
Apache Airflow (1)
Introduction
Apache Airflow
- Definition
- 오픈 소스로 개발된 데이터 파이프라인 관리 도구
- Workflow 자동화와 데이터 처리를 위한 플랫폼
- Features
- 유연한 파이썬 프레임워크를 통한 쉬운 데이터 파이프라인 구축
- 다양한 빌딩 블록을 통한 최신 기술 연결
- 복잡한 데이터 처리 작업 scheduling 및 monitoring
- Data engineering, ETL (Extract, Transform, Load), data migration, data analysis 등 다양한 작업에서 활용
- Components
- Webserver (Web UI, User Interface)
- Gunicorn 기반의 Flask 서버
- Web 기반 UI를 통해 workflow를 시각적 monitoring 및 관리
- 작업의 실행 상태, log, scheduling 등 확인 가능
- Scheduler
- Multi thread로 구성된 python process
- Workflow를 실행하기 위해 정의된 시간대와 주기에 따라 작업들을 scheduling
- 정의된 순서에 따라 실행되는 schedule 생성
- Database
- 모든 DAG 및 task의 metadata 저장
- 다양한 database 지원 (SQLite, MySQL, PostgreSQL)
- Executor
- Workflow의 task 실행 방식 결정
- 특성과 환경에 따라 선택하여 사용 (
LocalExecutor,SequentialExecutor,CeleryExecutor)
- Worker
- Workflow의 task를 실제로 실행하는 computing source
- 각 worker는 독립적으로 task 수행
- 필요에 따라 workload 분산 가능
- Triggerer
- Deferrable operator를 지원하는 별도의 process
- 사용 시 별도 실행 (선택적 사용)
- Webserver (Web UI, User Interface)
- Etc.
- DAG (Directed Acyclic Graph)
- Workflow를 정의하는 code 파일
- 작업 및 의존성 정의
- Task
- Operators를 통해 생성된 작업 단위 (DAG에서 하나의 노드)
- 독립적으로 실행되는 하나의 단위 작업
- Operator
- 개별 작업을 나타내는 class (
BashOperator,PythonOperator) - 특정 작업 수행 시 사용
- 개별 작업을 나타내는 class (
- Sensor
- 외부 조건 혹은 이벤트 발생까지 대기 후 특정 조건 만족 시 task 실행
- 외부 시스템의 데이터 유무 확인 및 파일 생성 여부 확인 등 작업 수행
- DAG (Directed Acyclic Graph)
Data Pipeline
Data pipeline을 통해 원하는 결과를 얻기 위해서는 API 호출, 데이터 전처리 등 다양한 task가 수행된다.
또한 각 task들은 의존성이 존재하여 정해진 순서대로 진행되어야 한다.
이를 간단하게 이해하기 위해 task 간 의존성을 아래 예시와 같이 directed graph (방향성 그래프)로 나타낸다.
API 호출 $\rightarrow$ 데이터 전처리 $\rightarrow$ 모델 예측
위와 같은 형태를 Directed Acycllic Graph, DAG (방향성 비순환 그래프)라 칭한다.
Task의 의존성을 나타내는 $\rightarrow$의 directed edge (끝점)의 반복 혹은 순환을 허용하지 않는다. (순환 그래프는 deadlock 발생)
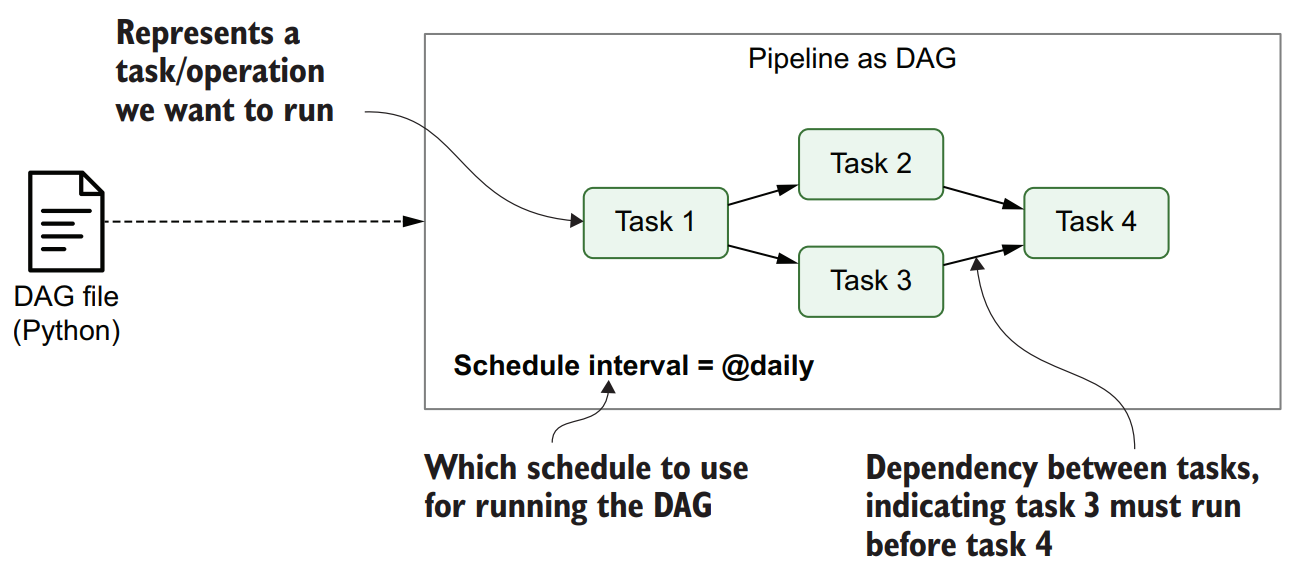
절차적 script pipeline에 비해 graph pipeline은 위와 같은 경우 task를 병렬로 실행할 수 있기 때문에 더 효율적이다.
또한 전체 작업을 하나의 monolithic script 또는 process로 구성하는 것이 아니라 task로 명확히 분리하기 때문에 중간의 task가 실패할 때 전체 script를 재실행하는 것이 아닌 실패한 task만 재실행한다.
ETL vs. ELT
| ETL (Extract, Transform, Load) | ELT (Extract, Load, Transform) | |
|---|---|---|
| 정의 | 데이터 추출 (Extract) $\rightarrow$ 변환 (Transform) $\rightarrow$ 데이터 적재 (Load) | 데이터 추출 (Extract) $\rightarrow$ 데이터 적재 (Load) $\rightarrow$ 변환 (Transform) |
| 변환 처리 위치 | 추출 후 변환 작업을 수행 | 적재 후 변환 작업을 수행 |
| 데이터 저장 위치 | 적재 전에 변환된 데이터를 중간 저장소에 저장 | 적재 후에 원시 데이터를 데이터 웨어하우스에 저장 |
| 데이터 용량 | 변환된 데이터 용량이 클 수 있음 | 원시 데이터를 저장하기 때문에 용량이 큼 |
| 변환 시점 | 추출 후 변환 작업을 통해 필요한 데이터만 적재 | 적재 후 변환 작업을 통해 필요한 데이터를 추출 |
| 장점 | 👍 적재 시간이 짧음 👍 중간 저장소를 통한 재시도 및 오류 처리 가능 👍 적재 시 데이터 변경 없음 (데이터 품질 유지) |
👍 변환 시간이 짧음 👍 빠른 변환 작업 가능 👍 변환된 데이터를 직접 활용 가능 |
| 단점 | 👎 중간 저장소 관리 필요 👎 적재 시간이 상대적으로 길 수 있음 |
👎 적재 시간이 상대적으로 길 수 있음 👎 중간 저장소가 없으므로 오류 처리에 제약이 있음 |
Data Lake vs. Data Warehouse
| Data Lake | Data Warehouse | |
|---|---|---|
| 정의 | 비구조적인 원시 데이터 저장소 | 구조화된 데이터 저장소 |
| 데이터 유형 | 원시 데이터 (비정형, 반정형, 정형) | 정형 데이터 (구조화된 테이블 형태) |
| 데이터 저장 형식 | 파일 시스템 (HDFS, AWS S3 등) | 관계형 데이터베이스 (RDBMS) |
| 데이터 처리 접근성 | 스키마나 스키마 변환 없이 접근 가능 | 사전 정의된 스키마에 따라 접근 |
| 데이터 처리 기술 | 빅데이터 기술 (Hadoop, Spark 등) | 데이터베이스 기술 (SQL, OLAP 등) |
| 데이터 통합 | 데이터 통합 없이 다양한 형태의 데이터 저장 | ETL 프로세스를 통한 데이터 통합 |
| 데이터 분석 | 데이터를 필요할 때까지 보관하고 분석을 나중에 수행 | 데이터를 사전에 구조화하여 분석을 수행 |
| 데이터 스키마 | 스키마 없이 저장하여 유연성을 갖춤 | 사전에 정의된 스키마를 따름 |
| 데이터 품질 및 보안 | 데이터 품질 검증과 보안 강화에 어려움 | 정형화된 데이터로 데이터 품질 및 보안 강화 |
| 비용 | 저장 용량에 따른 비용 증가 | 구조화된 데이터의 저장 비용 |
| 사용 사례 | 비정형 데이터 분석, 빅데이터 처리, 머신러닝 모델 개발 등 | 통계 분석, 비즈니스 인텔리전스, 리포팅 등 |
Apache Airflow
Apache Airflow에서는 python script로 DAG의 구조를 설명하고 구성한다. (높은 유연성)
Python으로 정의한 DAG로 pipeline의 구조를 정의하면 Apache Airflow가 pipeline을 언제 실행할 것인지 각각의 DAG의 실행 주기를 Cron과 같은 표현식으로 정의할 수 있다.
Scheduler는 아래와 같이 작동한다.
- 정의된 DAG 파일 분석 및 각 DAG task, 의존성, 예약 주기 확인
- DAG의 예약 주기 경과 확인 및 예약 주기가 현재 시간 이전인 경우 실행 예약
- 예약된 각 task의 의존성 확인 후 의존성 task가 완료되지 않을 시 execution queue에 추가
- 대기 후 1.부터 다시 실행
Monitoring은 아래와 같이 webserver를 통해 진행할 수 있다.
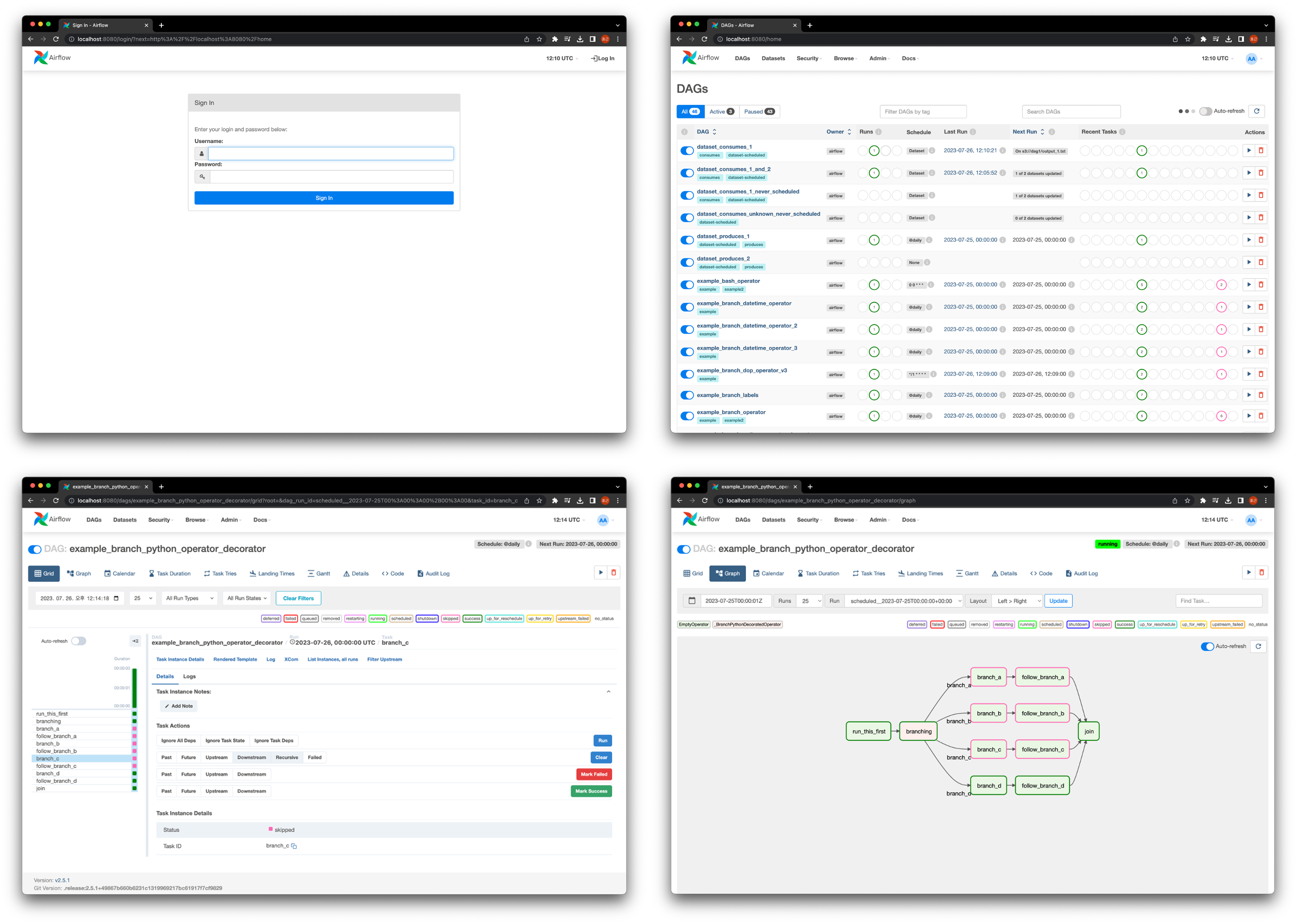
Task 실패 시 재시도를 설정하여 task를 복구할 수 있다.
재시도 또한 실패하면 task 실패를 기록하고 log를 확인하여 debugging 할 수 있다.
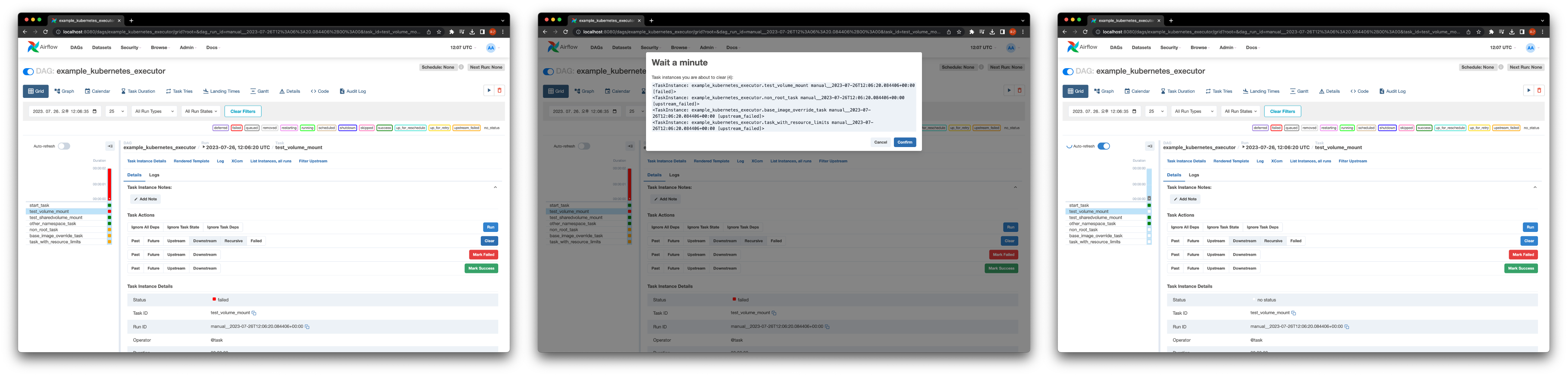
Schedule 기능 중 DAG에 정의된 특정 시점 trigger 가능한 것과 최종 시점과 예상되는 다음 schedule 주기를 상세히 알려주는 것이 존재한다.
이 기능을 통해 아래와 같은 구성이 가능하다.
- Incremental Loading
- 매번 전체 데이터 세트를 처리하지 않고 time slot에 대해 점진적으로 처리
- 효율적 data pipeline 구축 가능
- Backfill
- 새로 생성한 DAG를 과거 시점 및 기간에 대해 실행 가능
- 과거 특정 기간에 대해 DAG를 실행하고 새로운 데이터 세트 생성
- 과거 실행 결과 삭제 후 task code를 변경해 전체 데이터 세트 재구성
이러한 특성을 가진 Apache Airflow는 아래와 같은 장단점이 존재한다.
- Pros
- Python script를 통해 복잡한 custom pipeline 개발
- 쉬운 확장 (다양한 Add-on)
- 효율적 pipeline 구축 (incremental 처리로 전체 재실행 X)
- Backfill로 손쉬운 재처리
- Open source
- Webserver로 monitoring 및 debugging 가능
- Cons
- 실시간 데이터 처리 workflow 및 pipeline에 부적합 (반복 혹은 batch-oriented task에 초점)
- 추가 및 삭제 task가 빈번한 dynamic pipeline에 부적합
- Python의 숙련 필요
- Pipeline의 규모가 커질 시 엄격한 관리 필요
Anatomy of an Airflow DAG
DAGinstance 생성을 통한 DAG 정의
1 | from airflow import DAG |
with DAG를 통한 DAG 정의
1 | from airflow import DAG |
airflow.decorator를 통한 DAG 정의 (TaskFlow API)
차후에 각 task에 대해 @task decorator를 사용하여 DAG 개발 환경을 단순화 할 수 있다. (지금은 일단 받아들이기…)
1 | from airflow.decorators import dag |
3가지 정의 방식 모두 같은 결과를 출력함을 확인할 수 있다.DAG 혹은 @dag의 파라미터는 아래와 같다.
| Name | Type | Mean |
|---|---|---|
dag_id |
str |
DAG의 고유한 식별자 |
default_args |
dict |
DAG의 기본 실행 인수들을 담고 있는 딕셔너리 |
description |
str |
DAG에 대한 설명 |
schedule_interval |
Cron or datetime.timedelta |
DAG의 실행 주기 설정 |
start_date |
datetime |
DAG의 시작 일시 |
catchup |
bool |
True로 설정하면 시작일부터 현재까지의 Task들을 실행 (과거 작업을 catch-up) |
tags |
list[str] |
DAG에 대한 태그들 |
max_active_runs |
int |
동시에 실행할 수 있는 최대 활성 DAG 인스턴스 수 |
각 task의 dependency는 아래와 같이 설정할 수 있다.
1 | task1.set_downstream(task2) # 가독성 안좋은데 |
최하단과 같이 정의할 경우 아래와 같이 Graph가 구성됨을 확인할 수 있다.
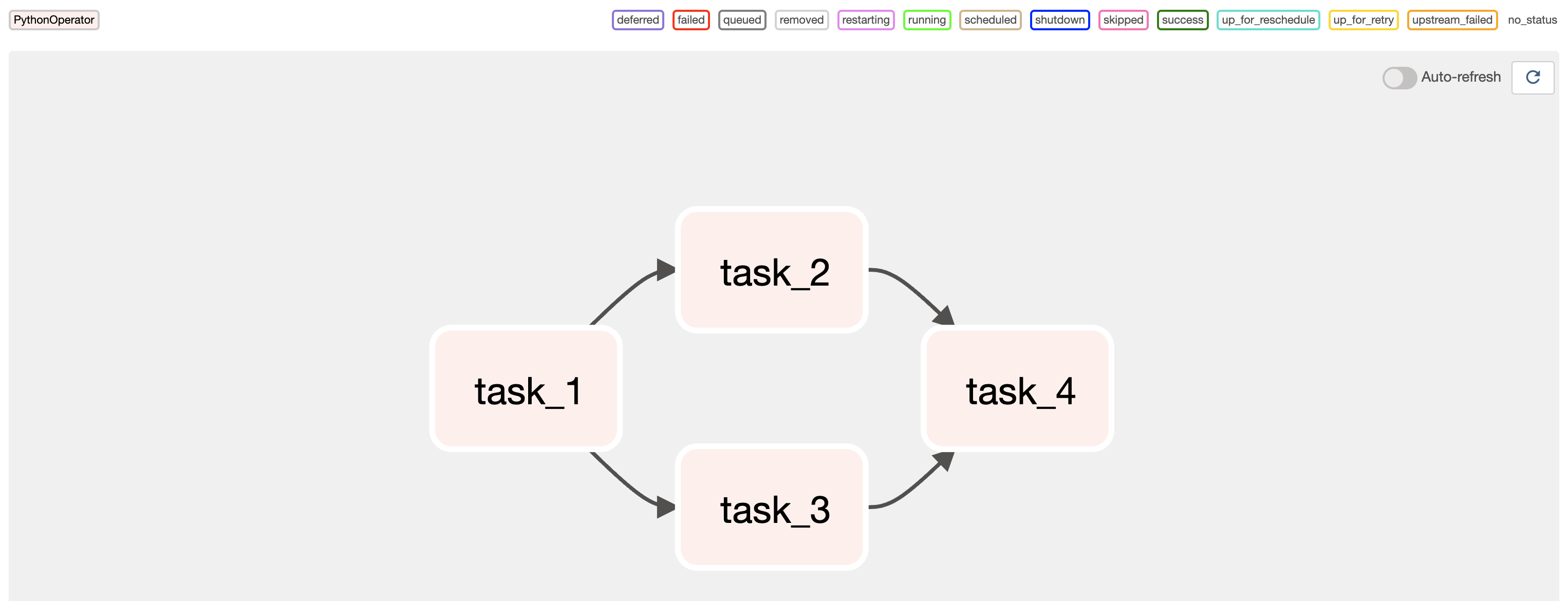
Scheduling in Airflow
Preset은 실행 주기를 정의하는 사전 정의된 일련의 schedule 간격이다.
이러한 preset은 DAG를 scheduling 시 주기적으로 실행되는 일반적인 시나리오를 간단하게 설정한다.
| Preset | Mean | Cron |
|---|---|---|
@once |
한 번만 실행하고 끝남 | - |
@hourly |
매 시간 정각마다 실행 (0분) | 0 * * * * |
@daily |
매일 자정마다 실행 (00:00) | 0 0 * * * |
@weekly |
매주 일요일 자정마다 실행 (00:00) | 0 0 * * 0 |
@monthly |
매월 1일 자정마다 실행 (00:00) | 0 0 1 * * |
@yearly |
매년 1월 1일 자정마다 실행 (00:00) | 0 0 1 1 * |
@annually |
매년 1월 1일 자정마다 실행 (00:00) | 0 0 1 1 * |
이러한 preset들은 DAG 객체에서 schedule_interval 파라미터로 사용할 수 있으며, 해당 주기에 따라 DAG가 주기적으로 실행된다.
예를 들어, schedule_interval="@daily"로 설정하면 해당 DAG는 매일 자정마다 실행된다.
Preset 외에도 직접 Cron 표현식을 입력하여 원하는 실행 주기를 정확하게 지정할 수 있다.
1 | * * * * * command_to_be_executed |
이런 것을 참고하면 조금 더 쉽게 개발을 진행할 수 있다.
마지막으로 datetime.timedelta()로 schedule의 간격을 설정할 수 있다.
예를 들어, 아래와 같이 하루에 한번 실행되도록 실행 주기를 정의할 수 있다.
1 | ... |
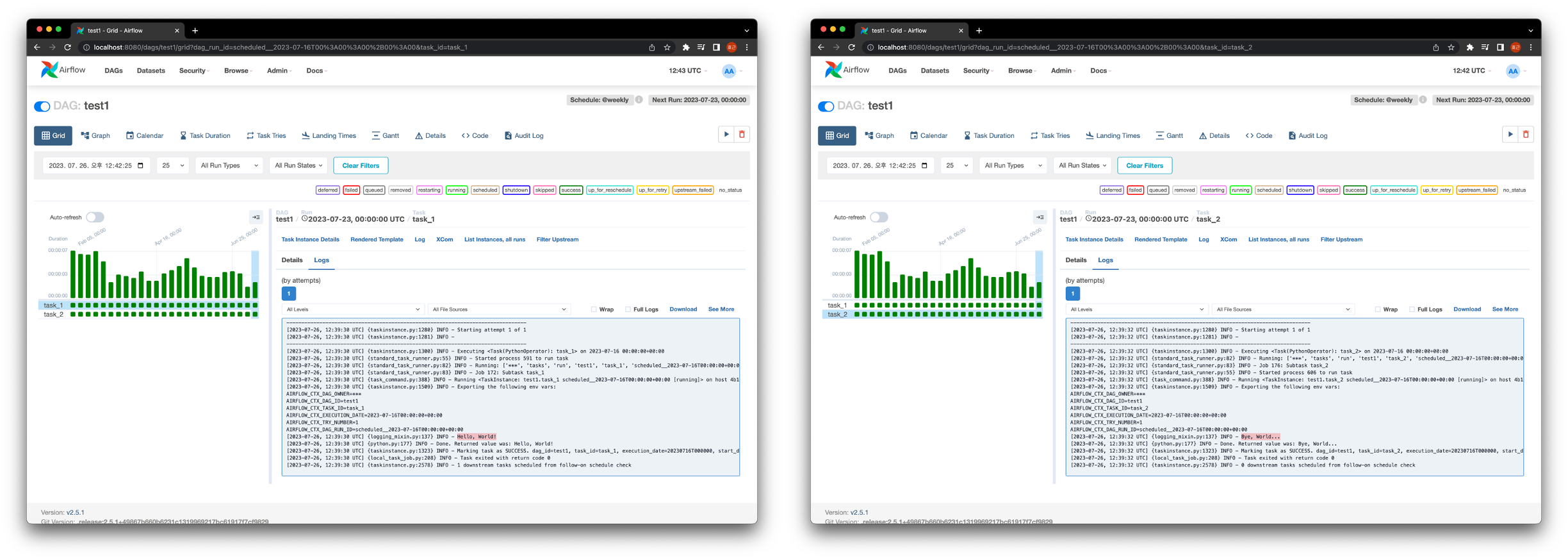
Airflow에서는 앞서 말한 것과 같이 매번 전체 데이터를 처리하지 않고 점진적으로 데이터를 처리하는데 이를 위해서 실행 시간을 참조해야한다.
이 실행 시간 (execution_date)은 실제 실행되는 시간이 아닌 데이터가 실제 처리되었다고 가정한 시점이다.
아래의 예시는 "10 * * * *"의 주기로 실행되는데, 실제 실행 시간인 Start Date와 End Date는 사진 기준의 현재 시간임을 알 수 있다.
하지만 Logical Date (execution_date, ts)는 Cron의 schedule 간격인 1시간 전으로 명시되어있음을 알 수 있다.
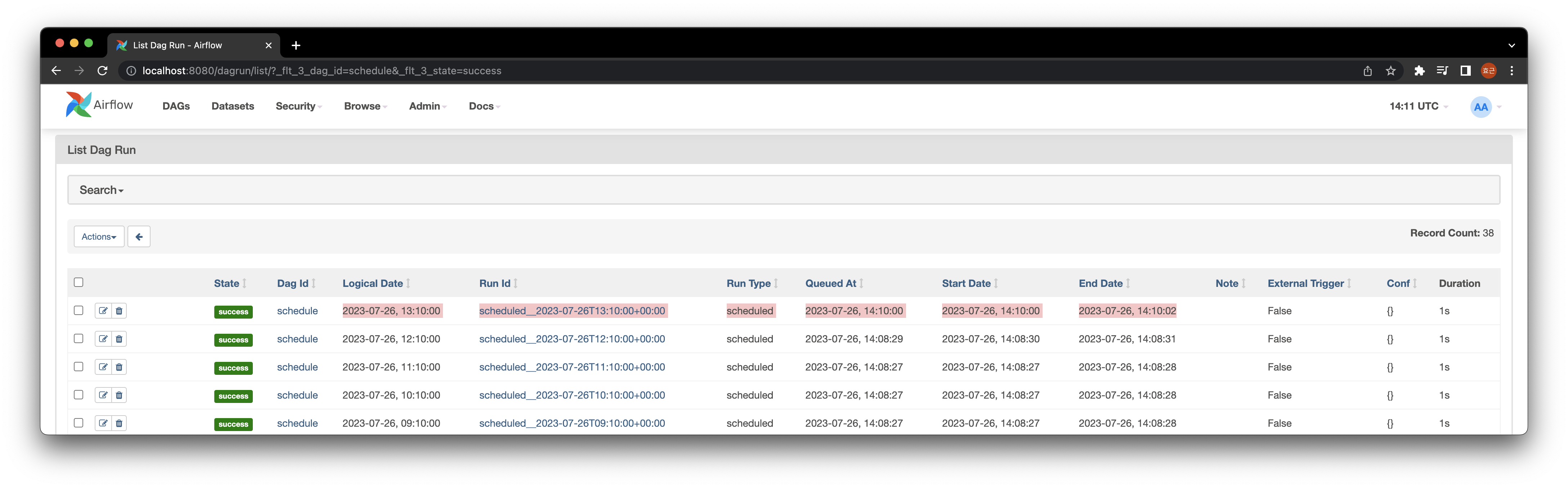
이것은 ts가 schedule 간격의 시작 시점을 의미하기 때문이다.
따라서 이 점을 유의하여 개발해야한다.