorch 기반의 YOLOv5를 ONNX로 변환하였고, 아래의 config.pbtxt로 해당 모델의 정보를 설정했다.
config.pbtxt 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 name: "BoonMoSa" platform: "onnxruntime_onnx" input [ { name: "images" data_type: TYPE_FP32 dims: [1 ,3 ,640 ,640 ] } ] output [ { name: "output0" data_type: TYPE_FP32 dims: [1 ,25200 ,38 ] }, { name: "output1" data_type: TYPE_FP32 dims: [1 ,32 ,160 ,160 ] } ]
모든 설정을 마쳤다면 Triton Inference Server의 이미지를 불러오고 실행시키면된다.
server/Dockerfile 1 FROM nvcr.io/nvidia/tritonserver:23.06 -py3
docker build 시 Dockerfile 내의 이미지를 바로 사용해도 되지만, 차후에 생길 수 있는 변경 (python backend로의 전환 및 다른 라이브러리들의 기용)에 대비하기 위해 별도로 Dockerfile을 생성했다.
build_server.sh 1 2 3 4 5 6 7 8 9 10 docker build -t boonmosa_server:dev ./server docker run -itd \ --pid=host \ --shm-size=4gb \ -p 8000:8000 -p 8001:8001 -p 8002:8002 \ -v ${PWD} /server/model-repository:/model-repository \ --name BoonMoSa_TritonInferenceServer \ boonmosa_server:dev \ tritonserver --model-repository=/model-repository --strict-model-config=false --log-verbose=1 --backend-config=python,grpc-timeout-milliseconds=50000 && \ docker logs -f BoonMoSa_TritonInferenceServer
Triton Inference Server를 build 하려면 위와 같이 실행하면 된다.
1 2 3 Started GRPCInferenceService at 0.0.0.0:8001 Started HTTPService at 0.0.0.0:8000 Started Metrics Service at 0.0.0.0:8002
FastAPI 최종적인 목표는 user가 모델을 사용하고 싶을 때 아래와 같은 요청으로 최종 결과를 수령하는 것이다.
1 $ curl -X GET localhost:80/inference?file_id=test.png
이를 위해서 Triton Inference Server가 구동되고 있을 때 테스트를 위해 local에서 바로 실행할 수 있는 client 코드를 개발했다.
client_test.py 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 import numpy as npimport cv2from tritonclient.utils import *import tritonclient.grpc as grpcclientdef Inference (IMAGE_PATH ): SERVER_URL = 'localhost:8001' MODEL_NAME = 'BoonMoSa' dectection_image_path = IMAGE_PATH.split('.' )[-2 ] + "-seg.png" dectection_boxes_path = IMAGE_PATH.split('.' )[-2 ] + "-seg.txt" image = cv2.imread(IMAGE_PATH) image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB) input_image, r, _ = letterbox(image) input_image = input_image.astype('float32' ) input_image = input_image.transpose((2 ,0 ,1 ))[np.newaxis, :] / 255.0 input_image = np.ascontiguousarray(input_image) with grpcclient.InferenceServerClient(SERVER_URL) as triton_client: inputs = [ grpcclient.InferInput("images" , input_image.shape, np_to_triton_dtype(np.float32)) ] inputs[0 ].set_data_from_numpy(input_image) outputs = [ grpcclient.InferRequestedOutput("output0" ), grpcclient.InferRequestedOutput("output1" ) ] response = triton_client.infer( model_name=MODEL_NAME, inputs=inputs, outputs=outputs ) response.get_response() output0 = response.as_numpy("output0" ) output1 = response.as_numpy("output1" ) return image, r, output0, output1, dectection_image_path, dectection_boxes_path if __name__ == "__main__" : tar = 'test.jpg' image, r, output0, output1, dectection_image_path, dectection_boxes_path = Inference(tar) results = output0.copy() protos = output1.copy() overlay = image.copy() ll = 1 results[0 , :, 0 ] = (results[0 , :, 0 ] - results[0 , :, 2 ] / 2 ) / r[0 ] results[0 , :, 1 ] = (results[0 , :, 1 ] - results[0 , :, 3 ] / 2 ) / r[1 ] results[0 , :, 2 ] /= r[0 ] results[0 , :, 3 ] /= r[1 ] bboxes = results[0 , :, :4 ] confidences = results[0 , :, 4 ] scores = confidences.reshape(-1 , 1 ) * results[0 , :, 5 :ll+5 ] masks = results[0 , :, ll+5 :] CONF_THRESHOLD = 0.03 IOU_THRESHOLD = 0.5 MASK_THRESHOLD = 0.5 indices = cv2.dnn.NMSBoxes( bboxes.tolist(), confidences.tolist(), CONF_THRESHOLD, IOU_THRESHOLD) color=(255 , 0 , 0 ) thickness=2 for i in indices: bbox = bboxes[i].round ().astype(np.int32) _, score, _, class_id = cv2.minMaxLoc(scores[i]) class_id = class_id[1 ] if score >= CONF_THRESHOLD: c = bbox[:2 ] h = bbox[2 :] p1, p2 = c, (c + h) p1, p2 = p1.astype('int32' ), p2.astype('int32' ) cv2.rectangle(image, p1, p2, color, thickness) x,y,w,h = map (int , bbox * np.array([r[0 ], r[1 ], r[0 ], r[1 ]]) * 160 / 640 ) proto = protos[0 ,:,y:y+h,x:x+w].reshape(32 , -1 ) proto = np.expand_dims(masks[i], 0 ) @ proto proto = (1 / (1 + np.exp(-proto))).sum (0 ) proto = proto.reshape(h, w) mask = cv2.resize(proto, (bbox[2 ], bbox[3 ])) mask = mask >= MASK_THRESHOLD to_mask = overlay[bbox[1 ]:bbox[1 ]+bbox[3 ], bbox[0 ]:bbox[0 ]+bbox[2 ]] mask = mask[:to_mask.shape[0 ], :to_mask.shape[1 ]] to_mask[mask] = [255 , 0 , 0 ] else : alpha = 0.5 image = cv2.addWeighted(image, 1 - alpha, overlay, alpha, 0 ) cv2.imwrite(dectection_image_path, image[:, :, ::-1 ])
해당 코드는 전처리, Triton Inference Server에 gRPC로 inference 요청, 후처리 순서로 진행된다.
Client 1 2 3 4 5 6 7 8 9 10 └── client ├── Dockerfile ├── app │ ├── app.py │ ├── client.py │ └── requirements.txt ├── inputs │ └── test.png └── outputs └── test-seg.png
위의 client_test.py에서 사용하는 라이브러리와 FastAPI를 사용하기 위해 아래와 같은 client.py, app.py, Dockerfile을 구성했다.
client.py 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 import timeimport numpy as npimport cv2from tritonclient.utils import *import tritonclient.grpc as grpcclientdef Inference (IMAGE_PATH ): SERVER_URL = 'BoonMoSa_TritonInferenceServer:8001' MODEL_NAME = 'BoonMoSa' dectection_image_path = 'outputs/' + IMAGE_PATH.split('.' )[-2 ] + "-seg.png" dectection_boxes_path = 'outputs/' + IMAGE_PATH.split('.' )[-2 ] + "-seg.txt" IMAGE_PATH = 'inputs/' + IMAGE_PATH image = cv2.imread(IMAGE_PATH) image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB) input_image, r, _ = letterbox(image) input_image = input_image.astype('float32' ) input_image = input_image.transpose((2 ,0 ,1 ))[np.newaxis, :] / 255.0 input_image = np.ascontiguousarray(input_image) with grpcclient.InferenceServerClient(SERVER_URL) as triton_client: inputs = [ grpcclient.InferInput("images" , input_image.shape, np_to_triton_dtype(np.float32)) ] inputs[0 ].set_data_from_numpy(input_image) outputs = [ grpcclient.InferRequestedOutput("output0" ), grpcclient.InferRequestedOutput("output1" ) ] response = triton_client.infer( model_name=MODEL_NAME, inputs=inputs, outputs=outputs ) response.get_response() output0 = response.as_numpy("output0" ) output1 = response.as_numpy("output1" ) return image, r, output0, output1, dectection_image_path, dectection_boxes_path def main (IMAGE_PATH ): START = time.time() image, r, output0, output1, dectection_image_path, dectection_boxes_path = Inference(IMAGE_PATH) results = output0.copy() protos = output1.copy() overlay = image.copy() ll = 1 results[0 , :, 0 ] = (results[0 , :, 0 ] - results[0 , :, 2 ] / 2 ) / r[0 ] results[0 , :, 1 ] = (results[0 , :, 1 ] - results[0 , :, 3 ] / 2 ) / r[1 ] results[0 , :, 2 ] /= r[0 ] results[0 , :, 3 ] /= r[1 ] bboxes = results[0 , :, :4 ] confidences = results[0 , :, 4 ] scores = confidences.reshape(-1 , 1 ) * results[0 , :, 5 :ll+5 ] masks = results[0 , :, ll+5 :] CONF_THRESHOLD = 0.03 IOU_THRESHOLD = 0.5 MASK_THRESHOLD = 0.5 indices = cv2.dnn.NMSBoxes( bboxes.tolist(), confidences.tolist(), CONF_THRESHOLD, IOU_THRESHOLD) color=(255 , 0 , 0 ) thickness=2 for i in indices: bbox = bboxes[i].round ().astype(np.int32) _, score, _, class_id = cv2.minMaxLoc(scores[i]) class_id = class_id[1 ] if score >= CONF_THRESHOLD: c = bbox[:2 ] h = bbox[2 :] p1, p2 = c, (c + h) p1, p2 = p1.astype('int32' ), p2.astype('int32' ) cv2.rectangle(image, p1, p2, color, thickness) x,y,w,h = map (int , bbox * np.array([r[0 ], r[1 ], r[0 ], r[1 ]]) * 160 / 640 ) proto = protos[0 ,:,y:y+h,x:x+w].reshape(32 , -1 ) proto = np.expand_dims(masks[i], 0 ) @ proto proto = (1 / (1 + np.exp(-proto))).sum (0 ) proto = proto.reshape(h, w) mask = cv2.resize(proto, (bbox[2 ], bbox[3 ])) mask = mask >= MASK_THRESHOLD to_mask = overlay[bbox[1 ]:bbox[1 ]+bbox[3 ], bbox[0 ]:bbox[0 ]+bbox[2 ]] mask = mask[:to_mask.shape[0 ], :to_mask.shape[1 ]] to_mask[mask] = [255 , 0 , 0 ] else : alpha = 0.5 image = cv2.addWeighted(image, 1 - alpha, overlay, alpha, 0 ) cv2.imwrite(dectection_image_path, image[:, :, ::-1 ]) END = time.time() return END - START if __name__ == "__main__" : main("test.png" )
app.py 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 from fastapi import FastAPIfrom client import mainapp = FastAPI() @app.get("/inference" def inference (file_id: str ='test.png' ): pt = main(file_id) return { "request_info" : { "file_id" : file_id, "process_time" : pt } }
여기서 유의할 부분은 SERVER_URL = 'BoonMoSa_TritonInferenceServer:8001'으로 설정해줘야 Triton Inference Server container를 지정해야하는 것이다.
client/Dockerfile 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 FROM tiangolo/uvicorn-gunicorn:python3.8 RUN mkdir -p /app WORKDIR /app COPY ${PWD} /client/app/* /app/ ENV TZ Asia/SeoulENV LC_ALL C.UTF-8 RUN apt-get update RUN apt-get install -y libgl1-mesa-glx RUN pip install --upgrade pip RUN pip install --no-cache-dir --upgrade -r ./requirements.txt CMD ["gunicorn" , "-k" , "uvicorn.workers.UvicornWorker" , "--bind" , "0.0.0.0:80" , "--log-level" , "debug" , "app:app" ]
이렇게 구성된 이미지를 바로 실행한다면 FastAPI에서 아래와 같은 에러가 발생할 것이다.
1 2 3 4 5 tritonclient.utils.InferenceServerException: [StatusCode.UNAVAILABLE] failed to connect to all addresses; last error: UNKNOWN: ipv4:0.0.0.0:8001: Failed to connect to remote host: Connection refused tritonclient.utils.InferenceServerException: [StatusCode.UNAVAILABLE] DNS resolution failed for BoonMoSa_TritonInferenceServer:8001: C-ares status is not ARES_SUCCESS qtype=A name=BoonMoSa_TritonInferenceServer is_balancer=0: Domain name not found
이것은 두 컨테이너가 연결되어있지 않아 발생하는 오류이기 때문에 docker-compose를 이용한다.
Docker Compose docker-compose.yaml 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 version: "3" services: tritoninferenceserver: build: context: . dockerfile: ./server/Dockerfile container_name: BoonMoSa_TritonInferenceServer volumes: - ${PWD}/server/model-repository:/model-repository command: tritonserver --model-repository=/model-repository --strict-model-config=false --log-verbose=1 --backend-config=python,grpc-timeout-milliseconds=50000 ports: - 8000 :8000 - 8001 :8001 - 8002 :8002 shm_size: 4gb pid: host fastapi: build: context: . dockerfile: ./client/Dockerfile container_name: BoonMoSa_FastAPI volumes: - ${PWD}/client/inputs:/app/inputs - ${PWD}/client/outputs:/app/outputs ports: - 80 :80 networks: default: name: BoonMoSa-network
이렇게 구성하면 아래와 같이 네트워크가 잘 연결된 것을 확인할 수 있다.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 $ docker compose up -d $ docker network inspect BoonMoSa-network [ { "Name": "BoonMoSa-network", "Id": "1cff935beba5c1f409ba0e4c5e9bb651d8be9a11f07c1031491d9957be133f12", "Created": "2023-07-11T23:44:59.90219476Z", "Scope": "local", "Driver": "bridge", "EnableIPv6": false, "IPAM": { "Driver": "default", "Options": null, "Config": [ { "Subnet": "172.19.0.0/16", "Gateway": "172.19.0.1" } ] }, "Internal": false, "Attachable": false, "Ingress": false, "ConfigFrom": { "Network": "" }, "ConfigOnly": false, "Containers": { "7a9dc227bb1e2d16345062bd88b3da1d1eb78bb382828dd1c582f3e3e75b8744": { "Name": "BoonMoSa_TritonInferenceServer", "EndpointID": "4be40c82992fab15f4515d7af756d216f7d17cdb37be814da9c6c69303f253c7", "MacAddress": "02:42:ac:13:00:03", "IPv4Address": "172.19.0.3/16", "IPv6Address": "" }, "e12bfac3246b89a25a6528a2ecf7c704dafd30edcf5d4cbe120513a113e7c031": { "Name": "BoonMoSa_FastAPI", "EndpointID": "bc2d820a830ac3007b8607cdc3220f8d4a261b22250b5595d1b05c77769c5e57", "MacAddress": "02:42:ac:13:00:02", "IPv4Address": "172.19.0.2/16", "IPv6Address": "" } }, "Options": {}, "Labels": { "com.docker.compose.network": "default", "com.docker.compose.project": "aws-ec2-inf1", "com.docker.compose.version": "2.15.1" } } ]
최종 결과 확인을 위해 curl로 FastAPI container에 요청을 보내면 아래와 같이 잘 실행됨을 확인할 수 있다!
1 2 $ curl -X GET 'localhost:80/inference?file_id=test.png' {"request_info":{"file_id":"test.png","process_time":1.9295954704284668}}
이렇게 진행해보며 Docker Compose와 Kubernetes의 차이가 궁금해 아래와 같이 정리했다.
Docker Compose vs. Kubernetes
Docker Compose와 Kubernetes는 모두 컨테이너 오케스트레이션 도구이지만, 목표와 사용 시나리오에서 차이가 있습니다.
Docker Compose
Kubernetes
목표
단일 호스트에서 멀티 컨테이너 애플리케이션을 개발 및 실행하는 것을 간소화합니다.
컨테이너화된 애플리케이션을 여러 호스트에서 배포, 확장 및 관리하는 것을 중앙 집중화된 방식으로 제공합니다.
스케일링 및 클러스터링
단일 호스트에서 여러 컨테이너를 실행하는 데 사용되며, 확장이나 로드 밸런싱에 제한이 있습니다.
여러 호스트에서 컨테이너를 실행하는 클러스터를 구성하며, 컨테이너의 수평 확장, 자동 로드 밸런싱, 자가 치유 등의 기능을 제공합니다.
서비스 디스커버리와 로드 밸런싱
컨테이너 간 통신에 대한 내부 DNS 이름을 제공하지만, 외부에 노출된 서비스를 관리하거나 로드 밸런싱을 수행하는 기능은 제공하지 않습니다.
서비스 디스커버리를 위해 내부 DNS를 제공하고, 로드 밸런싱을 수행하는 서비스 리소스를 제공합니다.
선언적 구성 및 상태 관리
YAML 파일을 사용하여 컨테이너 구성을 정의하고, 구성 변경 사항을 적용할 수 있습니다. 하지만 컨테이너의 상태를 관리하지 않습니다.
YAML 파일을 사용하여 애플리케이션 및 리소스 구성을 정의하고, 클러스터의 상태를 선언적으로 관리합니다. 원하는 상태로 계속 유지하도록 컨테이너를 관리합니다.
다양한 환경에서의 이식성
개발 및 테스트 환경에서 주로 사용되며, 단일 호스트에서 실행됩니다.
여러 환경(로컬, 온프레미스, 클라우드)에서 실행되며, 배포와 관리를 통일된 방식으로 수행할 수 있습니다.
결론적으로, Docker Compose는 단일 호스트에서 컨테이너를 실행하고 개발하는 데 사용되는 도구이며, Kubernetes는 컨테이너화된 애플리케이션을 확장 가능한 클러스터에서 배포하고 관리하는 데 사용되는 강력한 오케스트레이션 도구입니다.
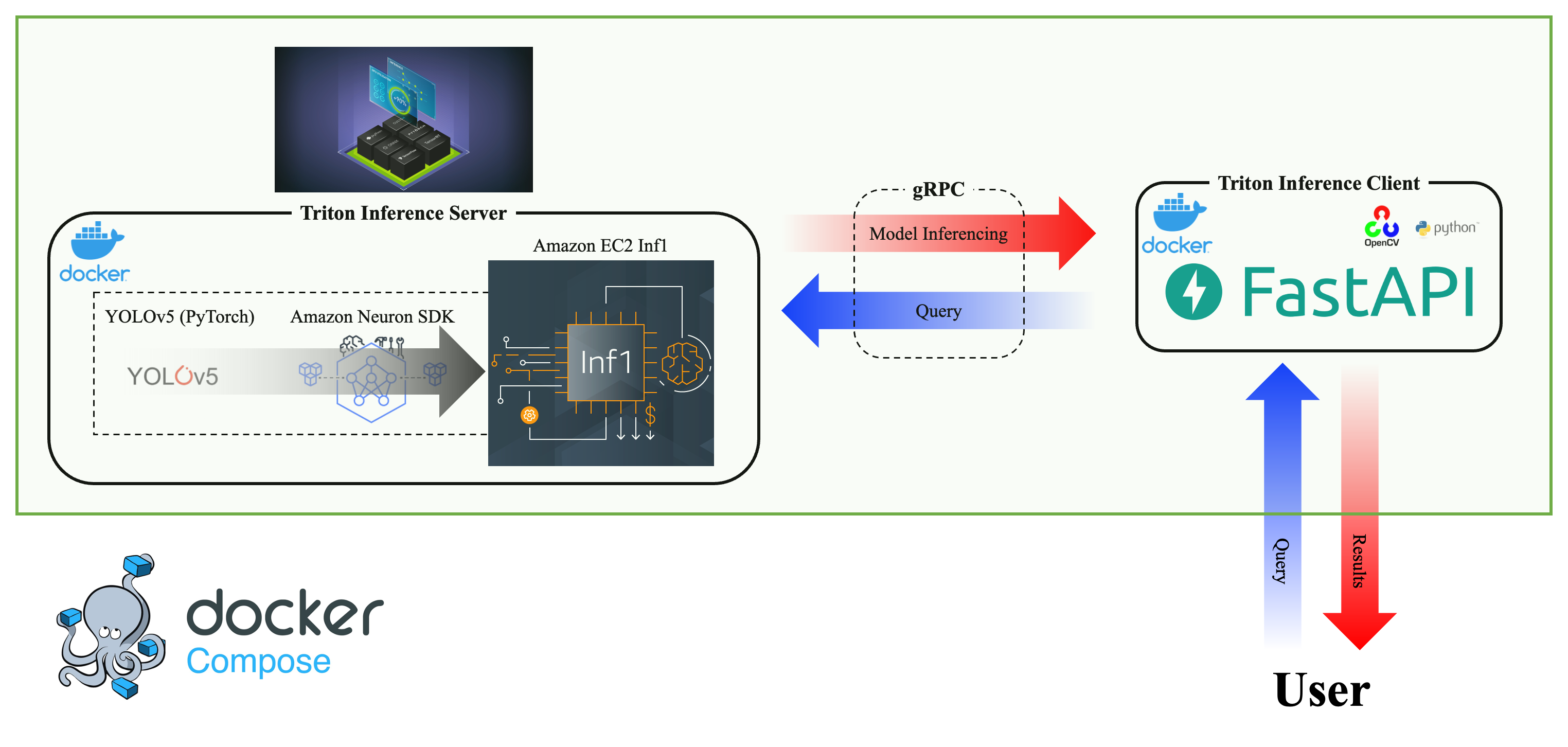
Amazon EC2 Inf1
목표는 이렇지만,,, 처음 AWS를 경험해보고 가능할지 모르겠다,,, (AWS 어린이는 울어요,,, ㅜ)
AWS Neuron SDK YOLOv5의 공식 repository 에서 제공하는 export.py이렇게 모델을 AWS Neuron SDK로 compile 했다.
1 $ python export.py --weights {MODEL_WEIGHTS}.pt --include onnx
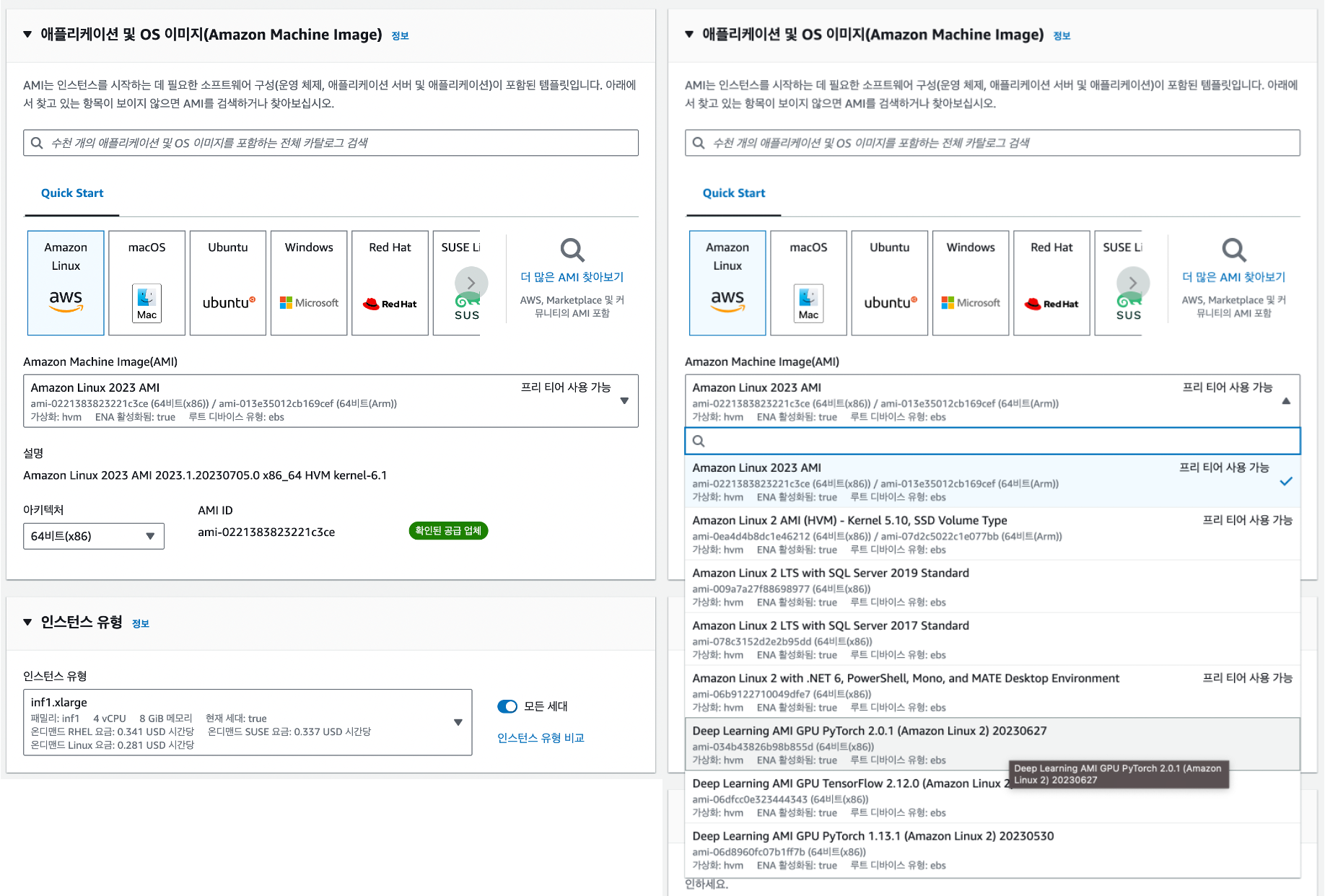
첫 시도! Amazon EC2 Inf1 인스턴스를 생성할 때 아래와 같이 OS를 선택할 수 있다.
AWS AMI와 AWS DLAMI 가 존재한다.
AWS AMI(Amazon Machine Image)와 AWS DLAMI(Deep Learning AMI)은 둘 다 AWS에서 제공하는 이미지로, EC2 인스턴스를 시작하는 데 사용됩니다. 하지만 각각의 이미지는 목적과 구성에서 차이가 있습니다.
AWS AMI (Amazon Machine Image)
AWS AMI는 일반적인 운영 체제 및 소프트웨어 구성을 포함하는 이미지입니다.
AWS에서는 다양한 AMI를 제공하며, 이는 다양한 운영 체제(예: Amazon Linux, Ubuntu, Windows 등)와 사전 설치된 소프트웨어(예: 웹 서버, 데이터베이스, 개발 환경 등)를 포함할 수 있습니다.
AWS AMI는 다양한 용도로 사용되며, 개발, 프로덕션, 데이터베이스, 애플리케이션 호스팅 등에 적합한 AMI를 선택할 수 있습니다. AMI는 EC2 인스턴스에서 실행되는 일반적인 운영 체제와 소프트웨어를 제공하는 데 사용됩니다.
AWS DLAMI (Deep Learning AMI)
AWS DLAMI는 딥 러닝 및 기계 학습 작업에 특화된 이미지입니다.
이 이미지에는 다양한 딥 러닝 프레임워크(예: TensorFlow, PyTorch, MXNet 등), 라이브러리, GPU 드라이버 및 최적화된 환경이 사전 설치되어 있습니다.
AWS DLAMI는 딥 러닝 모델 학습, 추론 및 개발에 필요한 도구와 라이브러리를 제공하여 딥 러닝 작업을 간편하게 시작할 수 있도록 합니다.
이러한 이미지는 GPU 가속을 활용하여 딥 러닝 모델의 성능을 극대화하고, 최신 딥 러닝 프레임워크 및 라이브러리를 지원합니다.
따라서, AWS AMI는 일반적인 운영 체제와 소프트웨어를 제공하는 이미지이며, AWS DLAMI는 딥 러닝 작업을 위해 딥 러닝 프레임워크와 라이브러리가 사전 설치된 특화된 이미지입니다. 어떤 이미지를 선택해야 하는지는 사용자의 요구 사항과 작업 유형에 따라 달라집니다.
AWS DLAMI의 Release Note는 여기 에서 확인할 수 있다.본격 삽질 시작)
SSH 인스턴스 생성을 마치면 개발을 진행하기 위해 아래와 같이 인스턴스에 ssh로 접속할 수 있다.
1 $ ssh -i ${YOUR_PEM_PATH} .pem ec2-user@${YOUR_AMAZON_EC2_INF1_IP_OR_DNS}
하지만 이렇게 항상 접속하면 힘드니 아래와 같이 설정하고 Visual Studio Code에서 사용할 수 있게 한다.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 $ chmod 400 ${YOUR_PEM_PATH} .pem$ vi ~/.ssh/config Host Inf1 HostName ${YOUR_AMAZON_EC2_INF1_IP_OR_DDNS} User ec2-user IdentityFile ${YOUR_PEM_PATH}.pem $ ssh Inf1 , #_ ~\_ ####_ Amazon Linux 2023 ~~ \_#####\ ~~ \###| ~~ \#/ ___ https://aws.amazon.com/linux/amazon-linux-2023 ~~ V~' '-> ~~~ / ~~._. _/ _/ _/ _/m/'
Setup 접속에 성공하고 여러가지 setup을 Install Neuron PyTorch 를 참고하여 아래와 같이 실행했다.
1 2 3 4 5 6 7 $ sudo tee /etc/yum.repos.d/neuron.repo > /dev/null <<EOF [neuron] name=Neuron YUM Repository baseurl=https://yum.repos.neuron.amazonaws.com enabled=1 metadata_expire=0 EOF
1 2 3 4 5 $ sudo rpm --import https://yum.repos.neuron.amazonaws.com/GPG-PUB-KEY-AMAZON-AWS-NEURON.PUB$ sudo yum update -y$ sudo yum install kernel-devel-$(uname -r) kernel-headers-$(uname -r) -y$ sudo yum install aws-neuron-dkms -y$ export PATH=/opt/aws/neuron/bin:$PATH
그리고 개발 및 AWS Neuron SDK로 컴파일한 모델을 테스트하기 위해 pip, torch-neuron을 설치했다.
1 2 3 4 5 $ sudo yum install pip -y$ pip --version pip 21.3.1 from /usr/lib/python3.9/site-packages/pip (python 3.9) $ pip config set global.extra-index-url https://pip.repos.neuron.amazonaws.com $ pip install torch-neuron neuron-cc[tensorflow] torchvision
Load? 드디어! 컴파일된 모델을 테스트하려고 로드하는 순간~
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 >>> import torch>>> model = torch.jit.load('model_neuron.pt' )Traceback (most recent call last): File "<stdin>" , line 1 , in <module> File "/home/ec2-user/.local/lib/python3.9/site-packages/torch/jit/_serialization.py" , line 162 , in load cpp_module = torch._C.import_ir_module(cu, str (f), map_location, _extra_files) RuntimeError: Unknown type name '__torch__.torch.classes.neuron.Model' : File "code/__torch__/torch_neuron/decorators.py" , line 6 training : bool _is_full_backward_hook : Optional [bool ] model : __torch__.torch.classes.neuron.Model ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~ <--- HERE def forward (self: __torch__.torch_neuron.decorators.NeuronModuleV2, argument_1: Tensor ) -> Tuple [Tensor, Tensor]:
슬픈 예감은 늘 틀린적이 없는 것 같다.
해당 오류는 TorchScript 모델을 Neuron 컴파일러로 변환하는 과정에서 발생한 문제로 보입니다. torch.jit.load() 함수를 사용하여 TorchScript 모델을 로드하려고 할 때 오류가 발생했습니다.torch.classes.neuron.Model이라는 Neuron 모델의 클래스 유형을 인식하지 못했다는 것을 나타냅니다.
Neuron 설치 확인: 사용 중인 환경에서 Neuron이 올바르게 설치되었는지 확인합니다. AWS EC2 Inf1 인스턴스에 Neuron 런타임이 설치되어 있는지 확인하고, 필요한 경우 Neuron 런타임을 설치하고 구성합니다.
모델 변환 및 실행 환경 확인: 모델이 Neuron과 호환되는지 확인하고, 모델을 올바른 환경에서 실행하려는지 확인합니다. Neuron이 지원되는 인스턴스에서 실행 중인지 확인하고, 모델을 Neuron을 사용하여 변환한 후 실행하는지 확인합니다.
AWS 및 Neuron 문서 참조: AWS와 Neuron 관련 문서를 참조하여 Neuron 모델 변환 및 실행에 대한 지침을 확인합니다. AWS 문서 및 Neuron 사용자 가이드에는 모델 변환과 호환성에 대한 자세한 정보가 포함되어 있을 것입니다.
위의 단계를 따라 진행하면 Neuron과 모델을 올바르게 구성하고 실행할 수 있습니다.
Triton Inference Server? 환경의 문제라면 Docker로 해결할 수 있지 않을까해서 위에서 개발한 것을 python backend로 전환하고 실행하기 위해 git, docker, docker-compose를 아래와 같이 설치했다.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 $ sudo yum install git -y$ git version git version 2.40.1 $ sudo yum install docker -y$ docker --version Docker version 20.10.23, build 7155243 $ sudo service docker start$ sudo curl -L "https://github.com/docker/compose/releases/latest/download/docker-compose-$(uname -s) -$(uname -m) " -o /usr/local/bin/docker-compose$ sudo chmod +x /usr/local/bin/docker-compose$ docker-compose --version Docker Compose version v2.20.0 $ sudo docker loginLogin Succeeded $ sudo docker login nvcr.ioLogin Succeeded
Triton Inference Server를 Amazon EC2 Inf1 인스턴스에서 사용하기 위해 nvcr.io 에 로그인한다.
설정을 마치고 local에서와 같이 Triton Inference Server로 실험해보기 위해 docker-compose를 이용했다.
1 $ sudo docker-compose up -d
또 슬픈 예감이 나올 때가 됐다!Amazon Elastic Block Store 의 용량 부족으로 아래의 과정으로 용량을 늘려줬다.Elastic Block Store - 볼륨에서 설정할 수 있다.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 $ df -hTFilesystem Type Size Used Avail Use% Mounted on devtmpfs devtmpfs 4.0M 0 4.0M 0% /dev tmpfs tmpfs 3.8G 0 3.8G 0% /dev/shm tmpfs tmpfs 1.6G 448K 1.6G 1% /run /dev/nvme0n1p1 xfs 8.0G 3.7G 4.3G 47% / tmpfs tmpfs 3.8G 0 3.8G 0% /tmp tmpfs tmpfs 773M 0 773M 0% /run/user/1000 $ lsblk NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINTS nvme0n1 259:0 0 30G 0 disk ├─nvme0n1p1 259:1 0 8G 0 part / ├─nvme0n1p127 259:2 0 1M 0 part └─nvme0n1p128 259:3 0 10M 0 part $ sudo growpart /dev/nvme0n1 1CHANGED: partition=1 start=24576 old: size=16752607 end=16777183 new: size=62889951 end=62914527 $ lsblk NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINTS nvme0n1 259:0 0 30G 0 disk ├─nvme0n1p1 259:1 0 30G 0 part / ├─nvme0n1p127 259:2 0 1M 0 part └─nvme0n1p128 259:3 0 10M 0 part $ sudo xfs_growfs -d /meta-data=/dev/nvme0n1p1 isize=512 agcount=2, agsize=1047040 blks = sectsz=4096 attr=2, projid32bit=1 = crc=1 finobt=1, sparse=1, rmapbt=0 = reflink=1 bigtime=1 inobtcount=1 data = bsize=4096 blocks=2094075, imaxpct=25 = sunit=128 swidth=128 blks naming =version 2 bsize=16384 ascii-ci=0, ftype=1 log =internal log bsize=4096 blocks=16384, version=2 = sectsz=4096 sunit=4 blks, lazy-count=1 realtime =none extsz=4096 blocks=0, rtextents=0 data blocks changed from 2094075 to 7861243 $ df -hTFilesystem Type Size Used Avail Use% Mounted on devtmpfs devtmpfs 4.0M 0 4.0M 0% /dev tmpfs tmpfs 3.8G 0 3.8G 0% /dev/shm tmpfs tmpfs 1.6G 448K 1.6G 1% /run /dev/nvme0n1p1 xfs 30G 3.9G 27G 13% / tmpfs tmpfs 3.8G 0 3.8G 0% /tmp tmpfs tmpfs 773M 0 773M 0% /run/user/1000
중꺾마 Triton Inference Server에서 Model Configuration하는 방법은 해당 링크 에 상세히 설명되어 있지만 Amazon EC2 Inf1 인스턴스 설정 방법은 나와있지 않아서 우선 instance_group는 KIND_CPU로 설정하고 진행했다. $\rightarrow$ 아래 글 참고
Neuron 컴파일러 올바르게 설치 후 모델 테스트 (torch.jit.load()) $\rightarrow$ AWS DLAMI
Amazon EC2 Inf1에서 Triton Inference Server의 config.pbtxt 및 python backend 설정
두 번째 시도,,, DLAMI YOLOv5는 PyTorch의 버전을 1.7.0 이상으로 권장하기 때문에 아래와 같이 Amazon Machine Image를 Deep Learning AMI Neuron PyTorch 1.13 (Ubuntu 20.04)로 설정했다.
해당 AMI를 사용하면 스토리지가 자동으로 35GB로 설정된다.ubuntu로 지정해야한다.
1 2 3 4 5 6 7 8 9 10 $ neuron-ls instance-type: inf1.xlarge instance-id: i-098116f54903c5fc6 +--------+--------+--------+---------+ | NEURON | NEURON | NEURON | PCI | | DEVICE | CORES | MEMORY | BDF | +--------+--------+--------+---------+ | 0 | 4 | 8 GB | 00:1f.0 | +--------+--------+--------+---------+ $ source /opt/aws_neuron_venv_pytorch_inf1/bin/activate
우선 첫 시도에서 실행되지 않았던 neuron-ls 명령어가 잘 작동한다!source /opt/aws_neuron_venv_pytorch_inf1/bin/activate를 실행해서 Python 가상 환경을 접속했다.
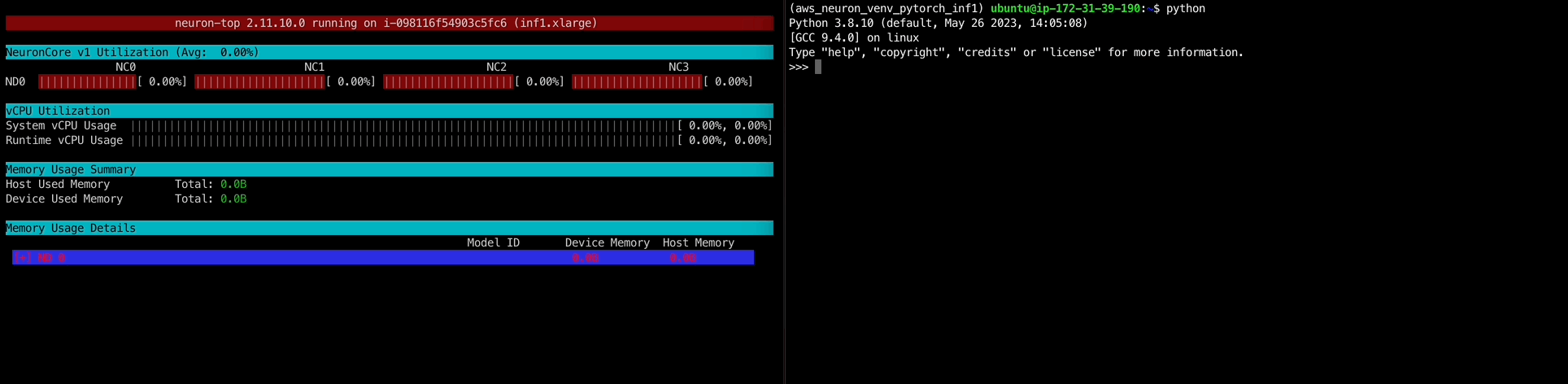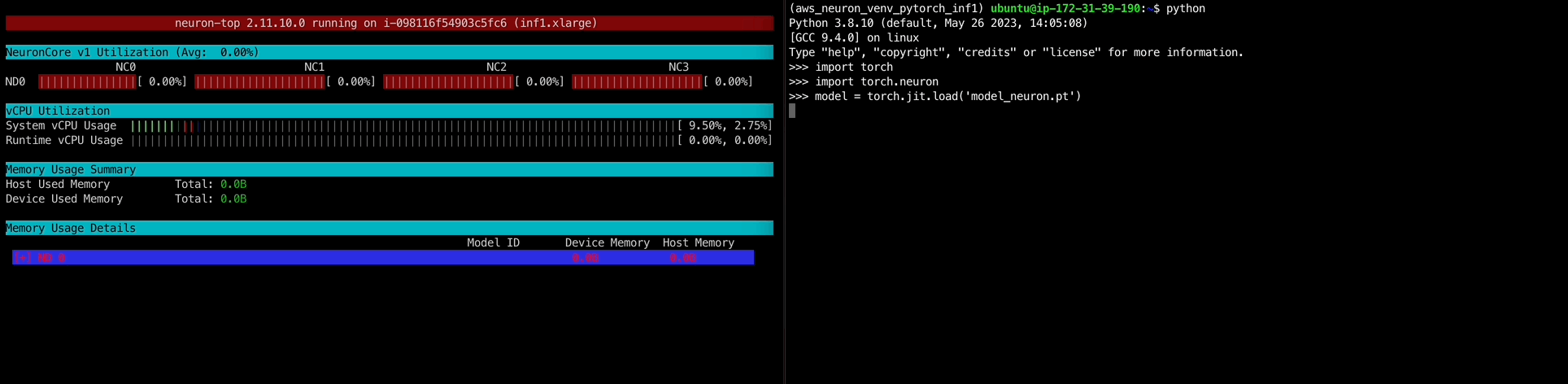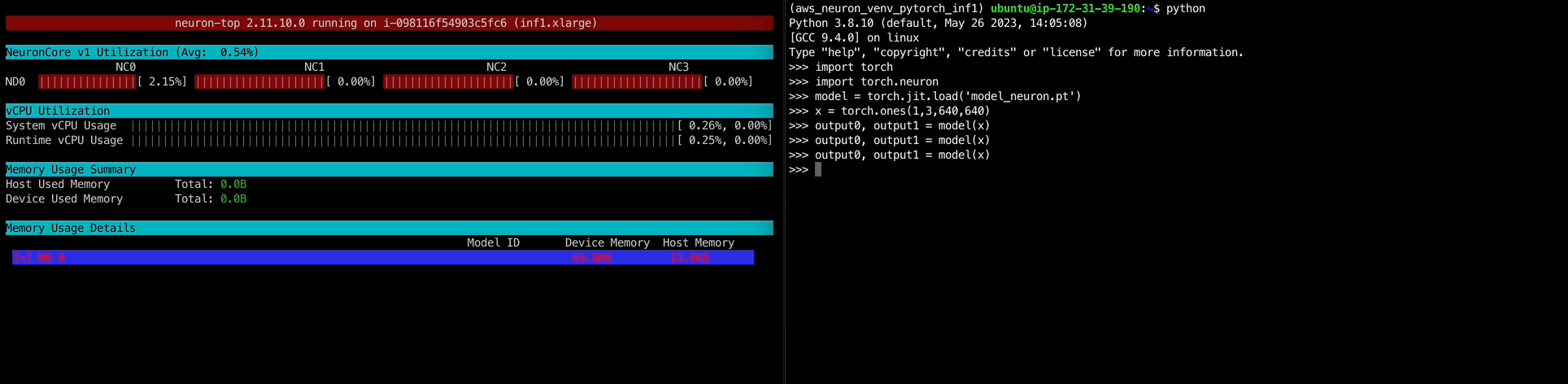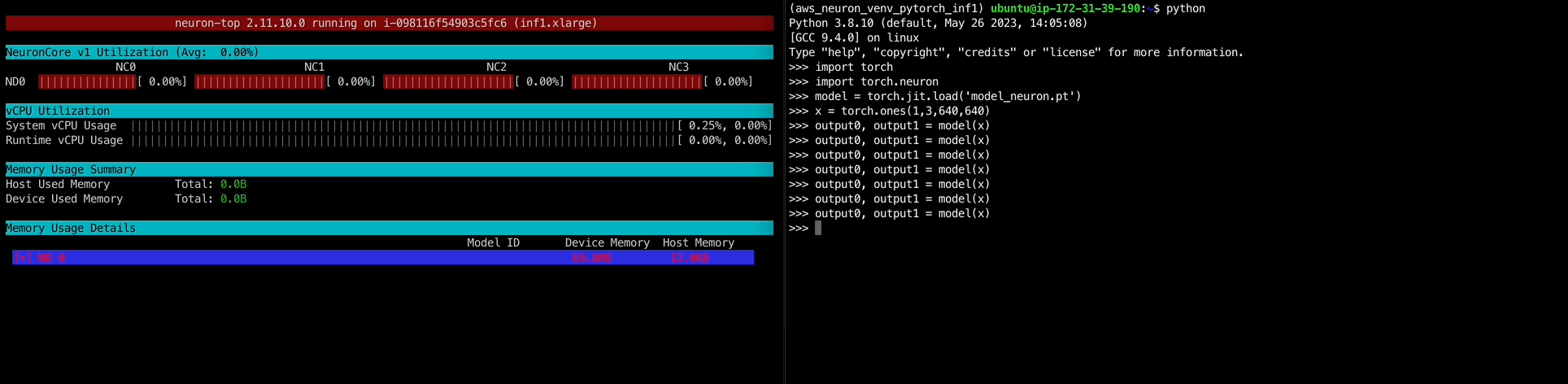
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 >>> import torch>>> model = torch.jit.load('model_neuron.pt' )Traceback (most recent call last): File "<stdin>" , line 1 , in <module> File "/opt/aws_neuron_venv_pytorch_inf1/lib/python3.8/site-packages/torch/jit/_serialization.py" , line 162 , in load cpp_module = torch._C.import_ir_module(cu, str (f), map_location, _extra_files) RuntimeError: Unknown type name '__torch__.torch.classes.neuron.Model' : File "code/__torch__/torch_neuron/decorators.py" , line 6 training : bool _is_full_backward_hook : Optional [bool ] model : __torch__.torch.classes.neuron.Model ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~ <--- HERE def forward (self: __torch__.torch_neuron.decorators.NeuronModuleV2, argument_1: Tensor ) -> Tuple [Tensor, Tensor]:>>> import torch.neuron>>> model = torch.jit.load('model_neuron.pt' )>>> modelRecursiveScriptModule( original_name=AwsNeuronGraphModule (_NeuronGraph0): RecursiveScriptModule(original_name=NeuronModuleV2) ) >>> x = torch.ones(1 ,3 ,640 ,640 )>>> output0, output1 = model(x)
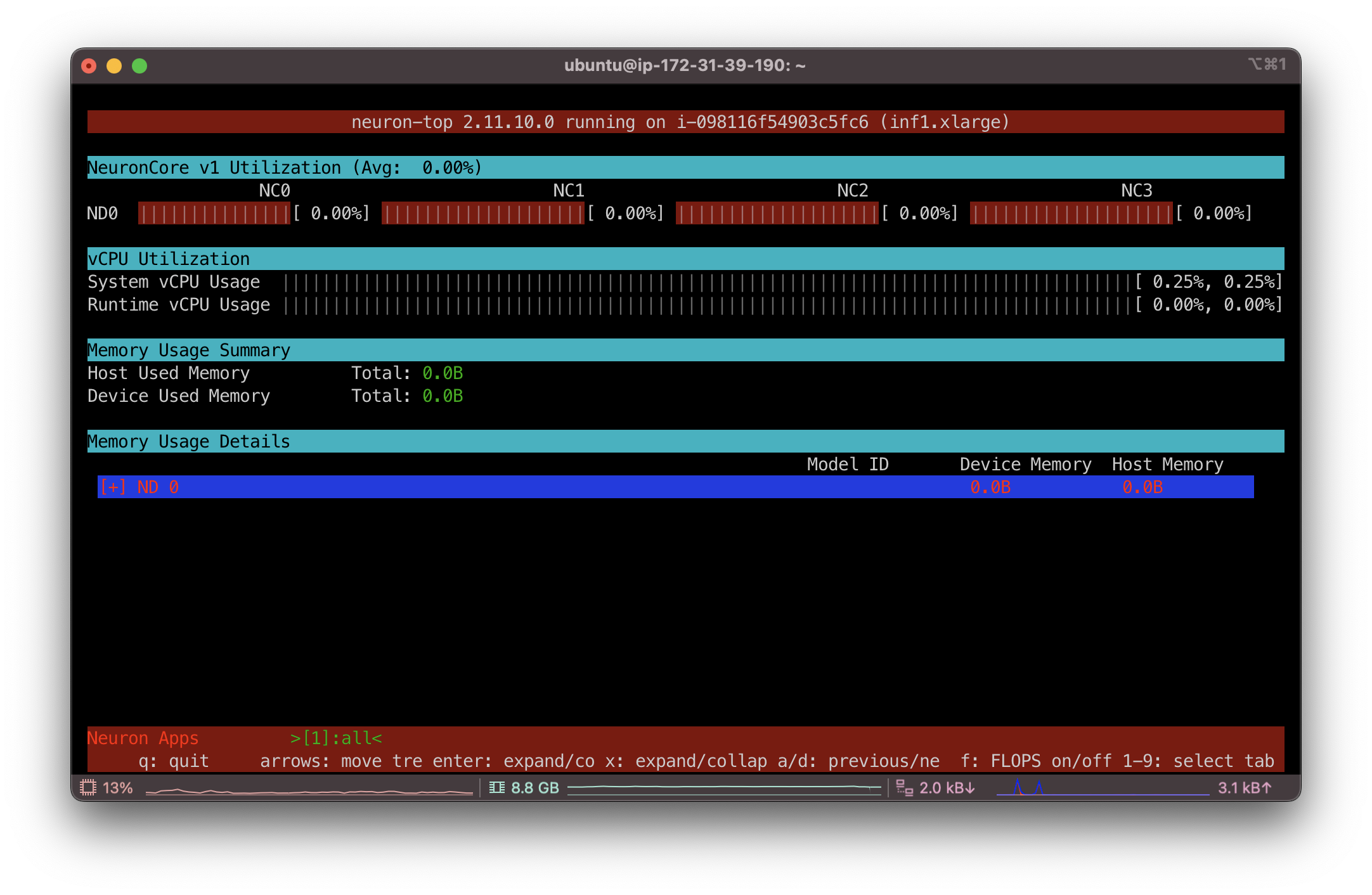
오,, 혹시나하고 해본 import torch.neuron이 문제였다.neuron-top 명령어로 htop처럼 모니터링이 가능하다.
모델 추론을 진행하면 아래와 같이 NeuronCore에 부하가 걸리는 것을 확인할 수 있다.
Python Backend 해당 글 을 참고하여 gen_triton_model.py
model_type: pytorch, tensorflowtriton_input: <input_name>,<triton_datatype>,<shape>triton_output: <output_name>,<triton_datatype>,<shape>compiled_model: Fullpath to the compiled modelneuron_core_range: The range of neuron core indices where the model needs to be loaded.triton_model_dir: Path to the triton model directory where script will generate config.pbtxt and model.py
위와 같은 입력을 구성하여 아래와 같이 실행하면 된다.
gen.sh 1 2 3 4 5 6 7 python3 server/model-repository/gen_triton_model.py \ --model_type pytorch \ --triton_input images__0,FP32,1x3x640x640 \ --triton_output output__0,FP32,1x25200x38 output__1,FP32,1x32x160x160 \ --compiled_model /model-repository/BoonMoSa/1/model_neuron.pt \ --neuron_core_range 0:0 \ --triton_model_dir server/model-repository/BoonMoSa
Triton Inference Server! 자… 이제 모든 준비는 끝났다.git, docker도 설치가 되어있다. (저번에 제대로 삽질했네,,,)
설치를 시작하고 EBS의 볼륨을 증가시켜야할 슬픈 예감이 든다.
10GB를 더 늘려서 45GB로 마운트 했다…공식 문서 )
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 $ lsblk NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT loop0 7:0 0 33.3M 1 loop /snap/amazon-ssm-agent/3552 loop1 7:1 0 24.8M 1 loop /snap/amazon-ssm-agent/6563 loop2 7:2 0 55.4M 1 loop /snap/core18/2066 loop3 7:3 0 55.7M 1 loop /snap/core18/2785 loop4 7:4 0 63.5M 1 loop /snap/core20/1950 loop5 7:5 0 91.9M 1 loop /snap/lxd/24061 loop6 7:6 0 67.6M 1 loop /snap/lxd/20326 loop7 7:7 0 53.3M 1 loop /snap/snapd/19457 loop8 7:8 0 63.5M 1 loop /snap/core20/1974 nvme0n1 259:0 0 45G 0 disk └─nvme0n1p1 259:1 0 35G 0 part / $ sudo growpart /dev/nvme0n1 1CHANGED: partition=1 start=2048 old: size=73398239 end=73400287 new: size=94369759 end=94371807 $ lsblk NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT loop0 7:0 0 33.3M 1 loop /snap/amazon-ssm-agent/3552 loop1 7:1 0 24.8M 1 loop /snap/amazon-ssm-agent/6563 loop2 7:2 0 55.4M 1 loop /snap/core18/2066 loop3 7:3 0 55.7M 1 loop /snap/core18/2785 loop4 7:4 0 63.5M 1 loop /snap/core20/1950 loop5 7:5 0 91.9M 1 loop /snap/lxd/24061 loop6 7:6 0 67.6M 1 loop /snap/lxd/20326 loop7 7:7 0 53.3M 1 loop /snap/snapd/19457 loop8 7:8 0 63.5M 1 loop /snap/core20/1974 nvme0n1 259:0 0 45G 0 disk └─nvme0n1p1 259:1 0 45G 0 part / $ sudo resize2fs /dev/nvme0n1p1resize2fs 1.45.5 (07-Jan-2020) Filesystem at /dev/nvme0n1p1 is mounted on /; on-line resizing required old_desc_blocks = 5, new_desc_blocks = 6 The filesystem on /dev/nvme0n1p1 is now 11796219 (4k) blocks long. $ df -hTFilesystem Type Size Used Avail Use% Mounted on /dev/root ext4 44G 21G 24G 47% / devtmpfs devtmpfs 3.8G 0 3.8G 0% /dev tmpfs tmpfs 3.8G 0 3.8G 0% /dev/shm tmpfs tmpfs 765M 892K 764M 1% /run tmpfs tmpfs 5.0M 0 5.0M 0% /run/lock tmpfs tmpfs 3.8G 0 3.8G 0% /sys/fs/cgroup /dev/loop0 squashfs 34M 34M 0 100% /snap/amazon-ssm-agent/3552 /dev/loop1 squashfs 25M 25M 0 100% /snap/amazon-ssm-agent/6563 /dev/loop2 squashfs 56M 56M 0 100% /snap/core18/2066 /dev/loop4 squashfs 64M 64M 0 100% /snap/core20/1950 /dev/loop5 squashfs 92M 92M 0 100% /snap/lxd/24061 /dev/loop3 squashfs 56M 56M 0 100% /snap/core18/2785 /dev/loop6 squashfs 68M 68M 0 100% /snap/lxd/20326 /dev/loop7 squashfs 54M 54M 0 100% /snap/snapd/19457 /dev/loop8 squashfs 64M 64M 0 100% /snap/core20/1974 tmpfs tmpfs 765M 0 765M 0% /run/user/1000
진짜 거의 끝이 보인다!!
1 2 3 4 5 $ docker compose up -d [+] Running 3/3 ✔ Network BoonMoSa-network Created ✔ Container BoonMoSa_FastAPI Started ✔ Container BoonMoSa_TritonInferenceServer Started
하지만 계속 Triton Inference Server가 종료되는 현상이 발생해서 아래와 같이 초기 세팅 및 몇 가지를 수정했다.
1 2 3 $ git clone https://github.com/triton-inference-server/python_backend $ chmod 777 /home/ubuntu/python_backend/inferentia/scripts/setup-pre-container.sh$ sudo /home/ubuntu/python_backend/inferentia/scripts/setup-pre-container.sh
docker-compose.yaml 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 version: "3" services: tritoninferenceserver: build: context: . dockerfile: ./server/Dockerfile container_name: BoonMoSa_TritonInferenceServer devices: - /dev/neuron0 volumes: - /home/ubuntu/python_backend:/home/ubuntu/python_backend - /lib/udev:/mylib/udev - /home/ubuntu/Amazon-EC2-Inf1/server/model-repository:/model-repository shm_size: 8g ports: - 8000 :8000 - 8001 :8001 - 8002 :8002 command: tritonserver --model-repository=/model-repository fastapi: build: context: . dockerfile: ./client/Dockerfile container_name: BoonMoSa_FastAPI volumes: - /home/ubuntu/Amazon-EC2-Inf1/client/inputs:/app/inputs - /home/ubuntu/Amazon-EC2-Inf1/client/outputs:/app/outputs ports: - 80 :80 networks: default: name: BoonMoSa-network
server/Dockerfile 1 2 3 4 FROM nvcr.io/nvidia/tritonserver:23.06 -py3RUN pip config set global.extra-index-url https://pip.repos.neuron.amazonaws.com RUN pip install torch-neuron neuron-cc[tensorflow] torchvision
이 외에도 client.py의 입출력을 새로 생성된 config.pbtxt에 맞춰 이렇게 수정했다.
1 2 3 4 5 6 7 8 9 10 11 12 13 $ docker ps CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES 470f1ad1b415 amazon-ec2-inf1-tritoninferenceserver "/opt/nvidia/nvidia_…" 2 minutes ago Up 2 minutes 0.0.0.0:8000-8002->8000-8002/tcp, :::8000-8002->8000-8002/tcp BoonMoSa_TritonInferenceServer b27ce6d6f4d7 amazon-ec2-inf1-fastapi "gunicorn -k uvicorn…" 2 minutes ago Up 2 minutes 0.0.0.0:80->80/tcp, :::80->80/tcp BoonMoSa_FastAPI $ neuron-ls -w instance-type: inf1.xlarge instance-id: i-098116f54903c5fc6 +--------+--------+--------+---------+--------+----------------------------------------------------------------------------------+---------+ | NEURON | NEURON | NEURON | PCI | PID | COMMAND | RUNTIME | | DEVICE | CORES | MEMORY | BDF | | | VERSION | +--------+--------+--------+---------+--------+----------------------------------------------------------------------------------+---------+ | 0 | 4 | 8 GB | 00:1f.0 | 100884 | /opt/tritonserver/backends/python/triton_python_backend_stub /model-repositor... | 2.12.23 | +--------+--------+--------+---------+--------+----------------------------------------------------------------------------------+---------+
M1 Pro 환경에서 local로 추론할 때 (물론 CPU를 사용하긴 했지만) 약 1.93초, Amazon EC2 Inf1에서는 0.28~0.31초 가량 소요됐다.Amazon Elastic Kubernetes Service 를 사용해보겠다!!
해당 글에 사용된 코드들은 Team-BoonMoSa/Amazon-EC2-Inf1 에서 확인할 수 있다.